









目录
Tess4j OCR图像识别框架集成
Tesseract, 一款由HP实验室开发由Google维护的开源 OCR(Optical Character Recognition , 光学字符识别)引擎, 与Microsoft Office Document Imaging(MODI)相比, 我们可以不断的训练的库,使图像转换文本的能力不断增强; 如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
Tess4J 是Java (JNA) 对 Tesseract OCR API 的封装。
1.使用
创建java项目。引入maven依赖
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>2.下载源码包
中文库地址:tessdata/chi_sim.traineddata at main · tesseract-ocr/tessdata · GitHub
点击download 保存到E盘

其他语言包地址:https://github.com/tesseract-ocr/tessdata
3.引用语言包
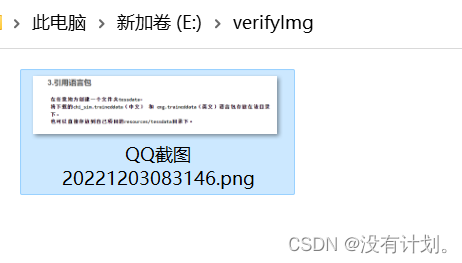
在任意地方创建一个文件夹tessdata, 将下载的chi_sim.traineddata(中文) 和 eng.traineddata(英文)语言包存放在该目录下, 也可以直接存放到自己项目的resources/tessdata目录下。
这里我放到了e盘下。
4.代码示例
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
/**
* @author :c
**/
public class Tess4jDemo {
public static void main(String[] args) throws TesseractException {
final ITesseract instance = new Tesseract();
instance.setDatapath("E:\\tessdata");
instance.setLanguage("chi_sim");
File imageLocation = new File("E:\\verifyImg");
for(File image : imageLocation.listFiles()){
System.out.println(image.getName()+" -->"+instance.doOCR(image));
}
}
}
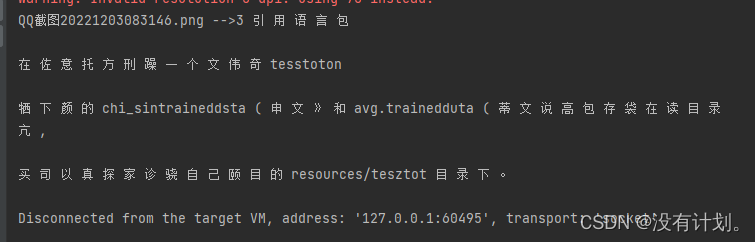
5.效果
我们随便截一张图片保存到代码指定目录中:E:\verifyImg

运行结果
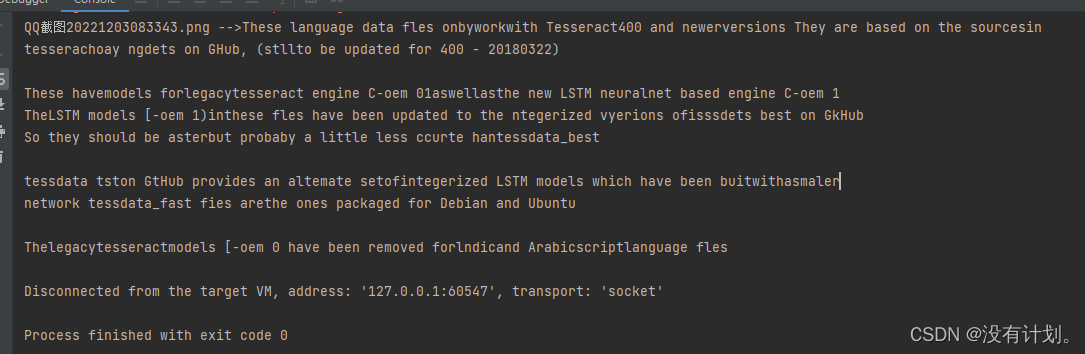
英文 测试

运行结果
















 6644
6644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









