






SparkSession 工具类
在项目工程【cn.itcast.spark.utils】包下创建工具类:SparkUtils,专门构建SparkSession实例对象,具体步骤如下:
- 构建SparkConf对象、设置通用相关属性
- 判断应用是否本地模式运行,如果是设置值master
- 创建SparkSession.Builder对象,传递SparkConf
- 判断应用是否集成Hive,如果集成,设置HiveMetaStore地址
- 获取SparkSession实例对象
具体编程代码如下所示:
package cn.itcast.spark.utils
import cn.itcast.spark.config.ApplicationConfig
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 构建SparkSession实例对象工具类,加载配置属性
*/
object SparkUtils {
/**
* 构建SparkSession实例对象
* @param clazz 应用Class对象,获取应用类名称
* @return SparkSession实例
*/
def createSparkSession(clazz: Class[_]): SparkSession = {
// 1. 构建SparkConf对象
val sparkConf: SparkConf = new SparkConf()
.setAppName(clazz.getSimpleName.stripSuffix("$"))
// 设置输出文件算法
.set("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version", "2")
.set("spark.debug.maxToStringFields", "20000")
// 2. 判断应用是否本地模式运行,如果是设置值
if(ApplicationConfig.APP_LOCAL_MODE){
sparkConf
.setMaster(ApplicationConfig.APP_SPARK_MASTER)
// 设置Shuffle时分区数目
.set("spark.sql.shuffle.partitions", "4")
}
// 3. 创建SparkSession.Builder对象
var builder: SparkSession.Builder = SparkSession.builder()
.config(sparkConf)
// 4. 判断应用是否集成Hive,如果集成,设置HiveMetaStore地址
if(ApplicationConfig.APP_IS_HIVE){
builder = builder
.enableHiveSupport()
.config("hive.metastore.uris", ApplicationConfig.APP_HIVE_META_STORE_URLS)
.config("hive.exec.dynamic.partition.mode", "nonstrict")
}
// 5. 获取SparkSession实例对象
val session: SparkSession = builder.getOrCreate()
// 6. 返回实例
session
}
}
其中应用开发本地模式运行时,设置SparkSQL Shuffle Partitions数目为4,方便快速运行,在测试和生成环境使用spark-submit提交应用时,通过–conf指定此属性的值。
配置log4j日志文件
Spark中提供了log4j的方式记录日志,可以在【$SPARK_HOME/conf/】下,将【log4j.properties.template】文件copy为【log4j.properties】来启用log4j配置,将其放置Project工程【scr/main/resouces】下面,具体内容如下,随时调整日志级别:
# Set everything to be logged to the console
log4j.rootCategory=INFO, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with H
ive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
# Parquet related logging
log4j.logger.org.apache.parquet.CorruptStatistics=ERROR
log4j.logger.parquet.CorruptStatistics=ERROR
开始应用时,设置【log4j.rootCategory】为【INFO、DEBUG】,方便查看错误信息。
第二章 广告数据 ETL
实际企业项目中,往往收集到数据,需要进一步进行ETL处理操作,保存至数据仓库中,此【综合实战】对广告数据中IP地址解析为省份和城市,最终存储至Hive分区表中,业务逻辑如下:
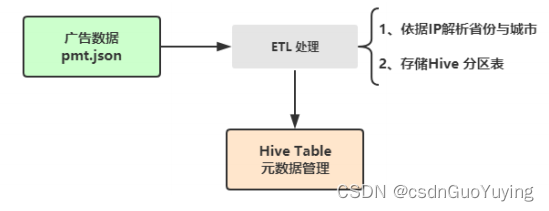
其中涉及两个核心步骤:
- 第一个、IP地址解析,使用第三方库完成;
- 第二个、存储ETL数据至Hive分区表,采用列式Parquet存储;
2.1 IP 地址解析
解析IP地址为【省份、城市】,推荐使用【ip2region】第三方工具库, 准确率99.9%的离线IP地址定位库,0.0x毫秒级查询,ip2region.db数据库只有数MB,提供了java、php、c、python、nodejs、golang、c#等查询绑定和Binary、B树、内存三种查询算法。
官网网址:https://gitee.com/lionsoul/ip2region/,Ip2region特性具有如下四个方面的特性:
1)、99.9%准确率

2)、标准化的数据格式

3)、体积小
包含了全部的IP,生成的数据库文件ip2region.db只有几MB,最小的版本只有1.5MB,随着数据的详细度增加数据库的大小也慢慢增大,目前还没超过8MB。
4)、查询速度快

引入使用IP2Region第三方库:
-
第一步、复制IP数据集【ip2region.db】到工程下的【dataset】目录
-
第二步、在Maven中添加依赖
<!-- 根据ip转换为省市区 -->
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>1.7.2</version>
</dependency>
- 第三步、ip2region的使用

范例演示:传入IP地址解析获取省份和城市,代码思路如下:
a. 创建DbSearch对象,传递字典文件
b. 依据IP地址解析
c. 分割字符串,获取省份和城市
具体代码ConvertIpTest.scala:
package cn.itcast.spark.test.ip
import org.lionsoul.ip2region.{DataBlock, DbConfig, DbSearcher}
/**
* 测试使用ip2Region工具库解析IP地址为省份和城市
*/
object ConvertIpTest {
def main(args: Array[String]): Unit = {
// a. 创建DbSearch对象,传递字典文件
val dbSearcher = new DbSearcher(new DbConfig(), "dataset/ip2region.db")
// b. 依据IP地址解析
val dataBlock: DataBlock = dbSearcher.btreeSearch("182.92.208.23")
// 中国|0|海南省|海口市|教育网
val region: String = dataBlock.getRegion
println(s"$region")
// c. 分割字符串,获取省份和城市
val Array(_, _, province, city, _) = region.split("\\|")
println(s"省份 = $province, 城市 = $city")
}
}
运行结果如下:
















 1454
1454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











