







文章目录
0 概述
前5周我们学习了线性回归,逻辑回归,神经网络来训练数据得到预测模型。但是如何评价预测模型的优劣,如何对预测模型进行误差分析以及如何改进,这是实际应用中所关注的。
本周,将要针对模型的评估,优化改进进行学习,旨在对模型进行进一步完善做出明确的指导。
1. 课程大纲

2. 课程内容
2.1 模型的选择和评估
之前,我们的训练数据全部用于训练模型,但是为了做模型选择和评估,需要将训练数据分为三份,训练集,验证集,测试集,他们的作用如下:
训练集,用来训练多种模型,对应计算训练误差
J
rrain
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J_{\text { rrain}}(\theta)=\frac{1}{2 m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right)^{2}
J rrain(θ)=2m1∑i=1m(hθ(x(i))−y(i))2
验证集,在多种模型中选择最好的,对应计算验证误差
J
c
v
(
θ
)
=
1
2
m
c
v
∑
i
=
1
m
c
v
(
h
θ
(
x
c
v
(
n
)
−
y
c
v
[
i
)
)
2
J_{c v}(\theta)=\frac{1}{2 m_{c v}} \sum_{i=1}^{m_{c v}}\left(h_{\theta}\left(x_{c v}^{(n)}-y_{c v}^{[i)}\right)^{2}\right.
Jcv(θ)=2mcv1∑i=1mcv(hθ(xcv(n)−ycv[i))2
测试集,评估选出来的模型的性能,对应计算测试误差
J
test
(
θ
)
=
1
2
m
test
∑
i
=
1
m
test
(
h
θ
(
x
test
(
i
)
)
−
y
test
(
i
)
)
2
J_{\text {test}}(\theta)=\frac{1}{2 m_{\text {test}}} \sum_{i=1}^{m_{\text {test}}}\left(h_{\theta}\left(x_{\text {test}}^{(i)}\right)-y_{\text {test}}^{(i)}\right)^{2}
Jtest(θ)=2mtest1∑i=1mtest(hθ(xtest(i))−ytest(i))2
每组训练集,用于计算误差的函数是完全相同的,但是其代表意义并不相同。
可以大致理解训练模型的步骤:
Step 1:用训练集训练各种模型,线性的,多项式的,有正则化的,无正则化的,追求训练误差的最小化。
Step 2:用验证集,去计算训练出来的模型的验证误差。并选出表现最好的一个作为最终模型。验证集,还可以在训练过程中指导优化方向。
Step 3:用测试集,评估最终模型的表现优劣。
2.2 误差分析及模型优化
评价模型,一般评价其偏差和方差,偏差反映了模型无法正确的描述数据规律,导致预测误差很大;方差反映了模型对训练数据过度敏感,导致了其泛华能力很差。
2.2.1 多项式次数与偏差和方差
如图所示,是多项式次数与验证误差和训练误差的关系图。

可以看到,
当多项式次数很小时,比如一条直线很难对数据进行拟合,因此偏差很大,
J
train
(
θ
)
J_{\text {train}}(\theta)
Jtrain(θ)和
J
c
v
(
θ
)
J_{c v}(\theta)
Jcv(θ)都很大,这时处于欠拟合状态。
当多项式次数很大合适的时候,
J
train
(
θ
)
J_{\text {train}}(\theta)
Jtrain(θ)由于对训练数据拟合很好,因此会越来越小,
J
c
v
(
θ
)
J_{c v}(\theta)
Jcv(θ)由于模型过度敏感导致越来越大,方差很大,这时处于过拟合状态。
因此,选择
J
c
v
(
θ
)
J_{c v}(\theta)
Jcv(θ)最低的那个点,才是最佳多项式次数。
2.2.2 正则化项与偏差和方差
如下图所示,是正则项
λ
\lambda
λ的大小与
J
train
(
θ
)
J_{\text {train}}(\theta)
Jtrain(θ)和
J
c
v
(
θ
)
J_{c v}(\theta)
Jcv(θ)的关系图。

