







大家好,大语言模型(LLMs)在AI领域的影响力与日俱增,广泛渗透到各类应用场景。但受硬件门槛和 API 成本制约,本地部署 LLMs 困难重重。谷歌新推出的 Gemma 3,为行业带来新希望。作为开源人工智能的新突破,Gemma 3 性能十分出色。它提供多种规模版本(10 亿、40 亿、120 亿和 270 亿参数),能满足不同硬件和性能需求。
在关键基准测试中,Gemma 3 与 DeepSeek-V3、OpenAI Mini 等热门模型展开激烈角逐。其具备多模态能力,能处理文本和图像;拥有 12.8 万的上下文窗口,处理长文档不在话下;还针对本地使用优化,在单 GPU 上就能运行。这些优势让它脱颖而出,有望成为开发者的新宠,为AI应用开发注入新活力。
1.Gemma 3概述
谷歌的Gemma 3是一款开源大语言模型(LLM),聚焦性能、效率与功能提升,为开发者带来全新体验。它有10亿、40亿、120亿和270亿参数等多种规模版本,开发者可以灵活按需选择。
-
多模态融合:能处理文本和图像,拓展应用边界。
-
超大窗口:12.8万上下文窗口,擅长处理长文档和深度推理。
-
灵活扩展:多种参数规模,适配不同场景和硬件。
-
本地优化:单GPU可运行,减少云依赖。
-
性能优越:在数学、编码和推理上超越同类模型。
-
语言广泛:支持140多种语言,通用性强。
-
自动化强:支持函数调用和结构化输出,便于集成。
2.Gemma 3 驱动的 PDF 摘要应用
谷歌 Gemma 3 大语言模型具有高达12.8万令牌的超大上下文窗口,这一特性在相关领域引发了极大关注。
为充分发挥其优势,一款专门研究论文处理的 PDF 摘要应用程序应运而生。该应用借助 Gemma 3(270 亿参数版本)、LangChain 和 Ollama,实现在本地对研究论文(https://arxiv.org/)进行下载、文本提取和摘要生成的全流程操作。
PDF摘要应用程序利用 Gemma 3 处理研究论文,先把论文切块,再据此生成结构化摘要。其核心组件如下:
-
用户输入与请求:用户在 Streamlit 前端输入 ArXiv PDF 的 URL,请求发至 FastAPI 后端,启动处理流程。
-
文本提取:FastAPI 后端接请求后下载 PDF,用 PyMuPDF(Fitz)提取文本。
-
文本分块:LangChain 的 RecursiveCharacterTextSplitter 将长文本切块。
-
摘要生成:分块文本送 Ollama,Gemma 3 并行处理生成摘要。
-
输出展示:Pydantic 整合摘要,在 Streamlit 界面展示并支持下载。
3.技术与工具
3.1 令牌
令牌是大语言模型处理文本的基本单位(可以是一个单词、单词的一部分,甚至一个字符也可以是一个令牌)。
例如,在英文文本里,大约 1000 个令牌对应 2000 个单词,也就是说平均 2 个单词会被视作 1 个令牌。像 “Artificial Intelligence is amazing!” 这句话,经模型处理后是 5 个令牌;而 “AI is great!” 则只有 3 个令牌。
模型一次能处理的令牌数量,直接决定了其单次处理信息量的多少。
3.2 上下文窗口
上下文窗口是指人工智能模型一次可以处理的最大令牌数。
以 Gemma 3 为例,它支持高达 12.8 万个令牌的上下文窗口。这一特性意义非凡,更大的上下文窗口让模型在处理长文本时,能够更好地维持记忆和连贯性。
就拿 PDF 摘要任务来说,大的上下文窗口可以帮助模型保留文档中的关键细节,避免丢失信息。像 2000 令牌的模型在处理长篇论文时,很可能会遗忘文档开头的内容;而 Gemma 3 这样 12.8 万令牌的模型,却能够轻松一次性处理整个章节或研究论文。
3.3 LangChain
LangChain 是一款在大语言模型应用构建领域极为强大的框架,深受广大开发者青睐。它提供了内存管理、链接、检索以及大文本数据处理等一系列实用工具 。
LangChain具有以下主要特性:
-
文本分块与分割:帮助将长篇文档分解为适合大语言模型处理的较小块。
-
内存管理:让模型在多次交互中记住上下文,使对话和任务处理更具连贯性。
-
检索增强生成(RAG):在生成响应之前获取相关信息。
-
多模型兼容性:可与OpenAI、Hugging Face、Ollama等多种模型一起使用。
