







让我们来了解一下SSD。
SD方法基于一个前馈卷积网络,该网络生成一个固定大小的边界框集合和每个框的对象类别分数,避免了传统目标检测方法中边界框建议和重采样的阶段。这种方法显著提高了检测速度。此外,SSD通过在不同层次的特征图上进行检测,允许模型利用不同尺度的信息,从而提高对各种尺寸和形状目标的检测性能。
主要特点:
- 高效的检测方法:SSD是一种用于多类别检测的单次检测器,相比之前的单次检测器(如YOLO)更快,准确度也明显提高,与那些执行显式区域建议和池化的较慢技术(包括Faster R-CNN)几乎一样准确。
- 创新的框架设计:SSD的核心是应用于特征图的小型卷积滤波器,用于预测一组固定默认边界框的类别分数和框偏移量。
- 多尺度特征图与硬负挖掘:SSD利用多尺度特征图和硬负挖掘技术,改进了检测精度,尤其是对于不同尺寸和形状的对象。
技术原理:
SSD框架:
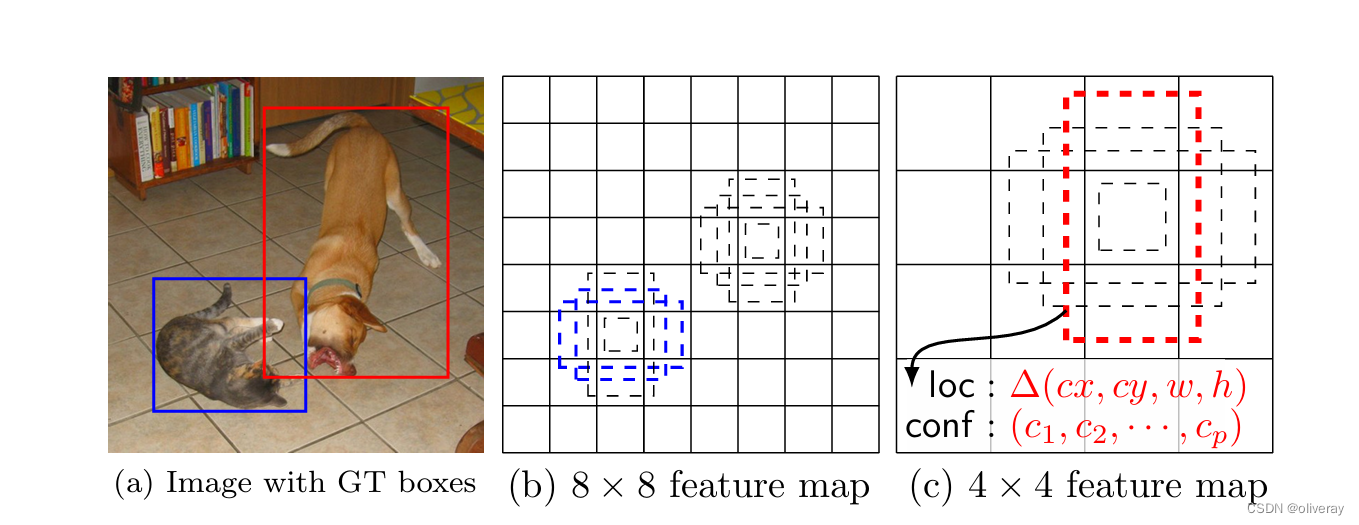
SSD在训练时只需要输入图像和每个对象的真实边框。按照卷积的方式,在几个具有不同尺度(例如 8×8 和 4×4 在 (b) 和(c)的特征图每个位置,我们评估一小组(例如 4 个)不同宽高比的默认边框。对于每一个默认边框,我们预测所有对象类别的形状偏移和置信度(![]() (c1,c2,…))。在训练时,我们首先将这些默认边框与真实边框进行匹配。例如,我们将两个默认边框分别与猫和狗匹配,它们被视为正样本,其余的则视为负样本。模型损失是定位损失和置信度损失的加权和。
(c1,c2,…))。在训练时,我们首先将这些默认边框与真实边框进行匹配。例如,我们将两个默认边框分别与猫和狗匹配,它们被视为正样本,其余的则视为负样本。模型损失是定位损失和置信度损失的加权和。

网络会使用多个特征层来进行检测任务,每个特征层可能是网络新添加的,或者是从网络的基础部分(如VGG或ResNet等)继承的现有层。每个特征层都会通过一系列的卷积滤波器来生成检测预测,而这些预测再通过网络的顶部结构输出(如图2所示)。
具体来说,对于特征层的每一个单元区域(比如大小为m×n),网络会使用小的3×3×p的卷积核来预测目标的类别分数或相对于默认框坐标的位置偏移。应用该卷积核于特征层的每一个位置上,会输出一个预测值。对边界框的位置预测是相对于特征层上对应位置的默认框来测量的。
默认框是预先设定的一组形状和大小,它们对应于不同特征图单元的位置。在每个特征图单元,网络会预测相对于该单元中默认框形状的偏移量,以及每个框可能包含类别实例的置信度(类分数)。简单来说,对于每个默认框,网络会计算每个类别的置信度以及4个与默认框形状的位置偏移值。对于m×n大小的特征层,总共就会有![]() (c+4)kmn个输出。
(c+4)kmn个输出。
SSD中的默认框在概念上与Faster R-CNN中使用的锚点框类似,但SSD将这些默认框应用到多个分辨率的特征图上,这样可以有效地覆盖不同尺寸和比例的目标,提高检测的准确性和灵活性。
让我们来实现一下这个模型:
首先是SSD网络:
class L2Norm(nn.Module):
def __init__(self,n_channels, scale):
super(L2Norm,self).__init__()
self.n_channels = n_channels
self.gamma = scale or None
self.eps = 1e-10
self.weight = nn.Parameter(torch.Tensor(self.n_channels))
self.reset_parameters()
def reset_parameters(self):
init.constant_(self.weight,self.gamma)
def forward(self, x):
norm = x.pow(2).sum(dim=1, keepdim=True).sqrt()+self.eps
x = torch.div(x,norm)
out = self.weight.unsqueeze(0).unsqueeze(2).unsqueeze(3).expand_as(x) * x
return out
def add_extras(in_channels, backbone_name):
layers = []
if backbone_name == 'mobilenetv2':
layers += [InvertedResidual(in_channels, 512, stride=2, expand_ratio=0.2)]
layers += [InvertedResidual(512, 256, stride=2, expand_ratio=0.25)]
layers += [InvertedResidual(256, 256, stride=2, expand_ratio=0.5)]
layers += [InvertedResidual(256, 64, stride=2, expand_ratio=0.25)]
else:
# Block 6
# 19,19,1024 -> 19,19,256 -> 10,10,512
layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)]
layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)]
# Block 7
# 10,10,512 -> 10,10,128 -> 5,5,256
layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)]
# Block 8
# 5,5,256 -> 5,5,128 -> 3,3,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
# Block 9
# 3,3,256 -> 3,3,128 -> 1,1,256
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
