







3. CUDA基本概念(下)
3.3 内存层次(Memory Hierarchy)
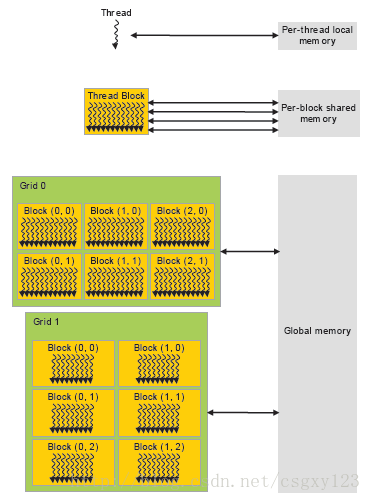
在GPU上CUDA线程可以访问到的存储资源有很多,每个CUDA线程拥有独立的本地内存(local Memory);每一个线程块(block)都有其独立的共享内存(shared memory),共享内存对于线程块中的每个线程都是可见的,它与线程块具有相同的生存时间;同时,还有一片称为全局内存(global memory)的区域对所有的CUDA线程都是可访问的。
除了上述三种存储资源以外,CUDA还提供了两种只读内存空间:常量内存(constant memory)和纹理内存(texture memory),同全局内存类似,所有的CUDA线程都可以访问它们。对于一些特殊格式的数据,纹理内存提供多种寻址模式以及数据过滤方法来操作内存。这两类存储资源主要用于一些特殊的内存使用场合。
一个程序启动内核函数以后,全局内存、常量内存以及纹理内存将会一直存在直到该程序结束。下面是CUDA的内存层次图:
3.4 异构编程(Heterogeneous Programming)
CUDA的异构编程模型假定CUDA线程都运行在一个可被看做CPU协处理器的芯片上,这就使得CUDA内核函数可以和CPU端C程序的运行并行运行,从而加快程序的运行效率。为了达到这个效果,CUDA程序需要管理两大块由DRAM构成的内存区域:CPU端可以访问到的主机内存(host memory)以及GPU端供CUDA内核访问到的设备内存(device memory),设备内存主要由全局内存、常量内存以及纹理内存构成。现在,CUDA程序的运行机制便很明了了:CPU端代码生成原始数据,通过CUDA运行时函数库将这些原始数据传输到GPU上,在CPU端启动CUDA内核函数进行运算,然后将运算结果从设备端传输到主机端,计算任务便完成了。















 3824
3824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