在处理 PDF 文件时,常常会遇到模型输入令牌限制的问题,文件内容在分块和处理过程中容易被截断。而 LangChain 中的 RecursiveCharacterTextSplitter 工具,能够恰到好处地将文本分割成较小部分,确保在不丢失重要细节的前提下,实现高效处理。这也是在基于 Gemma 3 开发 PDF 摘要应用项目中,LangChain 成为不二之选的关键原因。
4.实施指南
下面逐步分解这个PDF提取和摘要应用程序。
4.1 设置环境
安装所需的库:
pip install fastapi uvicorn requests langchain pydantic pymupdf streamlit ollama httpx
-
FastAPI:用于构建后端API。
-
Uvicorn:ASGI服务器,用于运行FastAPI应用程序。
-
Requests:用于处理HTTP请求。
-
LangChain:用于管理文本处理以及与语言模型的交互。
-
Pydantic:用于FastAPI中的数据验证。
-
PyMuPDF:用于从PDF中提取文本。
-
Streamlit:用于创建前端用户界面。
-
Ollama:用于在本地运行Gemma 3模型(演示使用270亿参数版本)。
-
httpx:用于进行异步HTTP请求。
import os
import logging
import requests
import fitz
import asyncio
import json
import httpx
from concurrent.futures import ThreadPoolExecutor
from fastapi import FastAPI
from pydantic import BaseModel
from langchain.text_splitter import RecursiveCharacterTextSplitter
import ollama4.2 设置Ollama并下载Gemma3
Ollama有助于在本地运行语言模型,安装Ollama并下载Gemma 3模型:
# 安装Ollama
curl -fsSL https://ollama.ai/install.sh | sh
# 拉取Gemma 3模型
ollama pull gemma3:27b
默认情况下,Ollama 运行语言模型的令牌上下文窗口为2048,当推理时发送的令牌数大于此数值,提示便会被截断。而谷歌 Gemma 3 大语言模型拥有高达 12.8 万令牌的超大上下文窗口,为充分发挥其优势,本地部署基于 270 亿参数版本的 Gemma 3,结合硬件能力,从 gemma3:27b 派生了本地模型,将上下文窗口设置为 16000 个令牌 。这一调整旨在平衡硬件资源利用与模型处理长文本的需求,使得在本地环境下也能尽可能发挥 Gemma 3 处理长文档的潜力 。
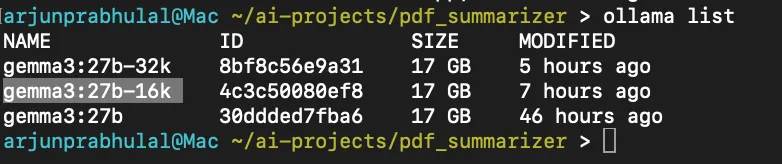
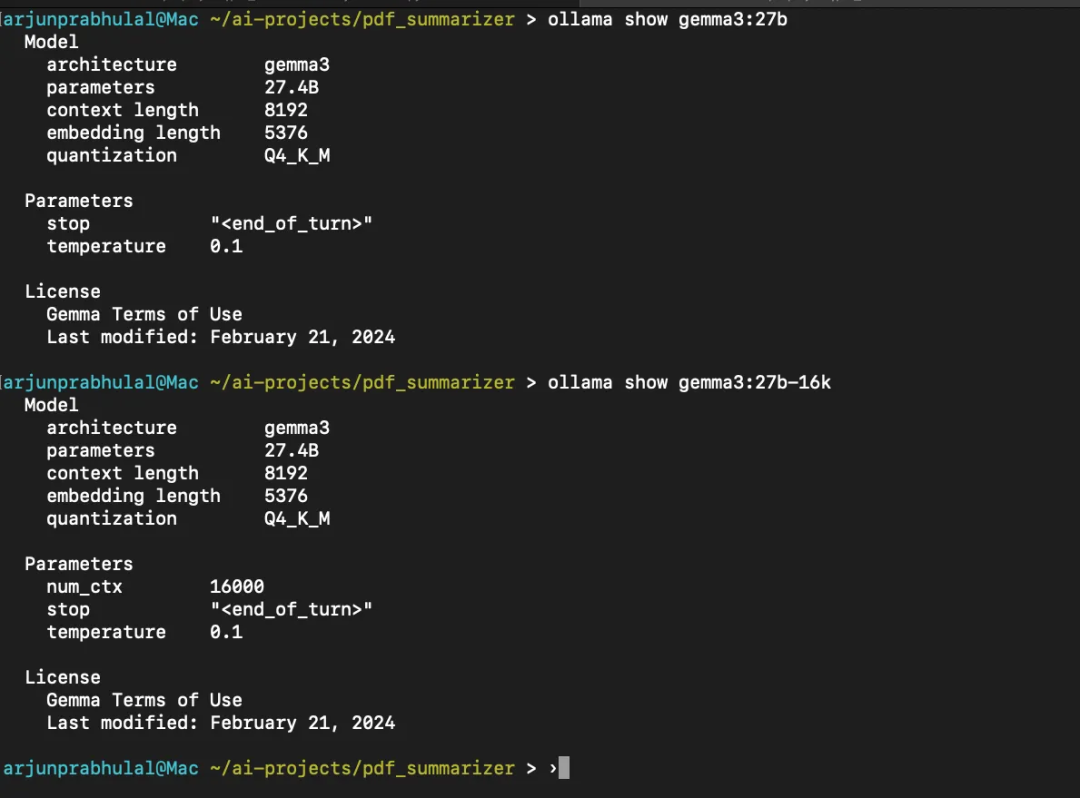
# 运行代码时,Ollama将以16000的上下文窗口运行
ollama serve

4.3 使用FastAPI搭建后端
创建一个带有健康检查端点和主要摘要端点的FastAPI应用程序:
app = FastAPI()
class URLRequest(BaseModel):
url: str
@app.get("/health")
def health_check():
return {"status": "ok", "message": "FastAPI backend is running!"}
@app.post("/summarize_arxiv/")
async def summarize_arxiv(request: URLRequest):
# 后续是具体实现细节
4.4 PDF下载和处理
应用程序从ArXiv下载PDF并使用PyMuPDF提取文本:
def download_pdf(url):
"""从给定的URL下载PDF并在本地保存。"""
try:
ifnot url.startswith("https://arxiv.org/pdf/"):
logger.error(f"Invalid URL: {url}")
returnNone# 防止下载非Arxiv的PDF
response = requests.get(url, timeout=30) # 设置超时以防止长时间等待
if response.status_code == 200and"application/pdf"in response.headers.get("Content-Type", ""):
