









本文来源公众号“Ai学习的老章”,仅用于学术分享,侵权删,干货满满。
原文链接:刚刚,阿里发布Qwen3 技术报告,还有官方量化模型文件
昨天阿里发布了Qwen3的技术报告

来源:https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf
最近 Qwen3 还发布了 Qwen3 的量化版本(GGUF、AWQ、GPTQ),可以通过 Ollama、LM Studio、SGLang 和 vLLM 高效本地部署。
量化技术降低了模型大小和计算需求,使高级 AI 在消费级硬件上也能运行
关于量化,请移步:【教程】大模型量化界翘楚:unsloth
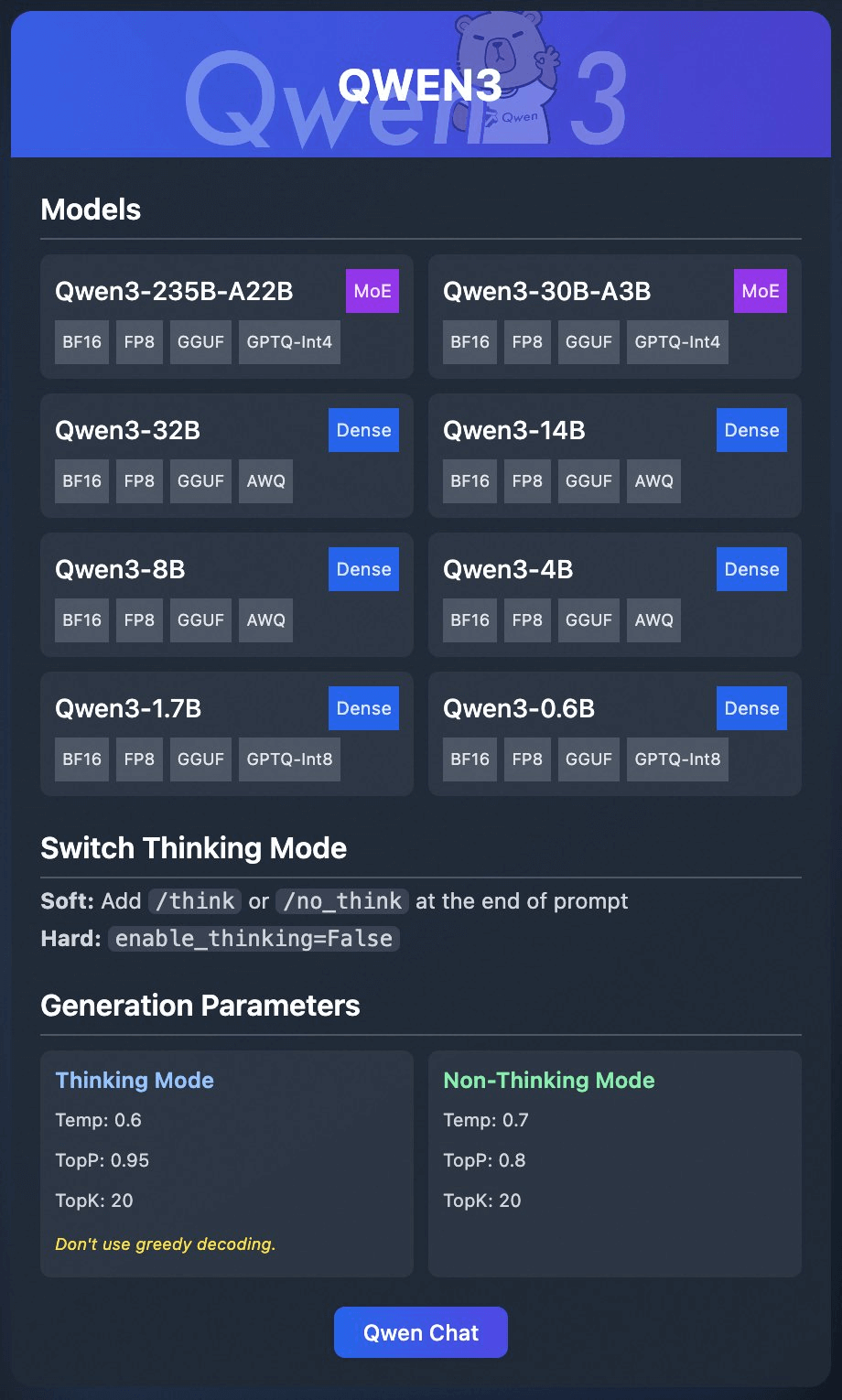
有网友测试 ollama 直接启动官方量化版本 Qwen3-32B,模型文件只有 19GB
之前我测试过,至少需要 4 张 24GB 的 4090 才能跑起来
量化版,目测只需要 1 张卡就行了?
