







 本文深入探讨了概率语言模型PLSA及其参数估计方法EM算法。PLSA通过概率图模型解决隐含语义分析问题,而EM算法用于估计模型参数。内容涵盖了LSA的SVD基础、PLSA模型的构建、EM算法的E步骤和M步骤,以及如何用EM算法估计混合unigram语言模型和GMM的参数。此外,还介绍了EM算法的一般形式和在数据挖掘、NLP中的重要性。
本文深入探讨了概率语言模型PLSA及其参数估计方法EM算法。PLSA通过概率图模型解决隐含语义分析问题,而EM算法用于估计模型参数。内容涵盖了LSA的SVD基础、PLSA模型的构建、EM算法的E步骤和M步骤,以及如何用EM算法估计混合unigram语言模型和GMM的参数。此外,还介绍了EM算法的一般形式和在数据挖掘、NLP中的重要性。
本系列博文介绍常见概率语言模型及其变形模型,主要总结PLSA、LDA及LDA的变形模型及参数Inference方法。初步计划内容如下
第一篇:PLSA及EM算法
第三篇:LDA变形模型-Twitter LDA,TimeUserLDA,ATM,Labeled-LDA,MaxEnt-LDA等
第四篇:基于变形LDA的paper分类总结
第一篇 PLSA及EM算法
[本文PDF版本下载地址 PLSA及EM算法-yangliuy]
前言:本文主要介绍PLSA及EM算法,首先给出LSA(隐性语义分析)的早期方法SVD,然后引入基于概率的PLSA模型,其参数学习采用EM算法。接着我们分析如何运用EM算法估计一个简单的mixture unigram 语言模型和混合高斯模型GMM的参数,最后总结EM算法的一般形式及运用关键点。对于改进PLSA,引入hyperparameter的LDA模型及其Gibbs Sampling参数估计方法放在本系列后面的文章LDA及Gibbs Samping介绍。
1 LSA and SVD
LSA(隐性语义分析)的目的是要从文本中发现隐含的语义维度-即“Topic”或者“Concept”。我们知道,在文档的空间向量模型(VSM)中,文档被表示成由特征词出现概率组成的多维向量,这种方法的好处是可以将query和文档转化成同一空间下的向量计算相似度,可以对不同词项赋予不同的权重,在文本检索、分类、聚类问题中都得到了广泛应用,在基于贝叶斯算法及KNN算法的newsgroup18828文本分类器的JAVA实现和基于Kmeans算法、MBSAS算法及DBSCAN算法的newsgroup18828文本聚类器的JAVA实现系列文章中的分类聚类算法大多都是采用向量空间模型。然而,向量空间模型没有能力处理一词多义和一义多词问题,例如同义词也分别被表示成独立的一维,计算向量的余弦相似度时会低估用户期望的相似度;而某个词项有多个词义时,始终对应同一维度,因此计算的结果会高估用户期望的相似度。
LSA方法的引入就可以减轻类似的问题。基于SVD分解,我们可以构造一个原始向量矩阵的一个低秩逼近矩阵,具体的做法是将词项文档矩阵做SVD分解
其中是以词项(terms)为行, 文档(documents)为列做一个大矩阵. 设一共有t行d列, 矩阵的元素为词项的tf-idf值。然后把
的r个对角元素的前k个保留(最大的k个保留), 后面最小的r-k个奇异值置0, 得到
;最后计算一个近似的分解矩阵
则在最小二乘意义下是
的最佳逼近。由于
最多包含k个非零元素,所以
的秩不超过k。通过在SVD分解近似,我们将原始的向量转化成一个低维隐含语义空间中,起到了特征降维的作用。每个奇异值对应的是每个“语义”维度的权重,将不太重要的权重置为0,只保留最重要的维度信息,去掉一些信息“nosie”,因而可以得到文档的一种更优表示形式。将SVD分解降维应用到文档聚类的JAVA实现可参见此文。
IIR中给出的一个SVD降维的实例如下:


左边是原始矩阵的SVD分解,右边是只保留权重最大2维,将原始矩阵降到2维后的情况。
2 PLSA
尽管基于SVD的LSA取得了一定的成功,但是其缺乏严谨的数理统计基础,而且SVD分解非常耗时。Hofmann在SIGIR'99上提出了基于概率统计的PLSA模型,并且用EM算法学习模型参数。PLSA的概率图模型如下

其中D代表文档,Z代表隐含类别或者主题,W为观察到的单词,表示单词出现在文档
的概率,
表示文档
中出现主题
下的单词的概率,
给定主题
出现单词
的概率。并且每个主题在所有词项上服从Multinomial 分布,每个文档在所有主题上服从Multinomial 分布。整个文档的生成过程是这样的:
(1) 以的概率选中文档
;
(2) 以的概率选中主题
;
(3) 以的概率产生一个单词。
我们可以观察到的数据就是对,而
是隐含变量。
的联合分布为

而和
分布对应了两组Multinomial 分布,我们需要估计这两组分布的参数。下面给出用EM算法估计PLSA参数的详细推导过程。
3 Estimate parameters in PLSA by EM
(注:本部分主要参考Tomas Hoffman, Unsupervised Learning by Probabilistic Latent Semantic Analysis.)
如文本语言模型的参数估计-最大似然估计、MAP及贝叶斯估计一文所述,常用的参数估计方法有MLE、MAP、贝叶斯估计等等。但是在PLSA中,如果我们试图直接用MLE来估计参数,就会得到似然函数
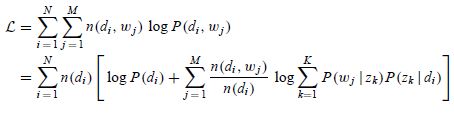
其中是term
出现在文档
中的次数。注意这是一个关于
和
的函数,一共有N*K + M*K个自变量(注意这里M表示term的总数,一般文献习惯用V表示),如果直接对这些自变量求偏导数,我们会发现由于自变量包含在对数和中,这个方程的求解很困难。因此对于这样的包含“隐含变量”或者“缺失数据”的概率模型参数估计问题,我们采用EM算法。
EM算法的步骤是:
(1)E步骤:求隐含变量Given当前估计的参
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