可以看到这张图的趋势和多项式次数很像,就是正好反过来了。诚然,其描述也是类似的。
当
λ
\lambda
λ 很大的时候,就会使得后面的每一个
θ
i
\theta_i
θi 都被惩罚了,所以只剩下
θ
0
\theta_0
θ0 ,那么其假设函数就会变成一条直线,出现欠拟合的现象。
当
λ
\lambda
λ 很小的话,一个极端例子就是
λ
=
0
\lambda=0
λ=0 ,也就是相当于没有加正则化那项,这就会导致过拟合的现象。
因此,
λ
\lambda
λ的取值不能过大也不能过小,取在
J
c
v
(
θ
)
J_{c v}(\theta)
Jcv(θ)最低的那个点。
一般正则化项选择的方法:
- λ \lambda λ在 [ 0 , 0.01 , 0.02 , 0.04 , 0.08 , 0.16 , 0.32 , 0.64 , 1.28 , 2.56 , 5.12 , 10.24 ] \left[0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24\right] [0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24]依次尝试,在12个不同的模型中针对每一个 λ \lambda λ 的值,都去计算出一个最小代价函数,从而得到 Θ ( i ) \Theta^{(i)} Θ(i)
- 得到了12个 Θ ( i ) \Theta^{(i)} Θ(i) 以后,就再用交叉验证集去评价它们。即计算每个 Θ \Theta Θ 在交叉验证集上的平均误差平方和 J c v ( Θ ( i ) ) J_{cv}(\Theta^{(i)}) Jcv(Θ(i))
- 选择一个交叉验证集误差最小的 λ \lambda λ 最能拟合数据的作为正则化参数。
- 拿这个正则化参数去测试集里面验证 J t e s t ( Θ ( i ) ) J_{test}(\Theta^{(i)}) Jtest(Θ(i)) 预测效果如何。
总结一下,2.2.1和2.2.2两小节有一个一致的特征可以表示模型属于欠拟合还是过拟合。
高偏差(欠拟合):
{
J
train
(
θ
)
,
J
c
v
(
θ
)
is high
J
c
v
(
θ
)
≈
J
test
(
θ
)
\left\{\begin{array}{c}{J_{\text {train}}(\theta), J_{c v}(\theta) \quad \text { is high }} \\ {J_{c v}(\theta) \approx J_{\text {test}}(\theta)}\end{array}\right.
{Jtrain(θ),Jcv(θ) is high Jcv(θ)≈Jtest(θ)
高方差(过拟合): { J train ( θ ) is low J c v ( θ ) > > J t e s t ( θ ) \left\{\begin{array}{l}{J_{\operatorname{train}}(\theta) \text { is } \operatorname{low}} \\ {J_{c v}(\theta)>>J_{t e s t}(\theta)}\end{array}\right. {Jtrain(θ) is lowJcv(θ)>>Jtest(θ)
2.2.3 学习曲线
学习曲线,是一条随着训练样本数增加,
J
train
(
θ
)
J_{\text {train}}(\theta)
Jtrain(θ)和
J
c
v
(
θ
)
J_{c v}(\theta)
Jcv(θ)变化图。
当模型处于一个比较好的状态,其图形应当如下:

J
train
(
θ
)
J_{\text {train}}(\theta)
Jtrain(θ)会缓慢上升,
J
c
v
(
θ
)
J_{c v}(\theta)
Jcv(θ)随着模型不断精确,会缓慢下降,两者趋向的误差都不会高(不是高偏差情况)。
如果模型属于欠拟合状态时,学习曲线:

当数据存在高偏差也就是欠拟合的时候,即使数据再继续增多也无补于事,所以其误差会趋于一个平衡的位置,而且
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ) 和
J
c
v
(
θ
)
J_{cv}(\theta)
Jcv(θ) 的误差都会很大。
所以,当数据存在欠拟合的问题,我们选用更多的训练样本是没有办法解决问题的。
当模型处于过拟合状态时,学习曲线:

