







本文来源公众号“机器学习算法那些事”,仅用于学术分享,侵权删,干货满满。
原文链接:有位大佬逐模块解析了detr结构
Transformer在计算机视觉领域大方异彩,Detection Transformer(DETR)是Transformer在目标检测领域的成功应用。利用Transformer中attention机制能够有效建模图像中的长程关系(long range dependency),简化目标检测的pipeline,构建端到端的目标检测器。
objection detection可以理解为一个集合预测任务(预测一个边界框和分类标签的集合),现有的目标检测算法的流程需要在大量proposals/anchors上定义回归和分类任务,DETR则通过预测集合实现目标检测。
优点:
-
不需要预定义的先验anchor
-
不需要NMS的后处理策略
-
增加transformer的编码结构
-
通过前馈神经网络直接预测框的位置和类别
缺点:
-
DETR在大目标检测上性能是最好的,而小目标上稍差
-
基于match的loss导致学习很难收敛,难以学到最优的情况
本文结合论文和代码,逐一分析DETR的模块,DETR的模块主要有:
-
backbone模块
-
位置编码模块
-
transformer编码模块
-
transformer解码模块
-
前馈神经网络模块(FNNs)
-
匈牙利算法匹配模块
-
损失函数模块
论文的模块图:
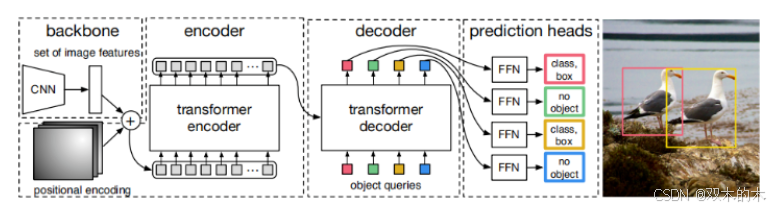
1. bakbone模块

2. 位置编码模块
位置编码模块对对象每个像素点用对应的嵌入向量表示,嵌入向量的维度是d_model,图像每个像素点的嵌入向量包括y方向和x方向的嵌入向量,每个方向的维度是d_model//2,最后拼接y方向和x方向的维度,得到嵌入向量维度d_model。
为了更方便理解,假设输入图像经过backbone后的mask维度:(2,24,32)

由上节可知,backbone模块和位置编码的模块维度相同,因此对两者的输出相加得到transformer编码模块的Q和K向量。
3. transformer编码模块
如上节介绍transformer编码模块的Q和K向量来自backbone模块和图像像素的位置编码模块之和。如下图的绿色框表示:
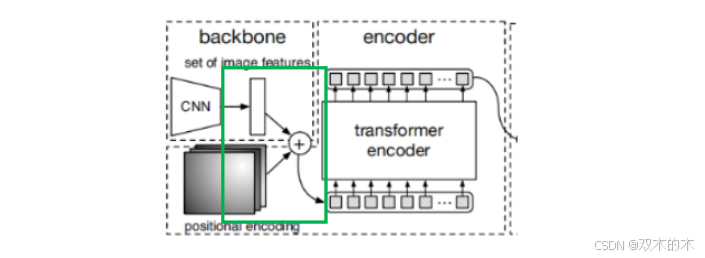
V向量来自backbone模块的输出。
然后经过多头注意力机制得到输出向量,多头注意力机制参考文章:机器学习算法那些事 | 逐模块解析transformer结构-CSDN博客
最后经过残差模块和层归一化模块得到编码输出的向量。
维度表示:
向量Q:tensor(768,2,256)
向量K:tensor(768,2,256)
向量V:tensor(768,2,256)
经过多头注意力机制得到的向量维度:tensor(768,2,256)4. Transformer解码模块
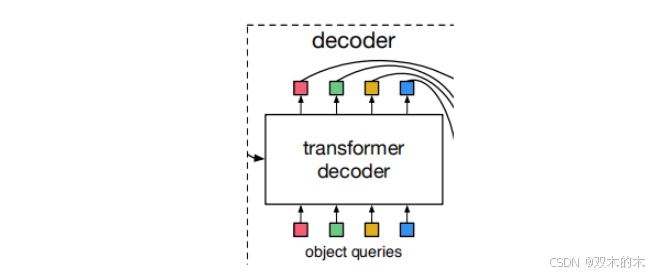
如上图object quries本质上是N个可学习的嵌入维度参数,训练开始时初始化为0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









