







 本文详细介绍了如何使用Hive进行数据导入,包括使用load命令和sqoop组件从Oracle导入数据到Hive,并展示了简单的查询操作,如fetch task功能、数学函数以及表连接。同时,还探讨了Hive的JDBC客户端在操作中的应用。
本文详细介绍了如何使用Hive进行数据导入,包括使用load命令和sqoop组件从Oracle导入数据到Hive,并展示了简单的查询操作,如fetch task功能、数学函数以及表连接。同时,还探讨了Hive的JDBC客户端在操作中的应用。
Hive数据导入—load命令/sqoop组件
load:
| lOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcoll=val1, partool2=val2 …)] --导入本地文件系统的文件 load data local inpath ‘/root/data/stu01.txt’ into table t2; load data local inpath ‘root/data/’ overwrite into table t2; --导入hdfs中的文件: load data inpath ‘/input/stu01.txt’ overwrite into table t2; --导入分区表 load data local inpath ‘/input/data01.txt’ into table partition_tab partition (gender=’M’); load data local inpath ‘/root/data02.txt’ into table partition_tab partition (gender=’F’); |
批量数据导入导出:sqoop:http://sqoop.apache.org
| tar –zxvf sqoop-1.4.5.bin_hadoop-0.23.tar.gz 设置环境变量: export HADOOP_COMMON_HOME=~/training/hadoop-2.4.1/ --指明Hadoop的安装目录 export HADOOP_MAPRED_HOME=~/training/hadoop-2.4.1/ ---指明Mapreduce的家目录,使sqoop将作业转换为Mapreduce 使用sqoop-1.4.5.bin_hadoop-0.23/bin/sqoop关键字进行数据的导入和导出: Sqoop是基于jdbc的。 将oracle的驱动ojdbc14.jar导入到sqoop-1.4.5.bin_hadoop-0.23/lib中 1. 使用sqoop导入Oracle数据到HDFS中: ./sqoop import --connect jdbc:oracle:thin:@192.168.56.101:1521:orcl --username zq --password zq123 --table emp --columns ‘empno,ename,job,sal,deptno’ -m 1 --target-dir ‘/sqoop/emp’ -m 开启的mapreduce进程数。 2. 使用sqoop导入Oracle数据到hive中: |
./sqoop import --hive-import --connectjdbc:oracle:thin:@192.168.56.101:1521:orcl --username zq --password zq123--table emp –m 1 --columns ‘empno,ename,sal’
3. 使用sqoop导入oracle数据到hive中,并指定表名
./sqoop import--hive-import --connect jdbc:oracle:thin:@192.168.56.101:1521:orcl --usernamezq --password zq123 --table emp –m 1 --columns ‘empno,ename,sal’--hive-tableemp
4. 使用sqoop导入oracle数据到hive中,并使用where条件
./sqoop import--hive-import --connect jdbc:oracle:thin:@192.168.56.101:1521:orcl --usernamezq --password zq123 --table emp –m 1 --columns ‘empno,ename,job,sal,deptno’--hive-table emp2 --where ‘deptno=10’
5. 使用sqoop导入oracle数据到hive中,并使用查询语句
./sqoop import--hive-import --connect jdbc:oracle:thin:@192.168.56.101:1521:orcl --usernamezq --password zq123 –m 1--query ‘select * from empwhere sal<2000 and $conditions ’ --target-dir ‘/sqoop/emp5’--hive-tableemp5 ---有query查询语句,则必须指定表存储路径
6. 使用sqoop导出hive数据仓库数据到oracle中:
./sqoop export --connectjdbc:oracle:thin:@192.168.56.101:1521:orcl --username zq --password zq123 –m 1--table myemp –export-dir ‘/root/data’
--要确保oracle的myemp表存在,并且属性和hive中的表属性一致 ???

