







Evaluating a learning Algorithm
问题:如果做出的模型去预测新的数据时,误差很大怎么办?
- 获取更多的训练数据
- 仔细挑选并减少特征变量,防止过度拟合
- 增加特征变量
- 增加多项式特征变量,如x12 ,x22,x1x2等。
- 增加或减小lambda,调整正则化效果
这些方法本身并无问题,问题在于很多人只是凭借感觉随便挑选方法,比如主观上觉得数据不够,然后花上6个月时间去收集数据,6个月后发现这并没有解决问题。
事实上有很多科学的方法来挑选优化方向,减少你走弯路的概率,为你节省时间
Machine learning diagnostic:
a test that you can run to gain insight what is/isn’t working with a learning algorithm, and gain guidance as to how best to improve its performance.
Evaluating a Hypothesis
如何避免拟合过度和拟合不足
将样本分为训练集和测试集

我比较好奇,这里为什么建立了假设模型去计算误差,而不是使用原来的模型计算误差。
或许是这么计算出来的误差,相当于出错的次数除以总数,相当于错误率。
而原来的误差就是单纯的平均误差。
Model Selection and Train/Validation/Test Sets
Model Selection
可能会设置多个假设,然后获取到每个参数,然后再通过这些参数去计算测试集的误差,选出测试集误差最小的那个作为模型。
这也相当于我们用测试集误差代表了不同模型的泛化能,选择泛化性能最好的那个作为应用模型。(然后这里这种理解并不准确,因为直接使用这个作为我们对泛化性能的度量is not fair)
原因:因为我们其实已经用了测试集去筛选了模型,那么这时的这个模型代表了在测试集上表现良好的模型,但不代表这个模型会是在没有遇到过的数据集上也能表现非常良好,因此不能用这个模型对测试集的误差来作为衡量模型泛化性能的标准。
相当于我们给模型多加了一个参数,这个参数代表了第x个模型,这提升了对该测试数据集(也就是后面提到的交叉验证数据集)拟合程度。
数据集划分方法
因此目前比较科学的数据集划分方法,是将数据集划分为三部分,分别为:
- Training Set :60%
- Cross validation Set : 20%
- Test Set: 20%
划分的比例可以是60%,20%,20%。
训练集用来训练模型,交叉验证集用来选择模型,测试集用来衡量泛化性能。
相当于前两个集合都对模型产生了影响,只有第三个集合相当于盲测。
Bias vs. Variance
Dignosing Bias vs. Variance,高方差,高偏差
什么是高方差什么是高偏差?见下图

起初觉得high bias和high variance翻译作高偏差和高方差很难理解,获许想表达的点在于,对于高偏差,测试集和交叉验证集都偏离实际值,而高方差,则代表对于不同的集合误差相差较大,所以叫高方差。
诊断过度拟合和欠拟合问题
Jcv(θ) 与 Jtest(θ)哪个过高对应不同的问题
如果是degree of polynomial 过低,则为Bias问题,欠拟合
如果是degree of poylnomial 过高导致的,则为Variance问题 ,过拟合

Regularization and Bias/Variance
正则化与偏差方差的关系
正则化的目的是为了不给每个参数过大的权重,来防止过度拟合,high variance:
如果正则化参数lambda过大,则会导致假设方程中除了θ0以外的θ值都趋于0,这时假设函数相当于hθ(x)=θ0 ,会导致欠拟合high Bias;如果过小则会导致过度拟合的high variance。
那么如何确定lambda呢?
方法比较接近于如何选择多项式的次数
我们可以设置一组lambda数值,如:[0, 0.01, 0.02, 0.04, 0.08…10]
然后根据这些不同的lambda计算出一组对应的θ值,然后将这些θ值带入到交叉验证集中去计算出每个的Jcv(θ)(注意这时设置lambda为0),选出一个误差最小的作为合适的θ值。
最后再把最优的θ和λ组合放入Jtest(θ)中去观察泛化性能。
以下为英文标准步骤:

Learning Curves
学习曲线的横坐标为m,纵坐标为J(通过手动调整样本数量m,计算不同的误差均值)
这里需要注意的是,Jcv(θ)每次都是计算的所有样本的总误差均值,而不是像Jtrain(θ)那样,逐渐增加样本数量的
还需要注意的是,这里的误差和不要加正则项了,因为本身就是表达误差和,不是为了求参数theta,加正则项就是多此一举
High Bias
当问题为high bias时,Jcv(θ)和Jtrain(θ)将趋近于近乎重叠,如下图:
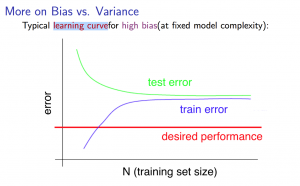

这也帮助我们得出一个结论:如果模型是high bias,那么更多的训练数据无法起到减少误差的作用。
High Variance
当问题为high Variance时,训练集和交叉验证集的误差将会有很大的间隔,但这时,不断增加数据集合,是有助于减少high variance的,因为更多的数据在减少部分独特特征值产生的高权重,也降低了模型的high variance问题。
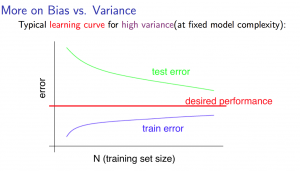

Deciding What to Do Next Revisited
先定位准模型出现的问题,再去尝试解决方法
如果是high bias 则选择增加拟合度类型的方法,比如增加特征变量,减小λ,增加多项式次数。
如果是high variance 则选择减少过度拟合的方法,比如减少特征变量,增加λ,获取更多的数据。

Building a Spam Classifier
以一个例子来说明,机器学习需要首先着重考虑的问题:
如何构建特征向量
以垃圾邮件识别为例,我们可以建立一组特征向量,其中每个向量为某一个特定单词是否出现,比如出现buy,sell,discount,willerhe,now等。通常特征向量会直接选取训练集中出现频率最高的前X个单词。
先用一天时间做出一个简单的模型,让模型运作起来,然后通过绘制的learning curve 去决定是需要更多的数据,还是更多的特征等。因为刚开始接触时,你很难知道到底需要多少数据及多少特征变量。

比较推荐的解决机器学习问题的方法是,先构建一个简单的算法模型,然后根据交叉验证结果进行调整。
同时,对结果的优劣进行一个数字化(误差度量值)的呈现是非常重要的,这能让你更好的决定保留还是取消一个调整决策。
思考:有没有可能,通过机器自己来选择特征向量类型,毕竟如果误差可度量,如果泛化能力也能度量的话,机器自己也可以去不断测试并建立模型吧。感觉难点在于泛化能力很难去客观的度量,机器根据一个test set测试后发现泛化能力不行,然后进行调整,如果还是用同一个test set测试会导致这个test set并不能客观的度量泛化性能,机器要进行大量的测试,就会导致需要无数个 test set的窘境。
但是人工调整时,也是会不断的比对test set的,人工调整也会有一定的泛化性能度量偏误?
所以重点还是去不断的通过cv set去调整,然后通过test set的检测,就应该是最终结果了,如果不行,不要沿着test set误差下降的方向反复调整。
Handling Skewed Data
Skewed classes(偏斜类)
比如检测病人是否有癌症的数据集里,只有0.5%的病人有cancer
如果你的模型为1%的错误率,这时这个错误率也太高了,极端点说,模型只要说所有病人都没病,那么也会有99.5%的正确率,和0.5%的错误率。(思考:这时可能更应该衡量的应该是癌患病人的误诊率?)
因此对于偏斜类,不应该使用一般的度量方法衡量模型优劣。
Precision:查准率
所有我们诊断为癌患的人中,真正患有癌症的人的比率。
Recall:召回率
所有实际患有癌症的人中,我们检测出来的人的比率。

平衡precision and recall
在分类问题中,通常我们会将hθ(x)>=0.5作为预测值为1的标准,如果想要提高precision,我们可以将0.5改为0.7(相当于这个病人癌患概率高于70%时才告诉他是癌症),这样虽然会增加false negative,但是所有预测为1的集合中,实际为1的概率会提高。
但这种方法,会提高recall,因为会调高false negative比率(会有很多漏诊)。
反之同理,如果降低hθ(x)的阈值,则会提高recall,但降低precision。
如何度量不同阈值导致的不同precision和recall组合那个更好?
通过F1 Score综合评估precision和recall

Using Large Data Sets
什么情况下大量数据是有效的,当给出的输入值足够预测输出值时,如果只给出房子面积,而不给出地段的因素,那么再多数据集也无法有效提高模型预测准确率。















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