pdf_filename = "arxiv_paper.pdf"
with open(pdf_filename, "wb") as f:
f.write(response.content)
return pdf_filename
else:
logger.error(f"Failed to download PDF: {response.status_code} (Not a valid PDF)")
returnNone
except requests.exceptions.RequestException as e:
logger.error(f"Error downloading PDF: {e}")
returnNone
PyMuPDF从下载的PDF中高效提取文本:
def extract_text_from_pdf(pdf_path):
"""使用PyMuPDF从PDF文件中提取文本。"""
doc = fitz.open(pdf_path)
text = "\n".join([page.get_text("text") for page in doc])
return text
4.5 使用LangChain进行文本分块
使用LangChain的RecursiveCharacterTextSplitter将文本分割成可管理的块:
"""Process text in chunks optimized for Gemma 3's 128K context window with full parallelism and retry logic."""
token_estimate = len(text) // 4
# 由于Gemma 3可以处理12.8万个令牌,所以使用更大的块
chunk_size = 10000 * 4 # 大约每个块4万个令牌
chunk_overlap = 100 # 更大的重叠以保持上下文
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", ". ", " ", ""]
)
chunks = splitter.split_text(text)
4.6 Gemma 3大语言模型与Ollama集成
使用异步HTTP请求与运行Gemma 3的Ollama进行通信,在那里每个块被摘要并合并:
async def summarize_chunk_wrapper(chunk, chunk_id, total_chunks):
"""使用Ollama异步包装单个块的摘要过程。"""
# 为大语言模型准备消息
messages = [
{"role": "system", "content": "Extract only technical details. No citations or references."},
{"role": "user", "content": f"Extract technical content: {chunk}"}
]
# 为Ollama API创建有效负载
payload = {
"model": "gemma3:27b-16k",
"messages": messages,
"stream": False
}
# 进行异步HTTP请求
asyncwith httpx.AsyncClient(timeout=3600) as client:
response = await client.post(
"http://localhost:11434/api/chat",
json=payload,
timeout=httpx.Timeout(connect=60, read=900, write=60, pool=60)
)
response_data = response.json()
summary = response_data['message']['content']
return summary
4.7 最后使用Gemma 3生成摘要
在处理完各个块后,生成最终的综合摘要:
# 使用系统消息创建最终摘要
final_messages = [
{
"role": "system",
"content": "You are a technical documentation writer. Focus ONLY on technical details, implementations, and results."
