









本文来源公众号“Ai学习的老章”,仅用于学术分享,侵权删,干货满满。
原文链接:【教程】大模型量化界翘楚:unsloth
Unsloth Github 项目:https://github.com/unslothai/unsloth
Unsloth
Unsloth 出圈是 DeepSeek-R1 爆火的时候,它发布了最小 1.58 位量化版本的 R1,把 DeepSeek-R1 这个非常大的模型(它有 6710 亿个参数,也就是 671B)通过“量化”把原本 720GB 的模型压缩到只有 131GB 的大小。

Unsloth 秘密武器是动态量化,核心思路是:对模型的少数关键层进行高质量的 4-6bit 量化,而对大部分相对没那么关键的混合专家层(MoE)进行大刀阔斧的 1-2bit 量化。
另外
Unsloth 无缝兼容 HuggingFace Transformers、vLLM 和 LoRA 等生态工具。例如,直接调用 FastLanguageModel 接口即可加载 4 位量化模型,并通过 SFTTrainer 快速配置微调参数
GGUF
Unsloth 深度集成GGUF(GPT-Generated Unified Format),这一由 Llama.cpp 推出的高效量化格式专为边缘计算与本地部署设计。其核心优势包括:
-
动态量化策略:支持 Q2_K、Q4_K_M、Q5_K_S 等多级量化方案,例如对注意力层采用 Q4_K_M(4 位混合精度),而对关键输出层保留 Q5_K_S(5 位稀疏量化),在精度与压缩率间实现最优平衡。
-
硬件适配性:GGUF 通过预计算张量维度与内存对齐策略,显著提升 CPU/GPU 推理速度。实测显示,Unsloth 导出的 GGUF 模型在 Llama.cpp 上推理速度比原始 PyTorch 模型快 2.3 倍。
-
跨平台兼容:支持 Windows/Linux/macOS 原生运行,甚至可在树莓派 5 等嵌入式设备部署。例如,Q4 量化后的 Llama-3-8B 模型仅需 8GB 内存即可流畅推理。

Use it
Huggingface 和 modelscope 上都可以找到 unsloth 开放的量化模型
比如
https://huggingface.co/unsloth/gemma-3-27b-it-GGUF/blob/main/gemma-3-27b-it-Q4_K_M.gguf