当数据存在高方差也就是过拟合的时候,随着数据的增多,因为过拟合所以在训练集基本能完美拟合其数据,所以训练集的误差虽然会上升,但是其幅度是非常缓慢的,在交叉验证集也一样,所以过拟合的时候其图像如上,在
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ) 和
J
c
v
(
θ
)
J_{cv}(\theta)
Jcv(θ) 之间有一大段空隙。
所以,当数据存在过拟合的现象,选用更多的样本有利于我们解决这个问题。
2.2.4 优化方向
对于不同优化手段,适用于不同的情况,如下图所示:

应用机器学习,千万不要一上来就试图做到完美,先撸一个baseline的model出来,再进行后续的分析步骤,一步步提高,所谓后续步骤可能包括『分析model现在的状态(欠/过拟合),分析我们使用的feature的作用大小,进行feature selection,以及我们模型下的bad case和产生的原因』等等。
2.3 机器学习应用
2.3.1 垃圾邮件分类
垃圾邮件分类就是一个 0/1 分类问题,可以用逻辑回归完成,我们考虑如何降低分类错误率:
尽可能的扩大数据样本:Honypot 做了这样一件事,把自己包装成一个对黑客极具吸引力的机器,来诱使黑客进行攻击,就像蜜罐(honey pot)吸引密封那样,从而记录攻击行为和手段。
添加更多特征:例如我们可以增加邮件的发送者邮箱作为特征,可以增加标点符号作为特征(垃圾邮件总会充斥了?,!等吸引眼球的标点)。
预处理样本:正如我们在垃圾邮件看到的,道高一尺,魔高一丈,垃圾邮件的制造者也会升级自己的攻击手段,如在单词拼写上做手脚来防止邮件内容被看出问题,例如把 medicine 拼写为 med1cinie 等。因此,我们就要有手段来识别这些错误拼写,从而优化我们输入到逻辑回归中的样本。
假如我们要用机器学习解决一个问题,那么最好的实践方法:
- 建立一个简单的机器学习系统,用简单的算法快速实现它。
- 通过画出学习曲线,以及检验误差,来找出我们的算法是否存在高偏差或者高方差的问题,然后再通过假如更多的训练数据、特征变量等等来完善算法。
- 误差分析。例如在构建垃圾邮件分类器,我们检查哪一类型的邮件或者那些特征值总是导致邮件被错误分类,从而去纠正它。当然,误差的度量值也是很重要的,例如我们可以将错误率表示出来,用来判断算法的优劣。
2.3.2 数据偏斜问题
我们再举个极端一点的例子,如果我们的训练集集里只有0.5%的患者患有癌症,因此无论输入是什么,所有预测输出的数据都为0(也就是非癌症),那么我们这里的正确率是99.5%,但是这样的判断标准显然不能体现分类器的性能。
这是因为两者的数据相差非常大,在这里因为癌症的样本非常少,所以导致了预测的结果就会偏向一个极端,我们把这类的情况叫做偏斜类(Skewed Classes)问题。
所以我们需要另一种的评估方法,其中一种评估度量值叫做查准率(Precision)也叫精确率和召回率(Recall)。
如下图所示,建立一个2 x 2的表格,横坐标为真实值,纵坐标为预测值,表格单元1-4分别代表:预测准确的正样本(True positive)、预测错误的正样本(False positive)、预测错误的负样本(False negative)、预测正确的负样本(True negative)。
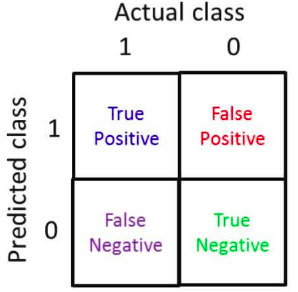
查准率(Precision)= 预测准确的正样本(True positive)/预测的正样本(predicted positive),而其中预测的正样本自然就包括了 预测准确的正样本+ 预测错误的正样本。其含义:表示的是预测为正的样本中有多少是真正的正样本。
P
r
e
c
i
s
i
o
n
=
T
r
u
e
  