return nn.ModuleList(layers)
class SSD300(nn.Module):
def __init__(self, num_classes, backbone_name, pretrained = False):
super(SSD300, self).__init__()
self.num_classes = num_classes
if backbone_name == "vgg":
self.vgg = add_vgg(pretrained)
self.extras = add_extras(1024, backbone_name)
self.L2Norm = L2Norm(512, 20)
mbox = [4, 6, 6, 6, 4, 4]
loc_layers = []
conf_layers = []
backbone_source = [21, -2]
for k, v in enumerate(backbone_source):
loc_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
for k, v in enumerate(self.extras[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
elif backbone_name == "mobilenetv2":
self.mobilenet = mobilenet_v2(pretrained).features
self.extras = add_extras(1280, backbone_name)
self.L2Norm = L2Norm(96, 20)
mbox = [6, 6, 6, 6, 6, 6]
loc_layers = []
conf_layers = []
backbone_source = [13, -1]
for k, v in enumerate(backbone_source):
loc_layers += [nn.Conv2d(self.mobilenet[v].out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(self.mobilenet[v].out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
for k, v in enumerate(self.extras, 2):
loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
elif backbone_name == "resnet50":
self.resnet = nn.Sequential(*resnet50(pretrained).features)
self.extras = add_extras(1024, backbone_name)
self.L2Norm = L2Norm(512, 20)
mbox = [4, 6, 6, 6, 4, 4]
loc_layers = []
conf_layers = []
out_channels = [512, 1024]
for k, v in enumerate(out_channels):
loc_layers += [nn.Conv2d(out_channels[k], mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(out_channels[k], mbox[k] * num_classes, kernel_size = 3, padding = 1)]
for k, v in enumerate(self.extras[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size = 3, padding = 1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size = 3, padding = 1)]
else:
raise ValueError("The backbone_name is not support")
self.loc = nn.ModuleList(loc_layers)
self.conf = nn.ModuleList(conf_layers)
self.backbone_name = backbone_name
def forward(self, x):
sources = list()
loc = list()
conf = list()
if self.backbone_name == "vgg":
for k in range(23):
x = self.vgg[k](x)
elif self.backbone_name == "mobilenetv2":
for k in range(14):
x = self.mobilenet[k](x)
elif self.backbone_name == "resnet50":
for k in range(6):
x = self.resnet[k](x)
s = self.L2Norm(x)
sources.append(s)
if self.backbone_name == "vgg":
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
elif self.backbone_name == "mobilenetv2":
for k in range(14, len(self.mobilenet)):
x = self.mobilenet[k](x)
elif self.backbone_name == "resnet50":
for k in range(6, len(self.resnet)):