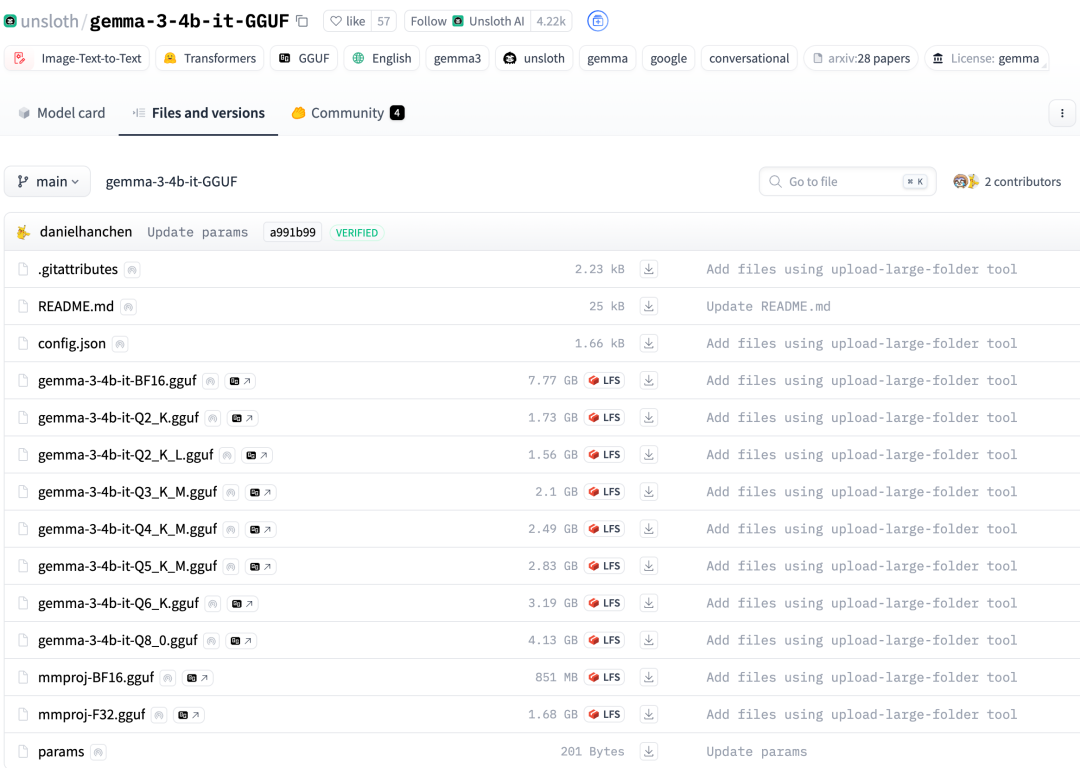
HF Hub 提供了一个查看 GGUF 文件的工具,可以检查元数据及张量信息(名称、形状、精度)。该工具可在模型页面(示例)和文件页面(示例)上使用。
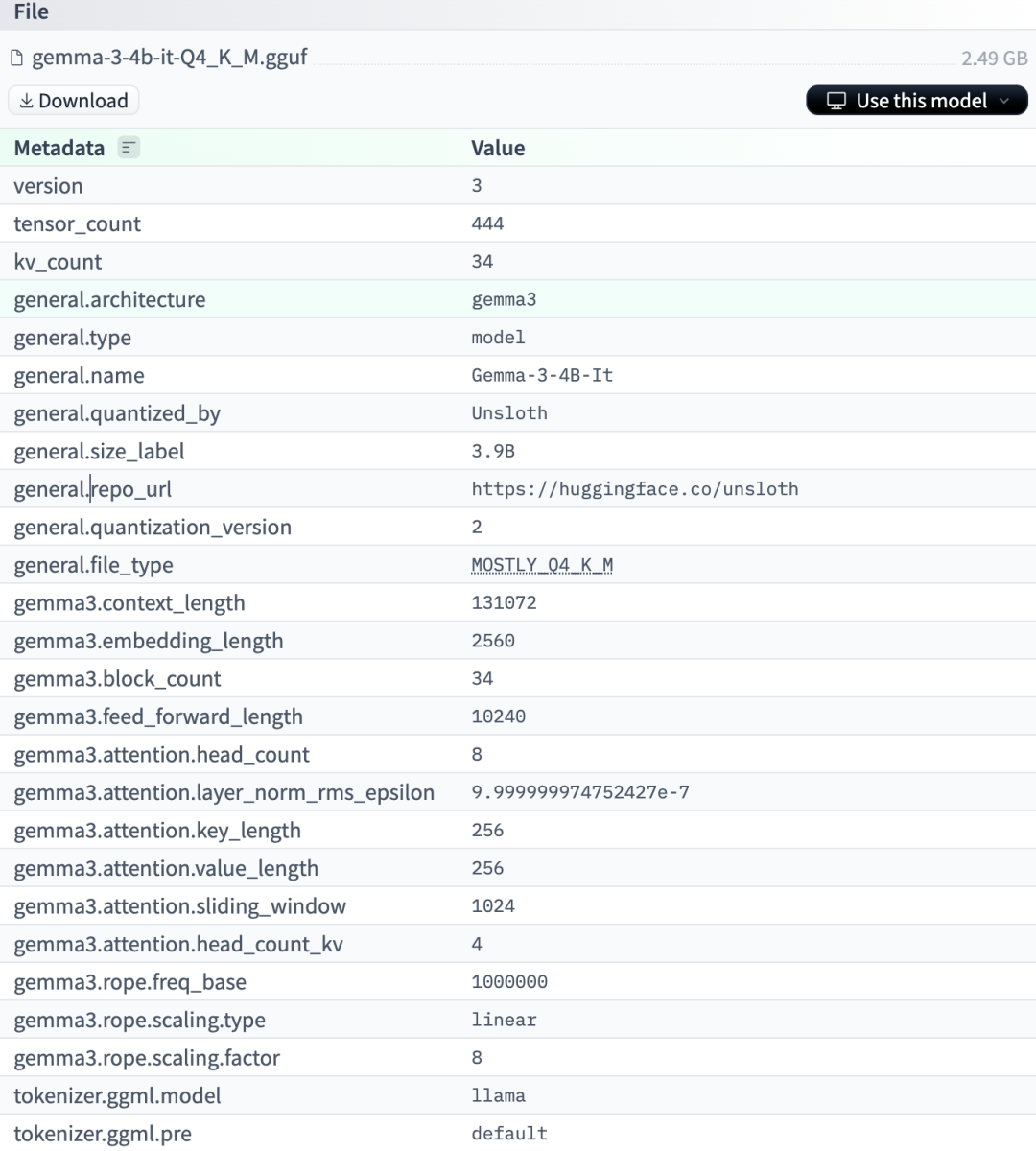
linux 安装依赖、下载模型、运行
apt-get update
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
git clone https://github.com/ggerganov/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=ON -DGGML_CUDA=ON -DLLAMA_CURL=ON
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split
cp llama.cpp/build/bin/llama-* llama.cpp
## 下载模型
# pip install huggingface_hub hf_transfer
# import os # Optional for faster downloading
# os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/gemma-3-4b-it-GGUF",
local_dir = "gemma-3-4b-it-GGUF",
allow_patterns = ["*Q4_K_M*"],
)
## 启动模型
./llama.cpp/llama-cli \
--model /unsloth/gemma-3-4b-it-GGUF/blob/main/gemma-3-4b-it-Q4_K_M.gguf \
--cache-type-k q4_0 \
--threads 12 -no-cnv --prio 2 \
--temp 0.6 \
--ctx-size 8192 \
--seed 3407 \
--prompt "<|User|>What is 1+1?<|Assistant|>"
