






华为云 Flexus 云服务器 X 实例专门为 AI 应用场景设计。它提供了强大的计算能力,能够满足 DeepSeek 模型以及后续搭建 AI Agent 智能体过程中对于数据处理和模型运行的高要求。在网络方面,具备高速稳定的网络带宽,这对于需要频繁联网搜索信息的 AI Agent 智能体至关重要,能确保快速获取网络数据。并且其具备良好的扩展性,当我们后续需要对智能体进行功能扩展或者处理更大规模数据时,可以方便地进行资源调整。同时,在成本控制上,Flexus 云服务器 X 实例提供了按需和包月等多种计费方式,适合不同规模和预算的开发者与企业。


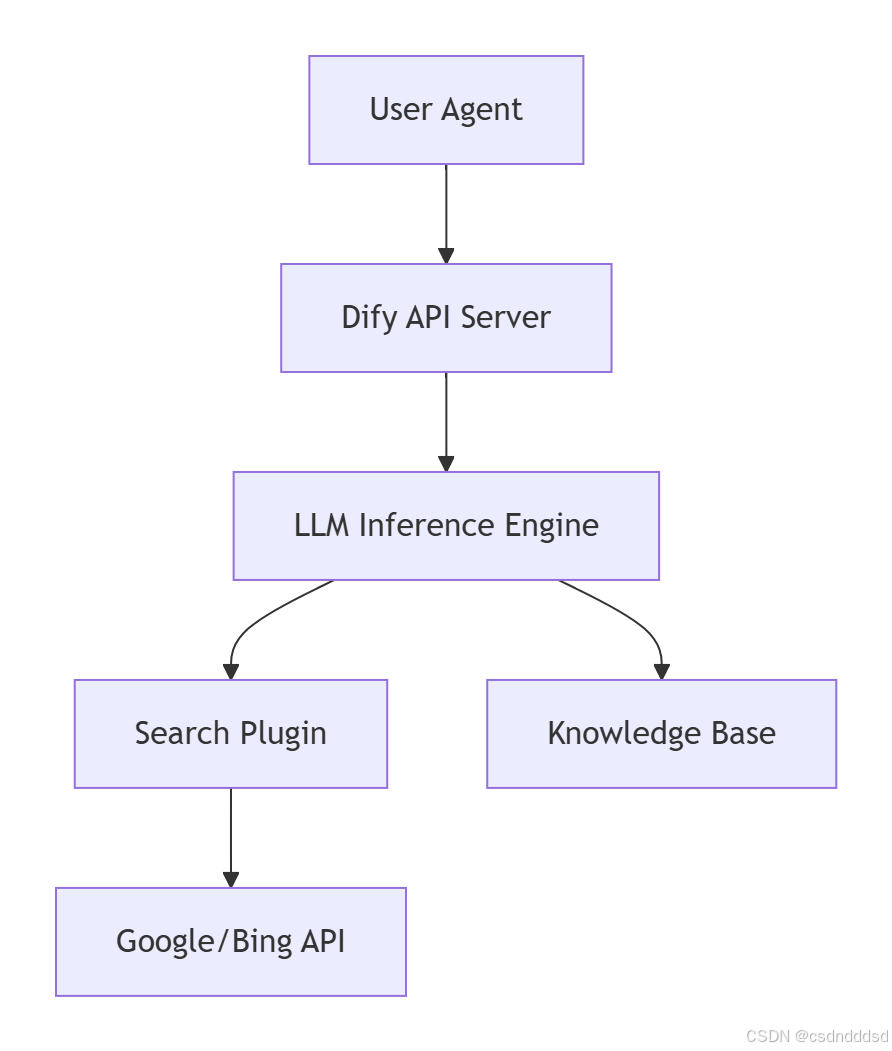
graph TD
A[User Agent] --> B[Dify API Server]
B --> C[LLM Inference Engine]
C --> D[Search Plugin]
D --> E[Google/Bing API]
C --> F[Knowledge Base]
安装搭建步骤
步骤一:准备华为云 Flexus 云服务器 X 实例
1.1 登录华为云官网,在云服务器产品页面中选择 Flexus 云服务器 X 实例。
1.2 根据实际需求选择合适的配置,包括 CPU、内存、存储等。如果预计处理大量数据和复杂任务,建议选择较高配置以确保运行流畅。
1.3 选择操作系统,如 Ubuntu 20.04 等,因为其对后续软件安装和配置的兼容性较好。
1.4 完成配置选择后,点击创建实例,按照提示完成支付等流程。等待实例创建完成,获取服务器的公网 IP 地址、用户名和初始密码。
步骤二:在 Flexus 云服务器上部署 DeepSeek 模型
2.1 使用 SSH 工具,输入服务器的公网 IP 地址、用户名和密码,登录到 Flexus 云服务器。例如,在 Linux 系统下,可以在终端中执行命令ssh username@server_ip,然后输入密码即可登录。
2.2 安装必要的依赖软件
