










大家好,Meta公司新近推出的Llama 3.3 70B模型,为大型语言模型带来了新突破。这款模型不仅支持多语言,性能强劲,而且具备成本效益,有望彻底改变企业和科研人员利用AI的方式。本文带大家深入解析Llama 3.3 70B。
1.Meta Llama 3.3 70B 新亮点
Meta的Llama 3.3 70B模型在智能推理、编程编码和指令执行上做了大幅提升,是目前最前沿的开放模型之一。几大亮点如下:
-
精准输出:针对结构化数据,能生成条理清晰的推理过程和精确的JSON格式响应。
-
多语言兼容:支持八种主流语言,包括英语、法语、印地语和泰语,实现真正的多语言交流。
-
编程强化:对多种编程语言有更好的支持,错误处理更精细,代码反馈更详尽。
-
智能工具调用:根据预设参数,智能选择工具,避免不必要的操作。
这款模型让开发者以更低成本享受到接近405B模型的性能,让高端生成式AI技术触手可及。
2.性能与效率的新标杆
Llama 3.3 70B模型的性能媲美更大的Llama 3.1 405B模型,而成本却大大降低。
这意味着开发者和企业现在可以用更低的计算成本,获得行业领先的成果。这款模型以700亿参数实现了规模与易用的双赢,让更多人能够轻松使用。
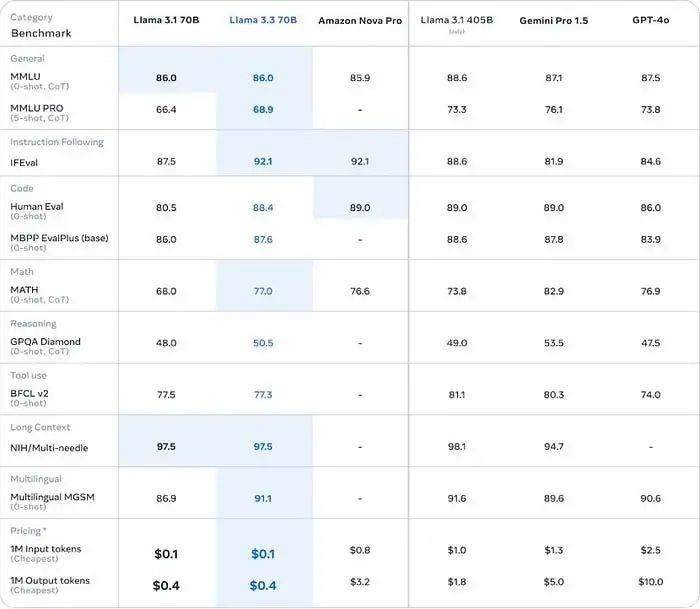
Llama3.3 70B 性能
Llama 3.3 70B性能:
-
更长的上下文窗口:该模型支持高达128k个标记,适合处理大规模文档、深入分析和复杂对话。
-
改进的结构化输出:能够生成逐步推理和精确的JSON输出,非常适合需要结构化数据的应用场景。
-
分组查询注意力(GQA):这一架构增强确保了推理的可扩展性和高效性,尤其适用于实时应用。
-
增强的编码支持:Llama 3.3在编码任务中表现优异,提供详细的错误处理、广泛的语言支持和结构化的代码反馈。
3.多语言支持
Llama 3.3是经过专业调优的多语言模型,能够流畅处理英语、法语、德语、意大利语、葡萄牙语、西班牙语、印地语和泰语等八种主要语言。
虽然此模型训练数据覆盖了更广的语言种类,但仍然鼓励开发者对未覆盖的语言进行微调,以保障对话的安全性和可靠性。
Llama 3.3的多语言支持为以下领域带来了新机遇:
-
教育领域:提供特定语言的辅导和资源。
-
全球客户服务:在企业环境中简化多语言沟通流程。
-
内容创作:实现多样化、文化敏感的内容创造。
Llama 3.3的一个突出特点是其增强的编码能力。开发者可以期待:
-
广泛的语言覆盖:模型支持广泛的编程语言,提供详细的错误检测和调试帮助。
-
任务感知工具使用:集成智能确保模型有效地调用外部工具,避免不必要的或冗余的调用。
这些特性使Llama 3.3成为软件开发的宝贵工具,赋予团队更高效地编写、调试和优化代码的能力。
4.集成Llama 3.3:最佳实践
为了最大化Llama 3.3的潜力,开发者和企业应遵循以下最佳实践:
-
明确用例:明确应用目标,以有效利用模型的优势。
-
实施安全措施:使用内置的安全特性,如Llama Guard 3,以最小化风险。
-
多语言微调:在处理不支持的语言时,应用微调以确保高质量的输出,符合模型的指南。
-
监控和优化:持续评估模型的性能,并针对特定任务优化其集成。
5.本地部署LLaMA 3.3 70B
了解LLaMA 3.3的技术亮点后,现在通过详细的步骤指南来学习如何使用LangChain和Ollama在本地计算机上运行LLaMA 3.3,按照以下步骤即可在终端上完成部署。
5.1 安装所需库
首先,在Python环境中安装所需的库。运行以下命令来设置LangChain和Ollama:
!pip install langchain
!pip install -U langchain-community
!pip install langchain_ollama
5.2 安装依赖项
运行以下单元格以安装必要的工具:
!sudo apt update
!sudo apt install -y pciutils
!curl -fsSL https://ollama.com/install.sh | sh
这个脚本将完成以下任务:
-
安装
pciutils用于GPU检测。 -
一键安装Ollama运行时。
5.3 启动Ollama服务
使用以下Python代码片段启动Ollama服务:
import threading
import subprocess
import time
def run_ollama_serve():
subprocess.Popen(["ollama", "serve"])
thread = threading.Thread(target=run_ollama_serve)
thread.start()
time.sleep(5)
这个设置在后台运行Ollama,支持你同时执行其他命令。
5.4 下载并运行模型
要加载特定模型(例如Llama 3.3),请执行:
!ollama pull llama3.3
可以在Ollama库(https://ollama.com/library)中探索更多模型。
5.5 将LLaMA 3.3与LangChain集成
LangChain可以轻松调用LLaMA 3.3进行各种NLP任务。这里是一个简单的脚本来测试模型:
from langchain_community.llms import Ollama
# 初始化Llama 3.3模型的实例
llm_llama = Ollama(model="llama3.3")
# 调用模型生成响应
response = llm_llama.invoke("Tell me a joke")
print(response)
输出:
Here's one:
What do you call a fake noodle?
An impasta.
5.6 尝试不同的任务
可以将其扩展到更复杂的任务,如摘要、多语言翻译和推理:
# 摘要
response = llm_llama.invoke("Summarize the following text: 'LLaMA 3.3 represents a major step forward in AI development...'")