x = self.resnet[k](x)
sources.append(x)
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if self.backbone_name == "vgg" or self.backbone_name == "resnet50":
if k % 2 == 1:
sources.append(x)
else:
sources.append(x)
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
)
return output然后是目标损失函数,就是MultiBox目标:
class MultiboxLoss(nn.Module):
def __init__(self, num_classes, alpha=1.0, neg_pos_ratio=3.0,
background_label_id=0, negatives_for_hard=100.0):
self.num_classes = num_classes
self.alpha = alpha
self.neg_pos_ratio = neg_pos_ratio
if background_label_id != 0:
raise Exception('Only 0 as background label id is supported')
self.background_label_id = background_label_id
self.negatives_for_hard = torch.FloatTensor([negatives_for_hard])[0]
def _l1_smooth_loss(self, y_true, y_pred):
abs_loss = torch.abs(y_true - y_pred)
sq_loss = 0.5 * (y_true - y_pred)**2
l1_loss = torch.where(abs_loss < 1.0, sq_loss, abs_loss - 0.5)
return torch.sum(l1_loss, -1)
def _softmax_loss(self, y_true, y_pred):
y_pred = torch.clamp(y_pred, min = 1e-7)
softmax_loss = -torch.sum(y_true * torch.log(y_pred),
axis=-1)
return softmax_loss
def forward(self, y_true, y_pred):
num_boxes = y_true.size()[1]
y_pred = torch.cat([y_pred[0], nn.Softmax(-1)(y_pred[1])], dim = -1)
conf_loss = self._softmax_loss(y_true[:, :, 4:-1], y_pred[:, :, 4:])
loc_loss = self._l1_smooth_loss(y_true[:, :, :4],
y_pred[:, :, :4])
pos_loc_loss = torch.sum(loc_loss * y_true[:, :, -1],
axis=1)
pos_conf_loss = torch.sum(conf_loss * y_true[:, :, -1],
axis=1)
num_pos = torch.sum(y_true[:, :, -1], axis=-1)
num_neg = torch.min(self.neg_pos_ratio * num_pos, num_boxes - num_pos)
# 找到了哪些值是大于0的
pos_num_neg_mask = num_neg > 0
has_min = torch.sum(pos_num_neg_mask)
num_neg_batch = torch.sum(num_neg) if has_min > 0 else self.negatives_for_hard
confs_start = 4 + self.background_label_id + 1
confs_end = confs_start + self.num_classes - 1
max_confs = torch.sum(y_pred[:, :, confs_start:confs_end], dim=2)
max_confs = (max_confs * (1 - y_true[:, :, -1])).view([-1])
_, indices = torch.topk(max_confs, k = int(num_neg_batch.cpu().numpy().tolist()))
neg_conf_loss = torch.gather(conf_loss.view([-1]), 0, indices)
# 进行归一化
num_pos = torch.where(num_pos != 0, num_pos, torch.ones_like(num_pos))
total_loss = torch.sum(pos_conf_loss) + torch.sum(neg_conf_loss) + torch.sum(self.alpha * pos_loc_loss)
total_loss = total_loss / torch.sum(num_pos)
return total_lossbackbone使用vgg:
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512]
def vgg(pretrained = False):
layers = []
in_channels = 3
for v in base:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