简单查询和fetchtask
简单查询:
| SELECT [ALL|DISTINCT] select_expr,selec_expr,… FROM table_refrence [WHERE where_condition] [GROUP BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list]] [SORT BY col_list] | [ORDER BY col_list] [LIMIT number] DISTRIBUTE BY 指定分发器 (Partitioner),多Reducer可用 查询员工的所有信息 select * from emp; 查询员工信息:select empno,ename,sal from emp; 查询员工的信息:empno,ename,sal,sal*12,comm.,sal*12+nvl(comm,0) from emp; 查询奖金为空的员工信息:select * from emp where comm is null; 查询员工号信息(不重复):select distinct empno from emp; |
Fetch Task功能:从Hive0.10.0版本开始
配置方式:
hive> set hive.fetch.task.conversion=more;
hive --hiveconfhive.fetch.task.conversion=more
修改hive-site.xml文件,永久生效
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
</property>
在hive仓库中使用过滤和排序:
| --查询10号部门的员工信息 select * from emp where deptno=10; 查询名为KING的员工信息: select * from emp where ename=’KING’; --区分大小写 查询部门号是10,薪水小于2000的员工: select * from emp where empno=10 and sal<2000; ---使用explain查看说明 模糊查询:名字以s大头的员工信息 select * from emp where ename like ’s%’; 查询名字中含有下划线的员工信息: select * from emp where ename like ‘%\\_%’; 排序:使用Mapreduce作业执行: select empno,ename,sal frpm emp order by sal [desc]; order by +列,表达式,别名,序号 select empno,ename,sal,sal*12 from emp order by sal*12; select empno,ename,sal,sal*12 sals from emp order by sals; hive> set hive.groupby.orderby.position.alias=true; ---设置可通过序列号进行排序操作 select empno,ename,sal,sal*12 from emp order by 4; 包含null的列在升序排列中默认被排在前面,降序被排在最后面,一般将控制转变为0或其他有意义的词语代替null |
hive数学函数:
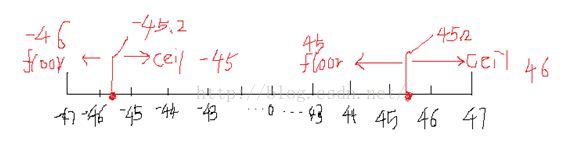
| 1. 内置函数 round:四舍五入 select round(45.925,2); ceil向上取整: select ceil(45.9),ceil(45.3); --46 floor向下取整: select floor(45.6),floor(45.2);
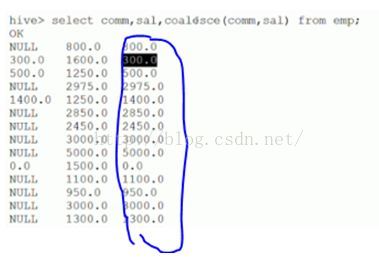
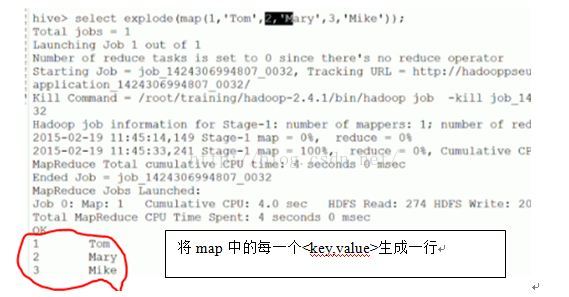
字符函数: lower,upper,length,concat,substr,trim,lpad,rpad select lower(‘HELLO’),upper(‘hello’); select length(‘hello’),concat(‘a’,’b’,’c’),concat(‘n’,4+2); select length(‘你好’) ; --在hive中为2 select length(‘你好’) from dual; --在mysql中为4,在oracle中为2 select substr(‘hello’,1); ---起始点由1开始计算 select substr(‘hello’,2,3);--ell,3指截取长度 select length(trim(‘ hello ’)); --5 select lpad(‘a’,3,’c’); --左填充 select rpad(‘a’,3,’c’); --右填充 收集函数和转换函数: size 统计map集合的个数:size(map(<key,value>,<key,value>)) select size(map(1,’Tom’,2,’Mary’)); ---2 cast转换函数 select cast(1 as bigint),cast(1 as float) ; select cast(‘2016-07-13’ as date); --2016-07-13’ 日期函数: to_date,year,month,day,weekofyear,datediff,date_add,date_sub select to_date(‘2016-07-13 17:01:24’); --2016-07-13’ select year(‘2016-07-13 17:01:24’),month(‘2016-07-13 17:01:24’),day(‘2016-07-13 17:01:24’); select weekofyear(‘2015-09-14 12:23:13’); --返回该日期在一年中是第几个星期,38 select datediff(‘2015-02-12’,now()); --返回两个日期相差的天数,前面-后面= -517 select date_add(‘2015-05-10’,30); --在该日期之上增加30天 select date_add(‘2015-05-10’,interval 30 year/month/day) ---mysql语法 条件函数: coalesce:从左到右返回第一个不为null的值