根据 DeepSeek 模型的运行要求,安装相应的依赖软件。这可能包括 Python 环境(建议 Python 3.8 及以上版本)、CUDA(如果服务器配备 GPU 且模型支持 GPU 加速)、cuDNN 等。例如,安装 Python 3.8 可以通过以下命令:
sudo apt update
sudo apt install software - properties - common
sudo add - apt - repository ppa:deadsnakes/ppa
sudo apt install python3.8
2.3 下载 DeepSeek 模型
从 DeepSeek 官方网站或者其指定的开源代码托管平台(如 GitHub)下载 DeepSeek 模型的相关文件。确保下载的模型版本与服务器环境和后续使用需求相匹配。下载完成后,将模型文件解压到合适的目录,例如/home/user/deepseek_model。
# For Base Model
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
# For Chat Model
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-V3
2.4 配置 DeepSeek 模型
进入模型解压目录,根据模型提供的配置文件模板,创建并编辑配置文件。配置文件中需要设置模型运行的相关参数,如模型权重文件路径、输入输出格式、是否启用 GPU 加速等。例如,如果使用 GPU 加速,需要在配置文件中正确设置 CUDA 相关参数:
{
"use_gpu": true,
"cuda_device": 0,
"model_path": "/home/user/deepseek_model/model_weights.bin"
}
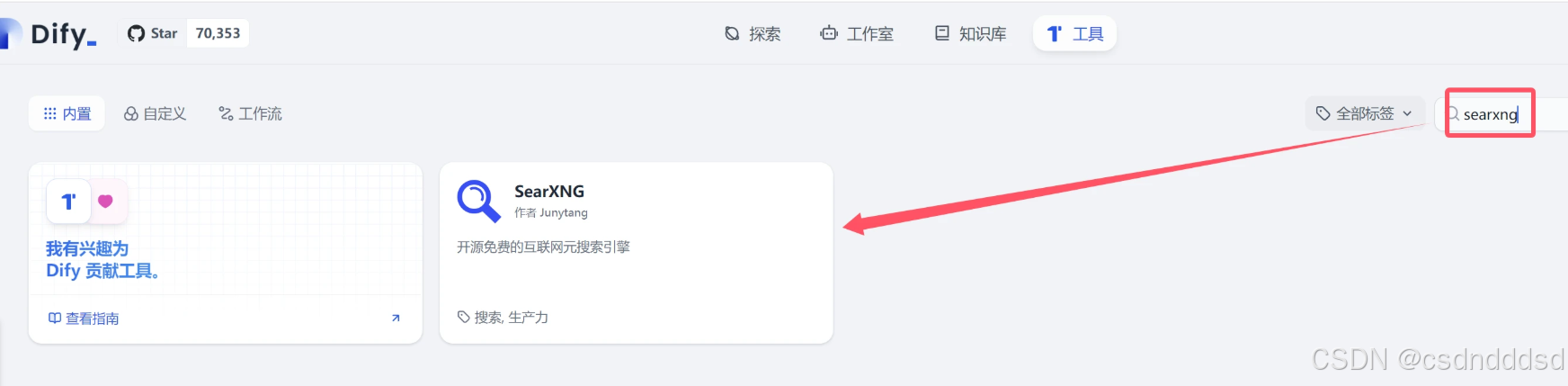
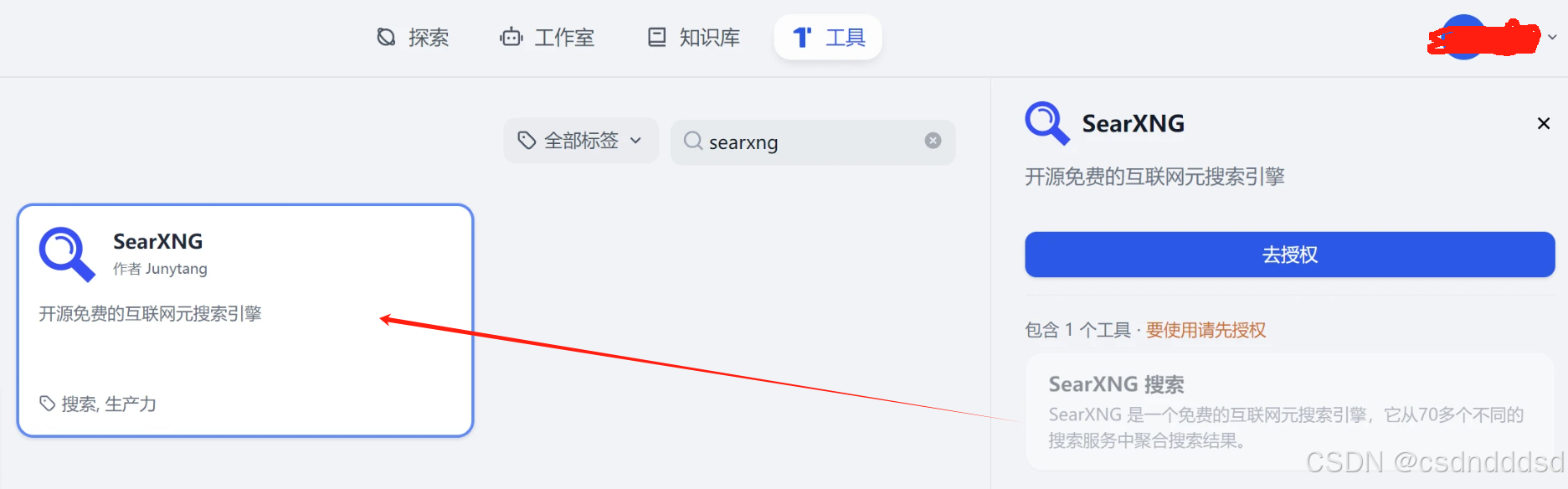
步骤三:获取API Key
打开浏览器,访问博查 AI 搜索的官方网站open.bochaai.com。
