






springboot 使用Tess4J实现OCR图片文字识别
一、Tess4J介绍
Tesseract是一个开源的光学字符识别(OCR)引擎,它可以将图像中的文字转换为计算机可读的文本。支持多种语言和书面语言,并且可以在命令行中执行。它是一个流行的开源OCR工具,可以在许多不同的操作系统上运行。
Tess4J是一个基于Tesseract OCR引擎的Java接口,可以用来识别图像中的文本,说白了,就是封装了它的API,让Java可以直接调用。
二、使用步骤
1.引入Maven库
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.3.0</version>
</dependency>
2.安装软件
比如我这里是下载后放到了F盘的tessdata/tessdata目录下,如图所示,其实就是一个.traineddata为后缀的文件,大小约2M多。
训练数据,官方下载地址:https://digi.bib.uni-mannheim.de/tesseract/
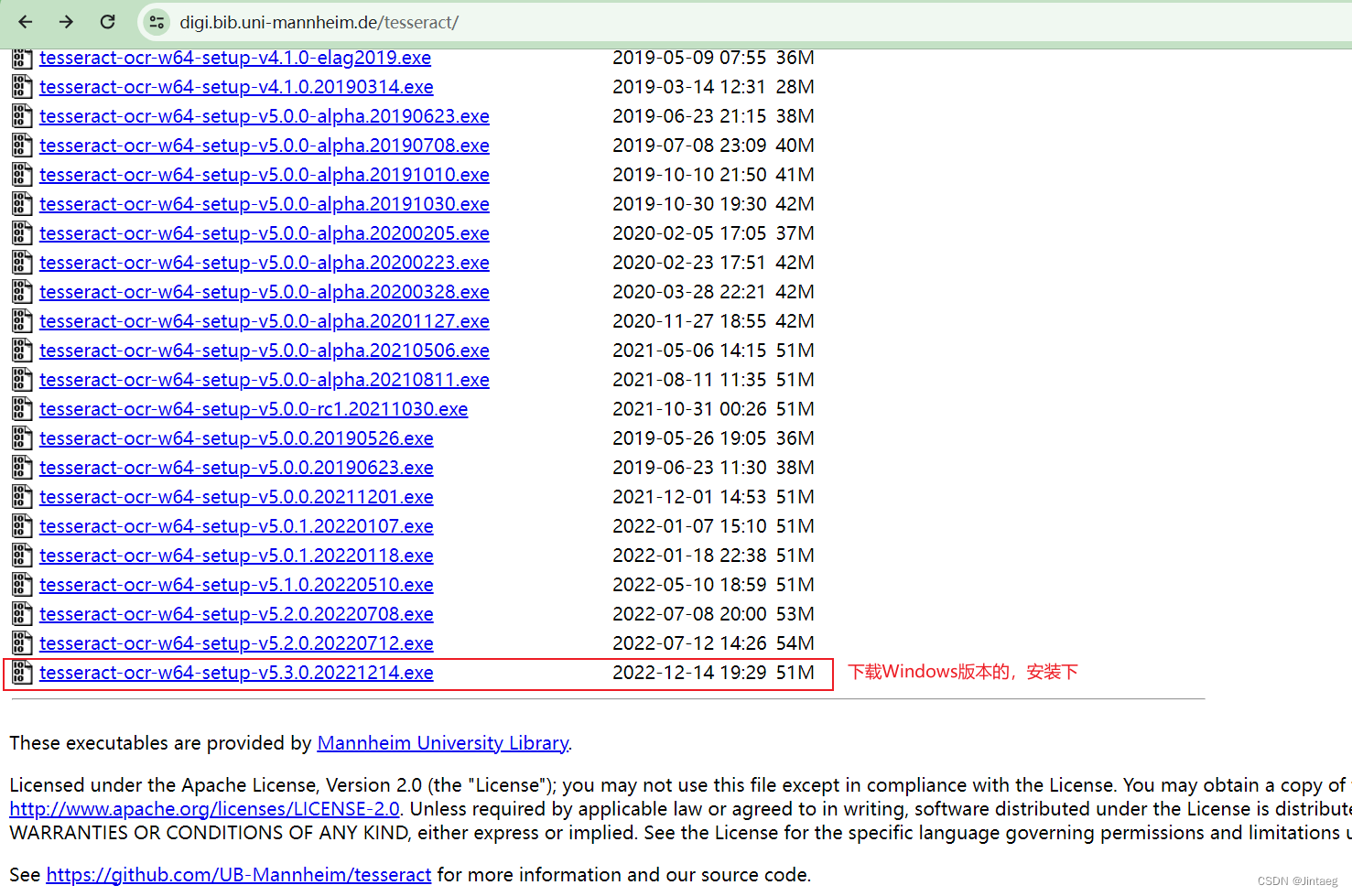
3.下载语言模型

4.示例代码
import net.sourceforge.tess4j.Tesseract;
import org.junit.platform.commons.util.StringUtils;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileInputStream;
import java.nio.file.Files;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TesseractTest {
public static void main(String[] args) {
String folderPath = "F:\\stock"; // 文件夹路径
File folder = new File(folderPath);
File[] files = folder.listFiles();
for (File file:files) {
String suffix = file.getName().substring(file.getName().lastIndexOf(".") + 1);
if (suffix.equals("png")) {
System.out.println("fileName:"+file.getName());
Tesseract tesseract = new Tesseract();
// 指定要读取的语言模型路经
tesseract.setDatapath("F:\\tessdata\\tessdata");
// 中文
tesseract.setLanguage("chi_sim");
String result = null ;
try {
// 读取图片文件
FileInputStream stream = new FileInputStream(file);
BufferedImage bufferedImage = ImageIO.read(stream);
result = tesseract.doOCR(bufferedImage);
System.out.println("result:"+result);
} catch (Exception e) {
System.out.println("ocrResult>>error: "+e.getMessage());
}
}
}
}
}
读取的结果与图片对比。


总结
总体使用下来还是可以的,能够应付大多数场景,但是精准度不是很高,需结合业务场景使用,有条件的可以使用阿里、百度、腾讯的ocr识别















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