Mac
我用丐版 mac mini 跑起
# 安装
brew install llama.cpp
# 下载运行模型、注意格式!!
llama-cli -hf unsloth/gemma-3-4b-it-GGUF:Q4_K_M
模型大小 2.5GB,运行起来仅使用了 Swap 内存
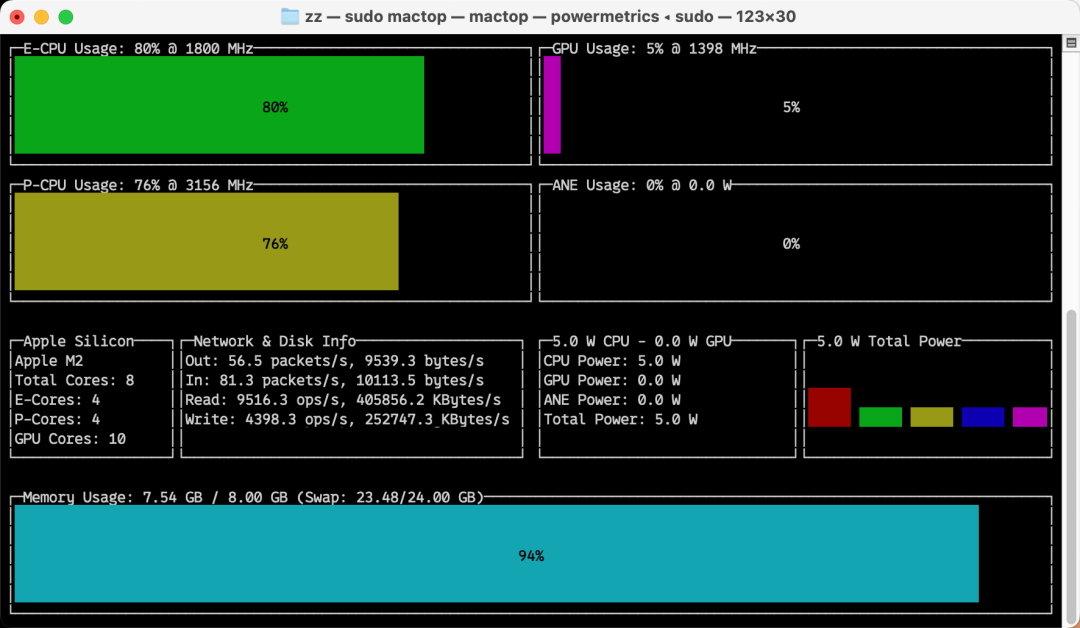
输出性能
llama_perf_sampler_print: sampling time = 7.01 ms / 30 runs ( 0.23 ms per token, 4280.21 tokens per second)
llama_perf_context_print: load time = 20638.18 ms
llama_perf_context_print: prompt eval time = 320.99 ms / 13 tokens ( 24.69 ms per token, 40.50 tokens per second)
llama_perf_context_print: eval time = 50693.96 ms / 1044 runs ( 48.56 ms per token, 20.59 tokens per second)
llama_perf_context_print: total time = 347782.12 ms / 1057 tokens
采样阶段吞吐量 4280t/s,提示词处理 40.5t/s,生成阶段 20.59t/s
unsloth 量化模型也支持 ollama,不再细说
也支持 vLLM,我之前详细介绍演示过:0Ai学习的老章 | 极简教程,大模型量化实践,1张4090跑QwQ?-CSDN博客
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