ollama run: http://hf.co/Qwen/Qwen3-32B-GGUF:Q4_K_M
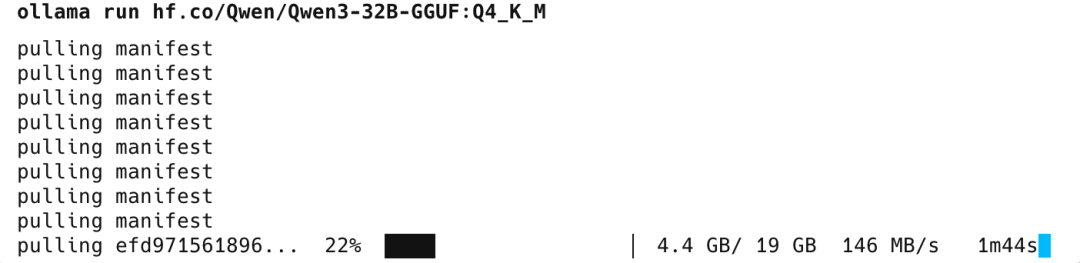
下面实测看看
1 卡跑 Qwen/Qwen3-32B-AWQ
模型文件:https://modelscope.cn/models/Qwen/Qwen3-32B-AWQ/files
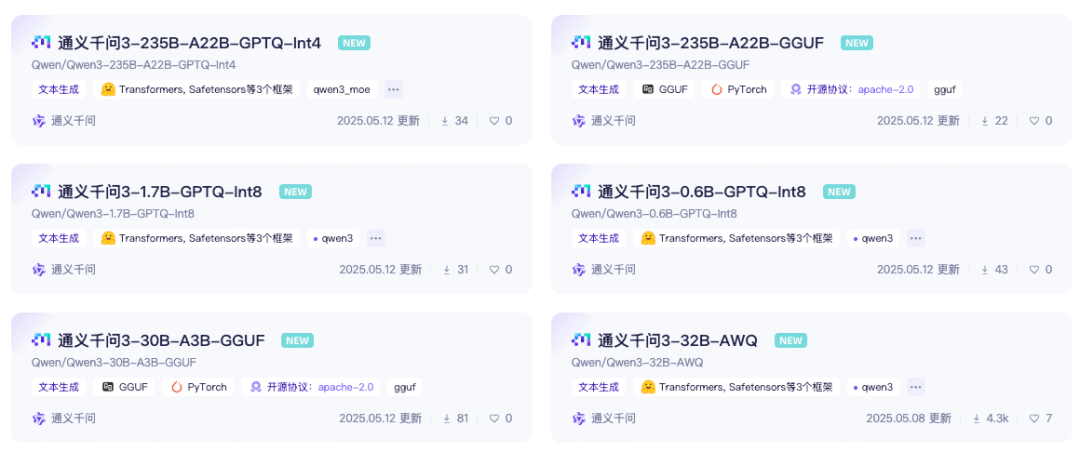
有很多量化版本,这里我选择 AWQ,这是一种感知量化技术,核心特征是激活值引导的智能量化,使用精度敏感型任务
下载
mkdir qwen3-32-awq
cd qwen3-32-awq
modelscope download --model Qwen/Qwen3-32B-AWQ --local_dir .
这个版本可以使用 SGLang 启动
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server --model-path Qwen/Qwen3-32B-AWQ --reasoning-parser qwen3
我更喜欢 vLLM
但是我用单卡 4090 完全无法启动,遭遇 OOM,显存不够用
按官方建议修改 max-model-len 和 gpu-memory-utilization 都不行。
官方建议:
-
第一个是
--max-model-len。默认max_position_embedding是40960,因此 serving 的最大长度也是这个值,导致对内存的要求更高。将其减少到适合自己的长度通常有助于解决 OOM 问题。 -
另一个参数是
--gpu-memory-utilization。vLLM 将预先分配此数量的 GPU 内存。默认情况下,它是0.9。这也是 vLLM 服务总是占用大量内存的原因。如果处于 Eager 模式(默认情况下不是),则可以将其升级以解决 OOM 问题。否则,将使用 CUDA 图形,这将使用不受 vLLM 控制的 GPU 内存,应该尝试降低它。如果它不起作用,尝试--enforce-eager,这可能会减慢推理速度,或减少--max-model-len。
然后用两张 4090 也需要修改 max-model-len 和启动 enforce-eager 才能正常启动
CUDA_VISIBLE_DEVICES=4,5 vllm serve . --serverd-model Qwen3-32B-AWQ --enable-reasoning --reasoning-parser deepseek_r1 --tensor-parallel-size 2 --max-model-len 16384 --enforce-eager
推理速度很慢,18t/s 的样子
不过能把 4 张卡压缩到 2 张卡,已经很量化了
启动之后阿里有推理的建议配置,仅供参考:
-
采样参数:
-
对于思考模式(
enable_thinking=True),使用Temperature=0.6,TopP=0.95,TopK=20, 和MinP=0。不要使用贪心解码,因为它可能导致性能下降和无尽的重复。 -
对于非思考模式(
enable_thinking=False),我们建议使用Temperature=0.7,TopP=0.8,TopK=20, 和MinP=0。 -
对于支持的框架,可以在 0 到 2 之间调整
presence_penalty参数以减少无尽的重复。对于量化模型,强烈建议将此值设为 1.5。 然而,使用更高的值可能会偶尔导致语言混杂并轻微降低模型性能。
-
-
足够的输出长度:对于大多数查询,推荐使用 32,768 个令牌的输出长度。对于高度复杂问题的基准测试,例如数学和编程竞赛中的问题,建议将最大输出长度设为 38,912 个令牌。这为模型提供了足够的空间来生成详细且全面的回答,从而提高其整体性能。
-
标准化输出格式:在进行基准测试时,建议使用提示来标准化模型输出。
-
数学问题:在提示中包含“请逐步推理,并将最终答案放在\boxed{}内。”
-
选择题:向提示中添加以下 JSON 结构以标准化回答:“请仅用选项字母在
answer字段中显示您的选择,例如,"answer": "C"。”
-
-
历史记录中不包含思考内容:在多轮对话中,历史模型输出应仅包括最终输出部分,不需要包含思考内容。这已在提供的 Jinja2 聊天模板中实现。然而,对于不直接使用 Jinja2 聊天模板的框架,开发者需要确保遵循这一最佳实践。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