# 19, 19, 512 -> 19, 19, 512
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
# 19, 19, 512 -> 19, 19, 1024
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
# 19, 19, 1024 -> 19, 19, 1024
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
model = nn.ModuleList(layers)
return model最后实现train.py,这里只提供部分代码,想看的后续我会发出来:
def main():
# 基础配置
config = {
"cuda": True,
"random_seed": 11,
"distributed": False,
"sync_bn": False,
"fp16": False,
"classes_path": 'model_data/my.txt',
"model_path": '',
"input_shape": [300, 300],
"backbone": "vgg",
"pretrained": False,
"anchors_size": [30, 60, 111, 162, 213, 264, 315],
"init_epoch": 0,
"freeze_epoch": 50,
"freeze_batch_size": 16,
"unfreeze_epoch": 60,
"unfreeze_batch_size": 8,
"freeze_train": True,
"init_lr": 2e-3,
"min_lr": 2e-5,
"optimizer_type": "sgd",
"momentum": 0.937,
"weight_decay": 5e-4,
"lr_decay_type": 'cos',
"save_period": 10,
"save_dir": 'logs',
"eval_flag": True,
"eval_period": 10,
"num_workers": 4,
"train_annotation_path": '2007_train.txt',
"val_annotation_path": '2007_val.txt'
}
# 设置随机种子
seed_everything(config["random_seed"])
# 确定设备
device = torch.device('cuda' if torch.cuda.is_available() and config["cuda"] else 'cpu')
# 获取类别和模型参数
class_names, num_classes = get_classes(config["classes_path"])
num_classes += 1 # 背景类
anchors = get_anchors(config["input_shape"], config["anchors_size"], config["backbone"])
# 初始化模型
model = SSD300(num_classes, config["backbone"], config["pretrained"]).to(device)
if config["model_path"] != '':
model.load_state_dict(torch.load(config["model_path"], map_location=device))
if config["pretrained"]:
download_weights(config["backbone"])
# 准备数据集
train_dataset = SSDDataset(config["train_annotation_path"], config["input_shape"], anchors, config["freeze_batch_size"], num_classes)
val_dataset = SSDDataset(config["val_annotation_path"], config["input_shape"], anchors, config["freeze_batch_size"], num_classes)
train_loader = DataLoader(train_dataset, batch_size=config["freeze_batch_size"], shuffle=True, num_workers=config["num_workers"])
val_loader = DataLoader(val_dataset, batch_size=config["freeze_batch_size"], shuffle=False, num_workers=config["num_workers"])
# 设置优化器和学习率调度器
optimizer = optim.SGD(model.parameters(), lr=config["init_lr"], momentum=config["momentum"], weight_decay=config["weight_decay"])
lr_scheduler = get_lr_scheduler(config["lr_decay_type"], config["init_lr"], config["min_lr"], config["unfreeze_epoch"])
# 训练和验证
for epoch in range(config["init_epoch"], config["unfreeze_epoch"]):
# 训练一个epoch...
# 验证...
# 调整学习率...
print(f'Epoch {epoch}/{config["unfreeze_epoch"] - 1} finished.')
