







机器学习算法中经常出现“有时候”能用,但又不能完全与要求一致。需要指出哪些地方出了问题并解决问题。首先介绍一些重要的规律:大量数据比少量数据好;好的特征比好的算法那更重要。如果选择的特征好,最大化他们的独立性,最小化他们在不同环境之下的变化,那么大部分算法都可以获得比较好的效果。除此之外,还有两个经常遇到的问题:
欠拟合:模型假设太严格,所以模型不能拟合到实际数据上
过拟合:算法不仅学习了数据,而且把噪声也当做信号学习了,这样算法的推广能力很差。
交叉验证、自抽样法、ROC曲线和混淆矩阵
介绍一些用来评估机器学习结果的工具。在监督学习中,最基本的问题就是知道算法的性能:分类器准确吗?测试集或验证集可能并不能精确地反映数据的实际分布。为了更准确的评估分类器性能。我们可以采用交叉验证(Cross-Validation)的技术或者与之比较相近的自抽样法(bootstrapping)。
交叉验证首先把数据分成k个不同的子集。然后用k-1个子集进行训练,用没有用来训练的子集进行测试,这样做k次,每个子集都有一次机会作为测试集,然后把结果平均。
自抽样法跟交叉验证法类似,但是验证集是从训练集中随机选取的,选择的点仅用于测试,不在训练中使用。这样做N次,每次随机选择一些验证集,最后把得到的结果平均。这意味着一些数据样本会出现在不同的验证集中,自抽样法的效果一般胜于交叉验证。
opencv2中机器学习都是基于统计学的机器学习算法,在ML库中,ML库中的所有程序都是用C++写的,他们都继承于StatModel类。
opencv源码中有如下定义:
typedef CvStatModel StatModel;CvStatModel 类包含了所有算法都需要的一些函数。CvStatModel 有两套方法来对磁盘进行模型的读写操作:保存操作的save和write,读操作的load和read。对于机器学习的模型,应该使用简单的save和load。他们实际上是把复杂的write和read函数进行了封装,能够从硬盘读写xml和yaml格式的文件。
class CV_EXPORTS_W CvStatModel
{
public:
CvStatModel();
virtual ~CvStatModel();
virtual void clear();
CV_WRAP virtual void save( const char* filename, const char* name=0 ) const;
CV_WRAP virtual void load( const char* filename, const char* name=0 );
virtual void write( CvFileStorage* storage, const char* name ) const;
virtual void read( CvFileStorage* storage, CvFileNode* node );
protected:
const char* default_model_name;
};load()首先需要调用clear()函数,然后通过此函数装载xml或YAML格式的模型。还有比较重要的函数就是 train和predict方法。
机器学习的train()方法根据具体的算法呈现不同的形式,所有的算法都已一个指向CvMat矩阵的指针作为训练数据。矩阵必须是32FC1的类型。CvMat结构可以支持多通道矩阵,但是机器学习只采用单通道矩阵。一般情况下,这个矩阵以行排列数据样本,每个数据样本被表示为一个行向量。矩阵的每一列,表示某个变量在不同的数据样本中的不同取值,这样组成了一个二维的数据矩阵。
float CvStatMode::predict(const CvMat::sample[,<prediction_params>]) const;这个预测函数。如果是分类问题,他会返回一个类别标签。如果是回归问题,他会返回一个数值标签。函数后缀const可以知道:预测不影响模型的内部状态。因此,这个方法可以并行调用。
typedef struct CvTermCriteria
{
int type;//CV_TERMCRIT_ITER or CV_TERMCRIT_EPS
int max_iter; // 最大迭代次数
double epsilon; //当误差低于这个值的时候就会停止迭代
}首先讲解Mahalanobis距离矩阵,然后介绍无监督算法K均值。这两个算法在cxcore库中。
Mahalanobis距离是数据所在的空间的协方差的度量。
Mahalanobis即是马氏距离。
对于两个不同特征的度量,往往需要将通过数据的协方差归一化空间,才能进行融合比较。比如:如果我们以米为单位来测量人的身高,以天为单位测量人的年龄,我们看到身高的范围很小,而年龄的范围很大。通过方差归一化,变量之间的关系便会更加符合实际情况。K近邻之类的算法很难处理方差相差很大的数据,但是决策树则不受这种情况影响。
我们首先需要得到协方差矩阵,然后计算其逆矩阵。我们就可以求得两个向量的Mahalanobis距离。Mahalanobis距离与欧几里得距离类似,只不过他还需要除以空间的协方差矩阵。Mahalanobis距离是一个数值,如果协方差矩阵是单位矩阵,则 Mahalanobis距离就会退化为欧几里得距离。
(1)马氏距离定义而其中向量Xi与Xj之间的马氏距离定义为:
若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了:
也就是欧氏距离了。
若协方差矩阵是对角矩阵,公式变成了标准化欧氏距离。
(2)马氏距离的优缺点:量纲无关,排除变量之间的相关性的干扰。
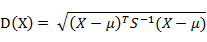
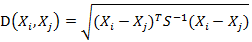
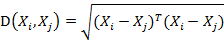
OpenCV中使用Mahalanobis函数。
//! computes Mahalanobis distance between two vectors: sqrt((v1-v2)'*icovar*(v1-v2)), where icovar is the inverse covariation matrix
CV_EXPORTS_W double Mahalanobis(InputArray v1, InputArray v2, InputArray icovar);这是函数原型,可以看出,v1和v2是输入向量,而icovar是协方差矩阵的逆矩阵。而calcCovarMatrix()是用来计算协方差矩阵的,invert()是用来计算逆矩阵的。
K均值是一个比较常用的算法。但是也有一个问题,我们给出该问题的一个解决办法:
K均值假设空间的协方差矩阵不会影响结果,或者已经归一化。所以我们首先(如果需要)对结果进行协方差归一化。
K均值不保证能找到定位聚类中心的最佳方案,但是他能保证能收敛到某个解决方案。
所以我们可以在K均值中,每个聚类中心拥有他的数据点,我们计算这些点的方差,最好的聚类在不引起太大的复杂度的情况下使方差达到最小。我们就可以多运行几次K均值,每次初始的聚类中心点都不一样。然后选择方差最小的那个结果。
如何对数据协方差归一化:
我们可以将每个数据乘以协方差的逆矩阵就能够实现归一化。
OpenCV2中使用kmeans函数计算聚类中心。
//! clusters the input data using k-Means algorithm
CV_EXPORTS_W double kmeans( InputArray data, int K, CV_OUT InputOutputArray bestLabels,
TermCriteria criteria, int attempts,
int flags, OutputArray centers=noArray() );














 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









