






- T1.
byte b1=1,b2=2,b3,b6,b8;
final byte b4=4,b5=6,b7;
b3=(b1+b2); /*语句1*/ 错误
b6=b4+b5; /*语句2*/ 正确
b8=(b1+b4); /*语句3*/ 错误
b7=(b2+b5); /*语句4*/ 错误
System.out.println(b3+b6);下列代码片段中,存在编辑错误的语句是()
A 语句2
B 语句1
C 语句3
D 语句4Java表达式转型规则由低到高转换:
1、所有的byte,short,char型的值将被提升为int型;
2、如果有一个操作数是long型,计算结果是long型;
3、如果有一个操作数是float型,计算结果是float型;
4、如果有一个操作数是double型,计算结果是double型;
5、被fianl修饰的变量不会自动改变类型,当2个final修饰相操作时,结果会根据左边变量的类型而转化。
————–解析————–
语句1错误:b3=(b1+b2);自动转为int,所以正确写法为b3=(byte)(b1+b2);或者将b3定义为int;
语句2正确:b6=b4+b5;b4、b5为final类型,不会自动提升,所以和的类型视左边变量类型而定,即b6可以是任意数值类型;
语句3错误:b8=(b1+b4);虽然b4不会自动提升,但b1仍会自动提升,所以结果需要强转,b8=(byte)(b1+b4);
语句4错误:b7=(b2+b5); 同上。同时注意b7是final修饰,即只可赋值一次,便不可再改变。
- T2. 在统计模式识分类问题中,当先验概率未知时,可以使用()?
A 最小损失准则
B N-P判决
C 最小最大损失准则
D 最小误判概率准则答案 BC
在贝叶斯决策中,对于先验概率p(y),分为已知和未知两种情况。
1. p(y)已知,直接使用贝叶斯公式求后验概率即可;
2. p(y)未知,可以使用聂曼-皮尔逊决策(N-P决策)来计算决策面。
而最大最小损失规则主要就是使用解决最小损失规则时先验概率未知或难以计算的问题的。
二、选择题
1、影响聚类算法结果的主要因素有( B C D )。
A.已知类别的样本质量;B.分类准则;C.特征选取;D.模式相似性测度
2、模式识别中,马式距离较之于欧式距离的优点是( C D )。
A.平移不变性;B.旋转不变性;C尺度不变性;D.考虑了模式的分布
3、影响基本K-均值算法的主要因素有( D A B )。
A.样本输入顺序;B.模式相似性测度;C.聚类准则;D.初始类中心的选取 4、位势函数法的积累势函数K(x)的作用相当于Bayes判决中的( B D )。
A. 先验概率;B. 后验概率;C. 类概率密度;D. 类概率密度与先验概率的乘积
5、在统计模式分类问题中,当先验概率未知时,可以使用(B D )。
A. 最小损失准则; B. 最小最大损失准则; C. 最小误判概率准则; D. N-P判决
6、散度JD是根据( C )构造的可分性判据。
A. 先验概率;B. 后验概率;C. 类概率密度;D. 信息熵;E. 几何距离
7、似然函数的概型已知且为单峰,则可用( A B C D E)估计该似然函数。
A. 矩估计;B. 最大似然估计;C. Bayes估计;D. Bayes学习;E. Parzen窗法
8、KN近邻元法较之Parzen窗法的优点是( B )。
A. 所需样本数较少; B. 稳定性较好; C. 分辨率较高; D. 连续性较好
9、从分类的角度讲,用DKLT做特征提取主要利用了DKLT的性质:( A C )。
A.变换产生的新分量正交或不相关;B.以部分新的分量表示原矢量均方误差最小;C.使变换后的矢量能量更集中
10、如果以特征向量的相关系数作为模式相似性测度,则影响聚类算法结果的主要因素有( B C )。
A. 已知类别样本质量; B. 分类准则; C. 特征选取;D. 量纲
11、欧式距离具有( A B );马式距离具有( A B C D )。
A. 平移不变性; B. 旋转不变性; C. 尺度缩放不变性; D. 不受量纲影响的特性
12、聚类分析算法属于( A );判别域代数界面方程法属于( C ) 。
A.无监督分类; B.有监督分类; C.统计模式识别方法; D.句法模式识别方法
13、若描述模式的特征量为0-1二值特征量,则一般采用( D )进行相似性度量。
A. 距离测度; B. 模糊测度; C. 相似测度; D. 匹配测度
14、 下列函数可以作为聚类分析中的准则函数的有( A C D ) 。
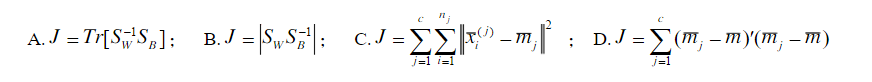
15、Fisher线性判别函数的求解过程是将N维特征矢量投影在( B )中进行 。 A.二维空间; B.一维空间; C. N-1维空间
16、用parzen窗法估计类概率密度函数时,窗宽过窄导致波动过大的原因是( B、C )。
A.窗函数幅度过小;B.窗函数幅度过大;C. 窗口中落入的样本数过少;D.窗口中落入的样本数过多。
17、如下聚类算法中,属于静态聚类算法的是 ( A、B )。
A. 最大最小距离聚类;B. 层次聚类; C. c-均值聚类。
18、 一般,k-NN最近邻方法在( B )的情况下效果较好。
A.样本较多但典型性不好;B.样本较少但典型性好;C.样本呈团状分布;D.样本呈链状分布
19、影响c均值聚类算法效果的主要因素之一是初始类心的选取,相比较而言,( C )c个样本作为初始类心较好。
A. 按输入顺序选前; B. 选相距最远的; C. 选分布密度最高处的; D. 随机挑选。
20、类域界面方程法中,能求线性不可分情况下分类问题近似或精确解的方法是( B、C、D )。
A. 感知器算法; B. 伪逆法; C. 基于二次准则的H-K算法; D. 势函数法。
下面关于Hive的说法正确的是()
A Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文本映射为一张数据库表,并提供简单的SQL查询功能
B Hive可以直接使用SQL语句进行相关操作
C Hive能够在大规模数据集上实现低延迟快速的查询
D Hivez在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS中Hive设定的目录下答案是 AD
Hive使用类sql语句进行相关操作,称为HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
以下几种模型方法属于判别式模型(Discriminative Model)的有()
1)混合高斯模型
2)条件随机场模型
3)区分度训练
4)隐马尔科夫模型
A 2,3
B 3,4
C 1,4
D 1,2答案是 A
产生式模型(Generative Model)与判别式模型(Discrimitive Model)是分类器常遇到的概念,它们的区别在于:
对于输入x,类别标签y:
产生式模型估计它们的联合概率分布P(x,y)
判别式模型估计条件概率分布P(y|x)
产生式模型可以根据贝叶斯公式得到判别式模型,但反过来不行。
常见的判别模型有:
支持向量机
传统的神经网络
线性判别分析
线性回归产生式模型常见的主要有:
高斯
朴素贝叶斯
混合多项式
混合高斯模型
专家的混合物
隐马尔可夫模型
马尔可夫的随机场大整数845678992357836701转化成16进位制的表示,最后两位字符是()
A 8B
B AB
C EF
D 9D













 3090
3090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