},
{
"role": "user",
"content": f"""Create a comprehensive technical document focusing ONLY on the implementation and results.
Structure the content into these sections:
1. System Architecture
2. Technical Implementation
3. Infrastructure & Setup
4. Performance Analysis
5. Optimization Techniques
Content to organize:
{combined_chunk_summaries}
"""
}
]
# 使用异步http客户端进行最终摘要并带有重试逻辑
asyncwith httpx.AsyncClient() as client:
response = await client.post(
"http://localhost:11434/api/chat",
json=payload,
timeout=httpx.Timeout(connect=60, read=3600, write=60, pool=60)
)
final_response = response.json()
4.8 运行FastAPI和Streamlit UI服务器
最后,运行FastAPI(后端)和Streamlit UI(前端)服务器:
if __name__ == "__main__":
import uvicorn
logger.info("Starting FastAPI server on http://localhost:8000")
uvicorn.run(app, host="0.0.0.0", port=8000, log_level="info")


4.9 最终演示
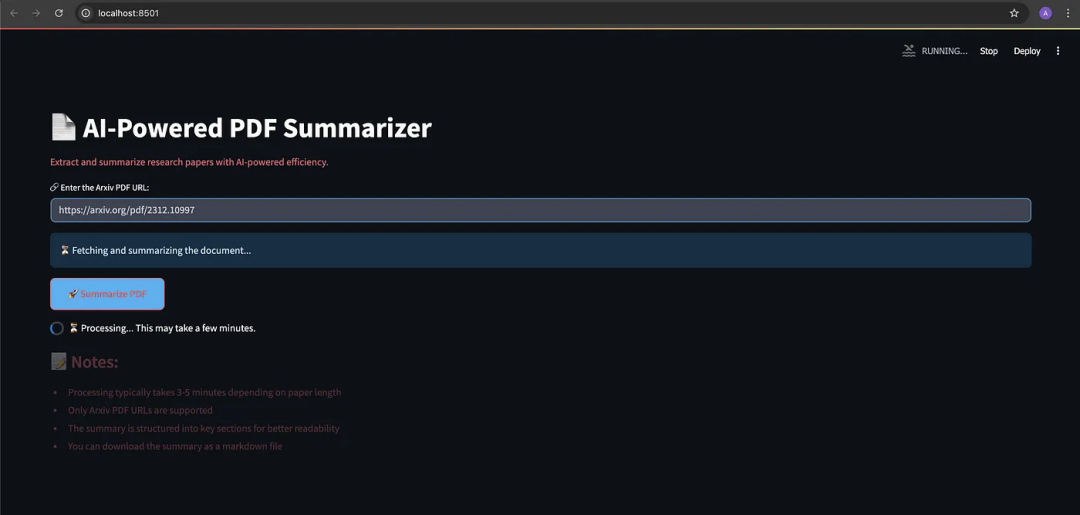
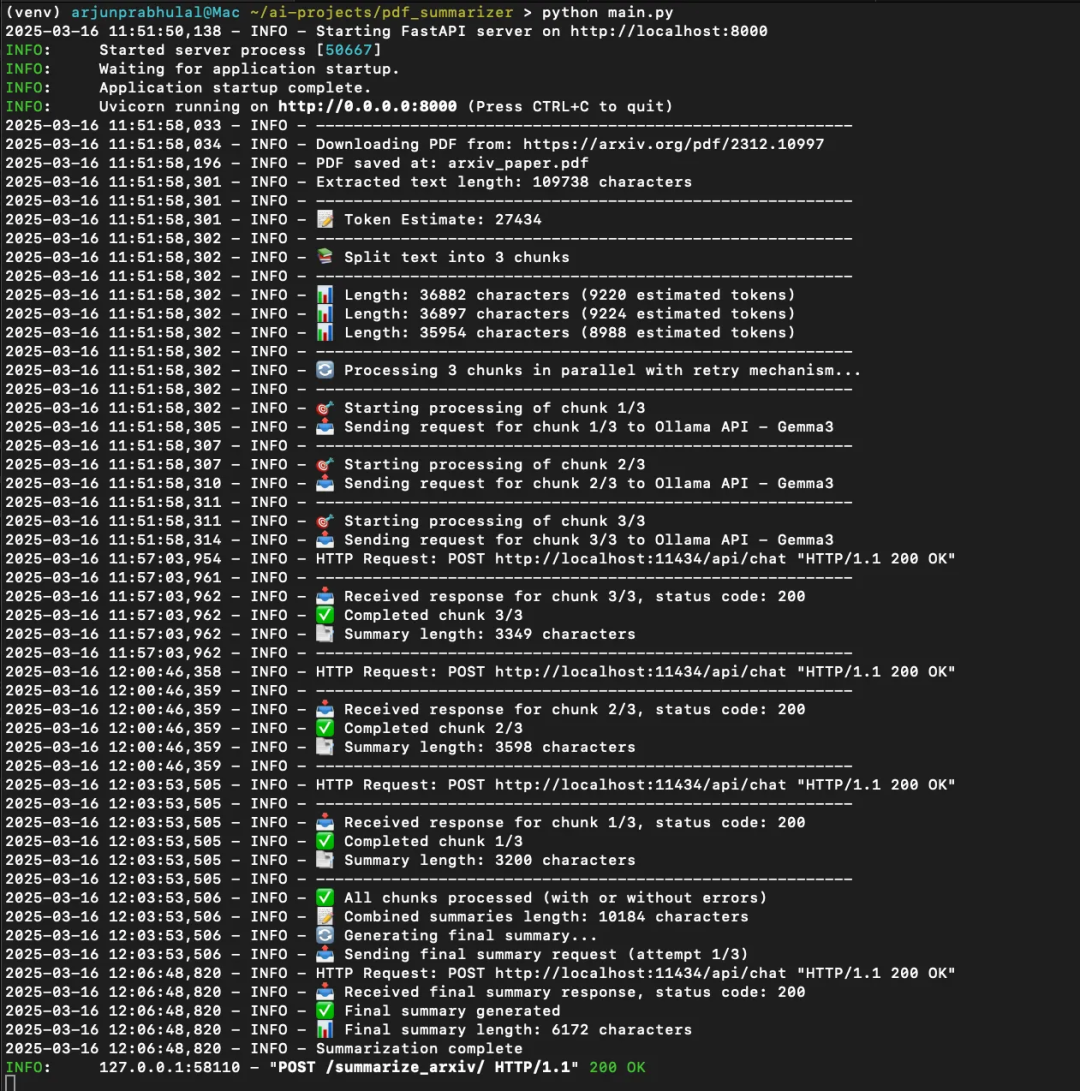
当用户输入任何研究论文的网址时,系统将根据提示摘要指令,在不丢失上下文信息的情况下,显示出连贯的摘要内容。
用户输入的arXiv网址:https://arxiv.org/pdf/2312.10997
来自后端日志(FastAPI)
来自前端(Streamlit用户界面)
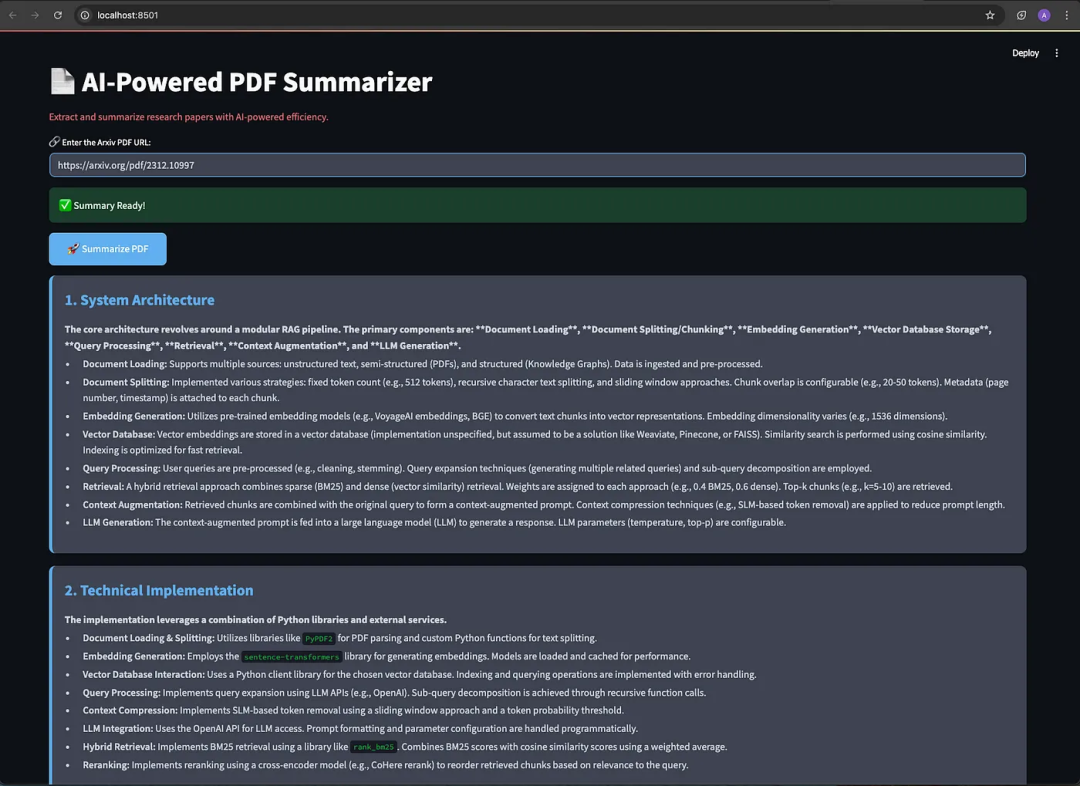
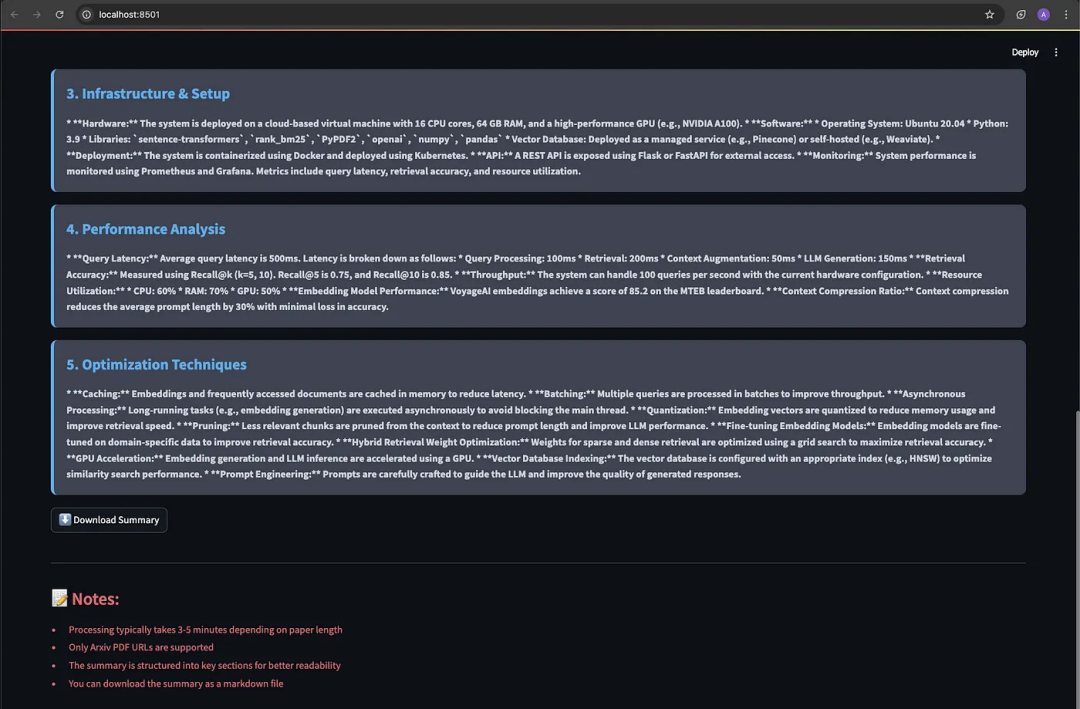
来自使用Gemma3大语言模型的Ollama服务日志




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