在网站首页,使用微信扫码进行登录。如果没有账号,按照提示进行注册。
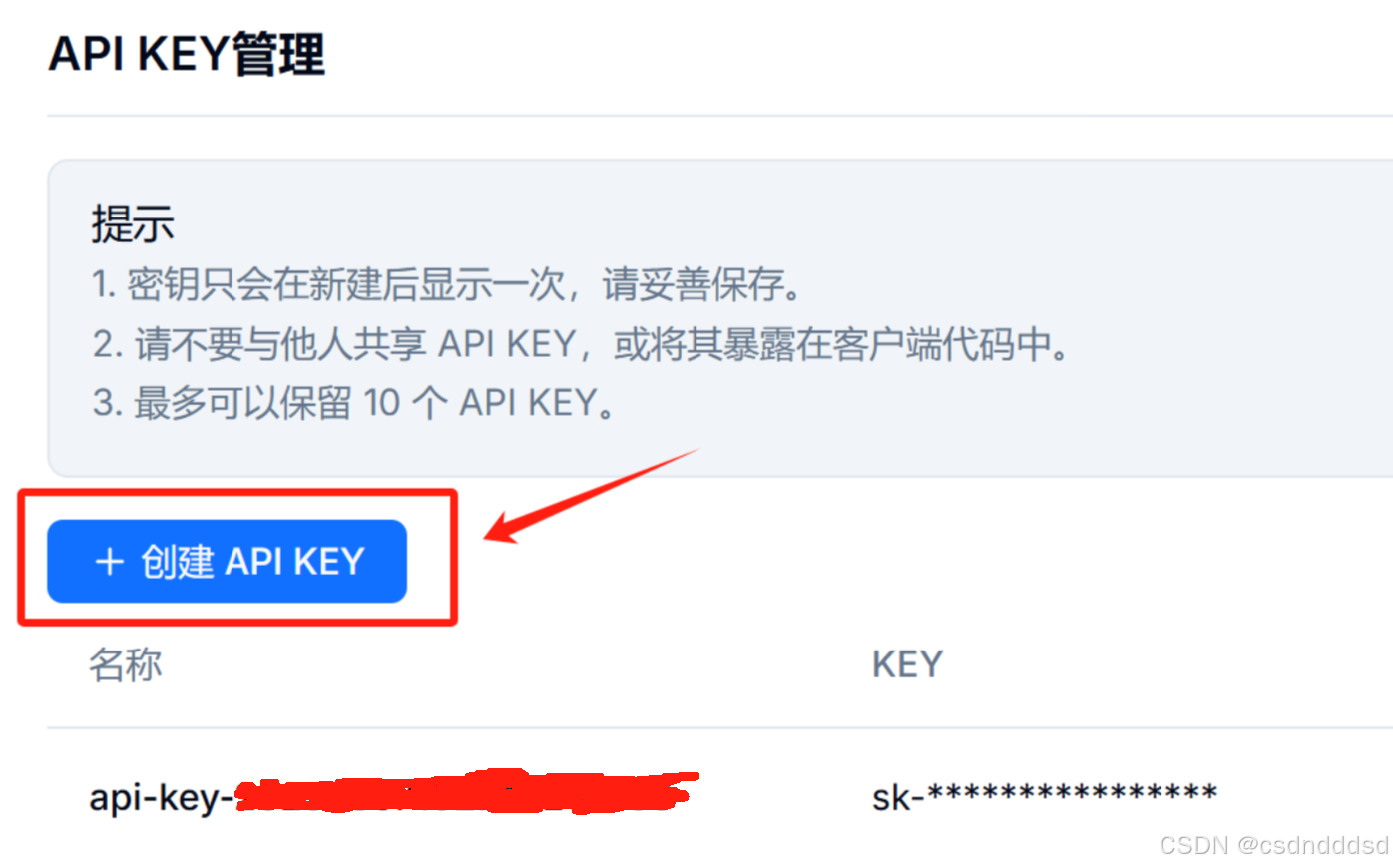
登录成功后,点击右上角的 “AP KEY 管理”。
在 AP KEY 管理页面中,点击创建 API KEY。创建成功后,复制生成的 API KEY,后续在配置 AI Agent 智能体联网搜索功能时会用到。
步骤四:搭建 AI Agent 智能体联网搜索功能
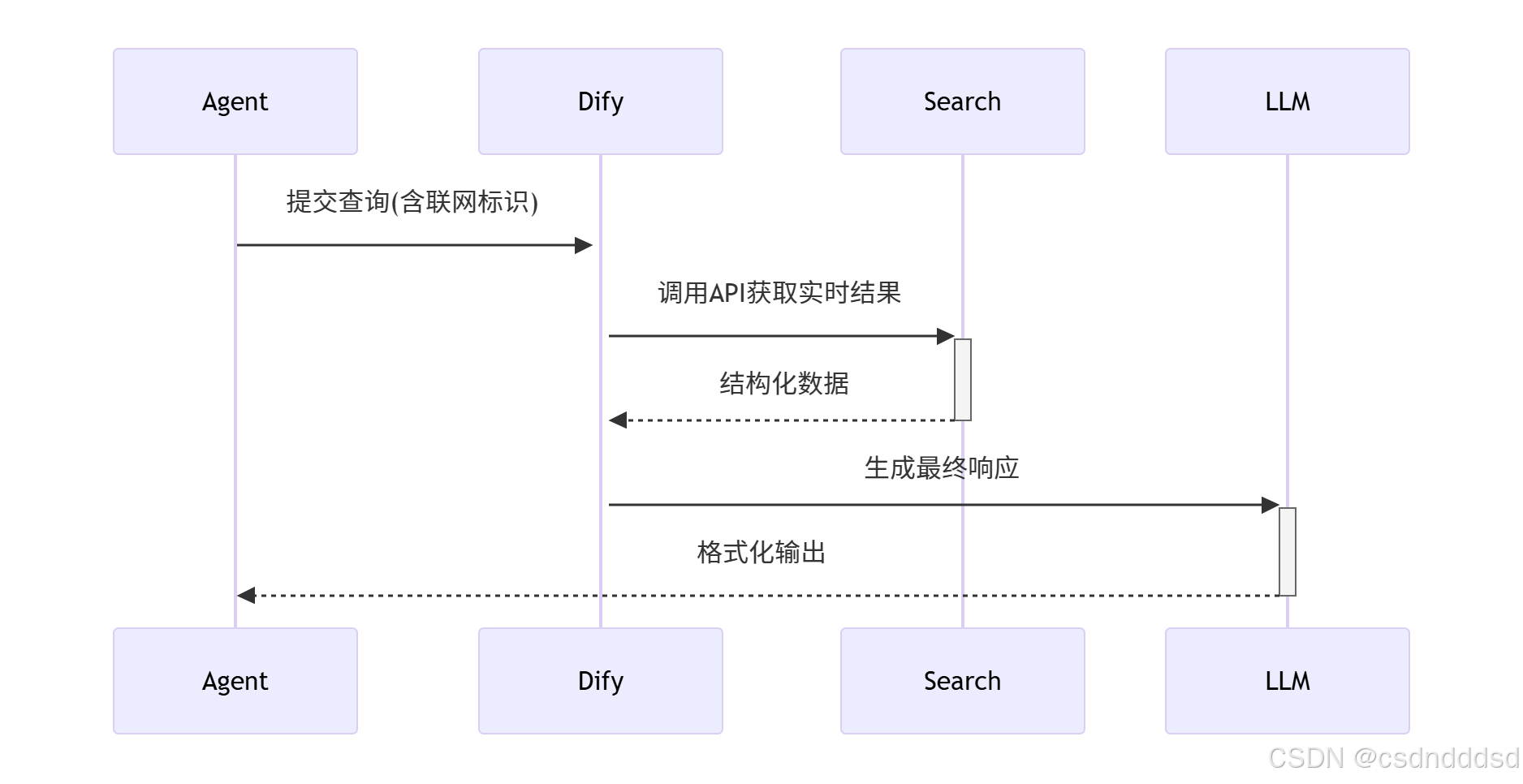
安装相关框架和库
在 Flexus 云服务器上,使用 pip 安装搭建 AI Agent 智能体所需的框架和库,如 LangChain 等。LangChain 是一个用于开发由语言模型驱动的应用程序的框架,它提供了丰富的工具和接口来连接大模型与各种外部工具,包括 Web Search API。安装命令如下:
pip install langchain
编写代码实现联网搜索功能
使用 Python 编写代码,利用 LangChain 框架将 DeepSeek 模型与博查 Web Search API 进行集成:
from langchain.llms import CustomLLM
from langchain.tools import BaseTool, StructuredTool, Tool, tool
from langchain.agents import initialize_agent, AgentType
import requests
# 自定义DeepSeek模型调用类
class DeepSeekLLM(CustomLLM):
def _call(self, prompt, stop = None):
# 实现调用DeepSeek模型的逻辑,根据模型的API进行请求发送和结果获取
response = requests.post('http://deepseek_model_api_url', json = {'prompt': prompt})
return response.json()['answer']