p
o
s
i
t
i
v
e
P
r
e
d
i
c
a
t
e
d
  
a
s
  
p
o
s
i
t
i
v
e
=
T
r
u
e
  
p
o
s
i
t
i
v
e
T
r
u
e
  
p
o
s
i
t
i
v
e
+
F
a
l
s
e
  
p
o
s
i
t
i
v
e
Precision=\frac{True\;positive}{Predicated\;as\;positive }=\frac{True\;positive}{True\;positive+False\;positive}
Precision=PredicatedaspositiveTruepositive=Truepositive+FalsepositiveTruepositive
召回率(Recall)= 预测准确的正样本(True positive)/实际的正样本(actual positive),而其中实际的正样本自然就包括了 预测准确的正样本+ 预测错误的负样本。其含义:示的是样本中的正例有多少被预测正确了。
R
e
c
a
l
l
=
T
r
u
e
  
p
o
s
i
t
i
v
e
A
c
t
u
a
l
  
p
o
s
i
t
i
v
e
=
T
r
u
e
  
p
o
s
i
t
i
v
e
T
r
u
e
  
p
o
s
i
t
i
v
e
+
F
a
l
s
e
  
n
e
g
a
t
i
v
e
Recall=\frac{True\;positive}{Actual\;positive}=\frac{True\;positive}{True\;positive+False\;negative}
Recall=ActualpositiveTruepositive=Truepositive+FalsenegativeTruepositive
假如像之前的y一直为0,虽然其查准率为99%,但是其召回率是0%。所以这对于评估算法的正确性是非常有帮助的。
那么查准率(Precision)和召回率(Recall)应该如何评估呢?
假如我们选用两者的平均值,这样看起来可行,但是对于之前的极端例子还是不适用。假如我们预测的y一直为1,那么其召回率就100%了,而查准率非常低,但是平均下来还是相对不错。所以我们采用下面一种评估方法,叫做 F 值:
F
1
  
S
c
o
r
e
=
2
P
R
P
+
R
F_1\;Score = 2\frac{PR}{P+R}
F1Score=2P+RPR
P 指的是 Precision,R 指的是 Recall。
参考:
2.3.3 使用大数据
在机器学习领域,流传着这样一句话:
It’s not who has the best algorithm that wins. It’s who has the most data.
这是为什么呢?
首先我们因为有大量的特征量,去训练数据,这样就导致了我们的训练集误差非常小,也就是
J
t
r
a
i
n
(
θ
)
J_{train}(\theta)
Jtrain(θ) 非常小。然后我们提供了大量的训练数据,这样有利于防止过拟合,可以使得
J
t
r
a
i
n
(
θ
)
≈
J
t
e
s
t
(
θ
)
J_{train}(\theta)\approx J_{test}(\theta)
Jtrain(θ)≈Jtest(θ) 。这样,我们的假设函数既不会存在高偏差,也不会存在高方差,所以相对而言,大数据训练出来会更加准确。
注意了,这里不仅是由大量的训练数据,而且还要有更多的特征量。因为假如只有一些特征量,例如只有房子的大小,去预测房子的价格,那么就连世界最好的销售员也不能只凭房子大小就能告诉你房子的价格是多少。
什么时候采用大规模的数据集呢,一定要保证模型拥有足够的参数(线索),对于线性回归/逻辑回归来说,就是具备足够多的特征,而对于神经网络来说,就是更多的隐层单元。这样,足够多的特征避免了高偏差(欠拟合)问题,而足够大数据集避免了多特征容易引起的高方差(过拟合)问题。
3. 课后编程作业
我将课后编程作业的参考答案上传到了github上,包括了octave版本和python版本,大家可参考使用。
https://github.com/GH-SUSAN/Machine-Learning-MarkDown/tree/master/week6
4. 总结
本周学习了模型评估,误差分析,优化方法等内容。我们在训练模型的同时可以通过以上方法对模型进行分析和调优。
一个正确应用机器学习的方法,就是别管太多细节,先搞出一个baseLine Model,然后在此基础上进行不断优化,这是吴恩达老师推荐的方法。理论->实践->理论 不断迭代















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