# 保存模型
if epoch % config["save_period"] == 0 or epoch == config["unfreeze_epoch"] - 1:
torch.save(model.state_dict(), os.path.join(config["save_dir"], f"model_epoch_{epoch}.pth"))
if __name__ == "__main__":
main()想要训练自己的数据集,可以写一个这样的读取标注信息代码:
import os
import random
import xml.etree.ElementTree as ET
import numpy as np
from utils.utils import get_classes
annotation_mode = True
classes_path = 'model_data/my.txt'
trainval_percent = 0.8
train_percent = 0.8
VOCdevkit_path = 'VOCdevkit'
VOCdevkit_sets = [('2007', 'train'), ('2007', 'val')]
classes, _ = get_classes(classes_path)
photo_nums = np.zeros(len(VOCdevkit_sets))
nums = np.zeros(len(classes))
def convert_annotation(year, image_id, list_file):
in_file = open(os.path.join(VOCdevkit_path, 'VOC%s/Annotations/%s.xml' % (year, image_id)), encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('shapes'):
cls = obj.find('label/value').text
if cls not in classes:
continue
cls_id = classes.index(cls)
bboxes = []
point_elems = obj.findall('points/value')
if len(point_elems) == 2:
point1_str = point_elems[0].text
point2_str = point_elems[1].text
if point1_str and point2_str:
point1 = [float(x) for x in point1_str.strip('[]').split(', ')]
point2 = [float(x) for x in point2_str.strip('[]').split(', ')]
x1, y1 = point1
x2, y2 = point2
bboxes.append((int(x1), int(y1), int(x2), int(y2)))
else:
print(f"Empty points found for object {cls} in image {image_id}")
else:
print(f"Unexpected number of points for object {cls} in image {image_id}")
if bboxes:
for bbox in bboxes:
list_file.write(" " + ",".join([str(a) for a in bbox]) + ',' + str(cls_id))
nums[classes.index(cls)] = nums[classes.index(cls)] + 1
else:
print(f"No valid points found for object {cls} in image {image_id}")
if __name__ == "__main__":
random.seed(0)
if " " in os.path.abspath(VOCdevkit_path):
raise ValueError("数据集存放的文件夹路径与图片名称中不可以存在空格,否则会影响正常的模型训练,请注意修改。")
if annotation_mode:
print("在ImageSet中生成txt")
xmlfilepath = os.path.join(VOCdevkit_path, 'VOC2007/Annotations')
saveBasePath = os.path.join(VOCdevkit_path, 'VOC2007/ImageSets/Main')
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("train size", tr)
ftrainval = open(os.path.join(saveBasePath, 'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("Done.")
if annotation_mode:
print("生成训练用的2007_train.txt and 2007_val.txt")
type_index = 0
for year, image_set in VOCdevkit_sets:
image_ids = open(os.path.join(VOCdevkit_path, 'VOC%s/ImageSets/Main/%s.txt' % (year, image_set)),
encoding='utf-8').read().strip().split()
list_file = open('%s_%s.txt' % (year, image_set), 'w', encoding='utf-8')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg' % (os.path.abspath(VOCdevkit_path), year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
photo_nums[type_index] = len(image_ids)
type_index += 1
list_file.close()
print("Done.")
def printTable(List1, List2):
for i in range(len(List1[0])):
print("|", end=' ')
for j in range(len(List1)):
print(List1[j][i].rjust(int(List2[j])), end=' ')
print("|", end=' ')
print()
str_nums = [str(int(x)) for x in nums]
tableData = [
classes, str_nums
]
colWidths = [0] * len(tableData)
len1 = 0
for i in range(len(tableData)):
for j in range(len(tableData[i])):
if len(tableData[i][j]) > colWidths[i]:
colWidths[i] = len(tableData[i][j])
printTable(tableData, colWidths)
if photo_nums[0] <= 500:
print("训练集数量小于500,属于较小的数据量,请注意设置较大的训练世代(Epoch)以满足足够的梯度下降次数(Step)。")步骤和YOLO系列差不多,提供.XML文件和数据集,然后修改.txt文件,指引模型读取信息,就可以训练了。
官方代码地址:GitHub - weiliu89/caffe at ssd
以上为所有内容!















 3113
3113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