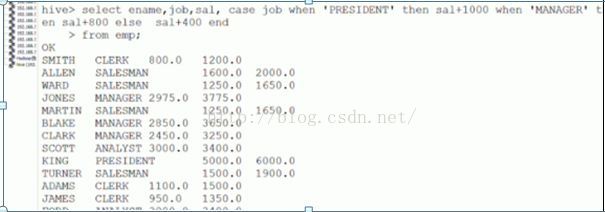
cast…when … 条件表达式 ---可实现ifelse语句 语法格式: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
聚合函数和表生成函数: count,sum,min,max,avg –-聚合函数,转换为Mapreduce作业 explode --表生成函数,可以将map集合或数组的每个元素单独生成行
2. 自定义函数 首先创建一个类,该类继承org.apache.hadoop.hive.ql.UDF,重写evaluate方法[evaluate支持重载];public Text evaluate(Text a,Text b){} 然后将程序打包放到目标机器上(hive服务器); 进入hive客户端,添加jar包:hive> add jar /root/traing/udfjar/udf_test.jar 创建临时函数:hive>create temporary function <函数名> as ‘包全名.jave类名’;
使用该函数:select 函数名 from tablename; 销毁临时函数:drop temporary function 函数名;
|
Hive的表连接:
等值连接[=],不等值连接[between and] ---mapreduce
| 查询员工信息:empno,ename,sal,d.depno select e.empno,e.ename,e.sal,d.depno from emp e,dept d where e.deptno=d.deptno; |
外连接:可以将对于连接条件不成立的记录包含在最后的结果中。分为左外连接和右外连接
| 查询员工信息:部门号,部门,员工总数 select d.depno,d.dname,count(e.empno) from emp e,dept d where e.deptno=d.deptno group by d.deptno,d.dname; --hql语句中select没有包含聚合函数的列都要写在group by之后 左外连接:连接条件左边的表会包含在左边,left outer join on 左外连接是将左表作为主表,右表作为从表,结果集中全部显示主表(左表)的信息。 右外连接:连接条件右边的表会包含在右边,right outer join on 右外连接是将右表作为主表,左表作为从表,结果集中全部显示主表(右表)的信息。 select d.depno,d.dname,count(e.empno) from emp e right outer join dept d on (e.deptno=d.deptno) group by d.deptno,d.dname; |
内连接:自连接,通过表的别名将同一张表视为多张表
| 查询员工姓名和员工老板姓名 select e.ename,b.ename from emp e,emp b where e.mgr=b.empno; |
Hive子查询:只支持from和where的子查询
| select e.ename from emp e where e.deptno in (select d.deptno from dept d where d.dname=’SALES’ or d.dname=’ACCOURING’); --where后一对多 空值问题null: select * from emp e where e.empno not in (select e1.mgr from emp e1 where e1.mgr is not null); |
Hive的JDBC客户端操作:
| # hive –service hiveserver --启动服务器 Jdbc程序访问:eclipse—java工程—添加hive驱动jar包[hive-jdbc-0.13.0.jar]及其他相关的hive包:[$HIVE_HOME/lib/] 步骤: driver = “org.apache.hadoop.hive.jdbc.HiveDriver”; url = “jdbc:hive://192.168.56.31:10000/default”; 1. 获取连接
2. 创建运行环境 Statement stat = conn.createStatement(); 3. 执行HQL ResultSet rs = stat.executeQuery(“select * from emp”); 4. 处理结果集 while(rs.next()) { String name = rs.getString(2); double sal = rs.getDouble(6); System.out.println(name+”\t”+sal); } 5. 释放资源
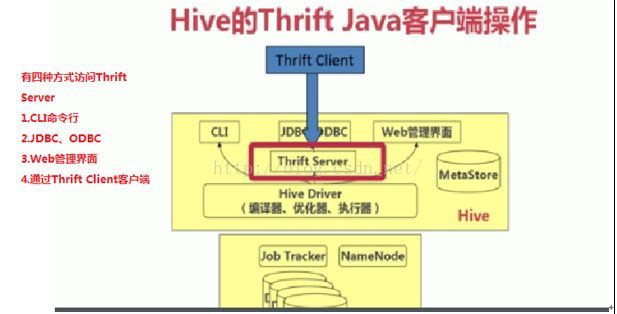
Thrift Client 访问
步骤: 1. 创建Socket服务器连接 final TSocket tSocket = new TSocket(“192.168.56.22”,10000); 2. 创建协议 final TProtocal tProtcal = new TBinaryProtocol(tSocket); 3. 创建Hive Client final HiveClient client = new HiveClient(tProtcal); 4. 打开Socket tSocket.open(); 5. 执行HQL语句 client.execute(“desc emp”); ----hql语句 6. 处理结果集 List<String> columns = client.fetchAll(); for(String col:columns) { System.out.println(col); } 7. 关闭服务器 tSocket.close(); |
Hive采用元数据对表进行管理。元数据的存储方式为嵌入模式,本地模式和远程模式















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