print(response)
# 多语言生成
response = llm_llama.invoke("Translate the following into French: 'What are the major improvements in LLaMA 3.3?'")
print(response)
输出:
The translation of "What are the major improvements in LLaMA 3.3?" into French is:
"Quels sont les améliorations majeures de LLaMA 3.3?"
现在使用LangChain Ollama集成来提问或执行任务,进行数学查询:
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama.llms import OllamaLLM
from IPython.display import Markdown
# 定义提示模板
template = """Question: {question}
Answer: Let's think step by step."""
prompt = ChatPromptTemplate.from_template(template)
# 加载llama3.3模型
model = OllamaLLM(model="llama3.3")
# 结合提示和模型
chain = prompt | model
# 查询模型
response = chain.invoke({"question": "What is the square root of 2025?"})
display(Markdown(response))
输出:
The length of the hypotenuse in a right-angled triangle can be calculated using the Pythagorean theorem, which states that for a triangle with sides 'a' and 'b', and hypotenuse 'c': c^2 = a^2 + b^2.
However, I need more information to provide an accurate answer. Are you dealing with a specific right-angled triangle where both legs (a and b) are known? Please provide the lengths of sides 'a' and 'b', and I'll calculate the hypotenuse 'c'.
对该模型的性能进行测算,例如计算数字阶乘:
display(Markdown(chain.invoke({"question": "Write a python program to find a factorial of a number."})))
以下是Python函数,用于计算给定数字的阶乘:
```python
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
# 示例用法:
num = 5
print(f"The factorial of {num} is: {factorial(num)}")
这个函数通过递归计算阶乘。它首先检查输入n是否为0,如果是,则返回1(因为0的阶乘定义为1)。如果n不为0,则递归调用自身,传入n-1,并将结果乘以n。
在实际应用中,需要处理负数和非整数输入等边缘情况。此外对于较大的n值,由于Python对递归调用深度的限制,使用迭代方法可能更高效。
使用大模型进行机器学习分类的典型流程:
display(Markdown(chain.invoke({"question": "Write a Python code to run a simple classification algorithm using Sklearn."})))
首先需要导入必要的库,对于这个任务使用sklearn,它是Python中广泛用于机器学习任务的库。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 第一步:加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 第二步:将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 第三步:数据预处理(缩放通常对逻辑回归是必要的)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 第四步:训练逻辑回归模型
logreg = LogisticRegression(solver='liblinear')
logreg.fit(X_train_scaled, y_train)
# 第五步:做出预测并评估模型
y_pred = logreg.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy of the model: {accuracy*100:.2f}%')
这个脚本展示了使用Python和Sklearn进行机器学习分类的典型流程。它包括加载数据集、数据划分、特征缩放、模型训练和评估等步骤。在实际应用中,你可能需要根据数据集的特点调整预处理步骤,并探索不同的模型以适应不同的分类问题。
Meta的Llama 3.3 70B模型,以其多语言能力、高效推理和安全特性,为大型语言模型树立新标杆。它不仅服务于研究者,也助力企业构建AI解决方案,平衡了强大性能与易用性。Llama 3.3的推出,展现了Meta推动包容性AI未来的承诺,让高质量AI技术更加普及。


















 64
64

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