@property
def _identifying_params(self):
return {}
@property
def _llm_type(self):
return "deepseek"
# 定义博查Web Search API工具
@tool
def web_search(query):
api_key = "your_api_key"
url = "https://api.bochaai.com/web_search"
headers = {
"Authorization": f"Bearer {api_key}",
"Content - Type": "application/json"
}
data = {
"query": query
}
response = requests.post(url, headers = headers, json = data)
if response.status_code == 200:
return response.json()
else:
return "Web search error"
# 初始化DeepSeek模型实例
deepseek_llm = DeepSeekLLM()
# 初始化智能体
tools = [web_search]
agent = initialize_agent(tools, deepseek_llm, agent = AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose = True)
# 测试智能体
result = agent.run("最近有什么重大的科技新闻")
print(result)
在上述代码中,首先自定义了DeepSeekLLM类来调用 DeepSeek 模型,然后定义了web_search工具来调用博查 Web Search API 进行联网搜索,最后使用initialize_agent函数初始化智能体,并将 DeepSeek 模型和联网搜索工具整合在一起。运行代码时,将your_api_key替换为实际获取的博查 Web Search API Key,并根据 DeepSeek 模型的实际 API 地址修改http://deepseek_model_api_url。
步骤五:测试与优化
功能测试
在代码中设置不同的查询问题,如 “最近的人工智能研究进展”“当前热门的科技产品有哪些” 等,运行代码后观察智能体的回答。检查回答是否准确地包含了通过联网搜索获取的最新信息,并且回答的逻辑和内容是否合理。
| 测试项 | 纯LLM响应 | 联网增强响应 |
|---|---|---|
| 实时股价查询 | ❌ 无法获取 | ✅ 准确结果 |
| 最新赛事比分 | ❌ 过时信息 | ✅ 实时更新 |
性能优化
如果在测试过程中发现智能体的响应速度较慢,可以从以下几个方面进行优化:
检查服务器资源使用情况,确保服务器有足够的 CPU、内存和网络带宽。如果资源不足,可以考虑升级服务器配置或者优化代码中的资源使用方式。
优化博查 Web Search API 的调用参数,例如调整搜索结果的数量、设置合理的搜索时间范围等,以减少不必要的数据获取,提高搜索效率。
对 DeepSeek 模型的配置进行微调,例如调整模型的缓存策略、优化模型的计算资源分配等,以加快模型的推理速度。
错误处理优化
检查代码中的错误处理机制是否完善。例如,当博查 Web Search API 调用失败时,智能体是否能够给出合理的提示信息,而不是返回错误代码或者崩溃。完善错误处理代码,确保智能体在面对各种异常情况时都能稳定运行,并给用户提供友好的反馈。
结尾
通过以上步骤,我们成功地使用华为云 Flexus+DeepSeek搭建了具备联网搜索能力的 AI Agent 智能体,能够为用户提供更全面、及时的信息服务。在实际应用中,可以根据具体需求进一步扩展和优化智能体的功能。
本文联网搜索使用的是开源免费的searxng
github项目开源地址 https://github.com/searxng/searxng

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









