







 本文介绍PyTorch中梯度裁剪的方法,包括clip_grad_norm_和clip_grad_value_函数的使用,以及如何在训练循环中正确实施梯度裁剪,以避免梯度爆炸或消失。
本文介绍PyTorch中梯度裁剪的方法,包括clip_grad_norm_和clip_grad_value_函数的使用,以及如何在训练循环中正确实施梯度裁剪,以避免梯度爆炸或消失。
如果梯度超过阈值,那么就截断,将梯度变为阈值
from torch.nn.utils import clip_grad_norm
pytorch源码
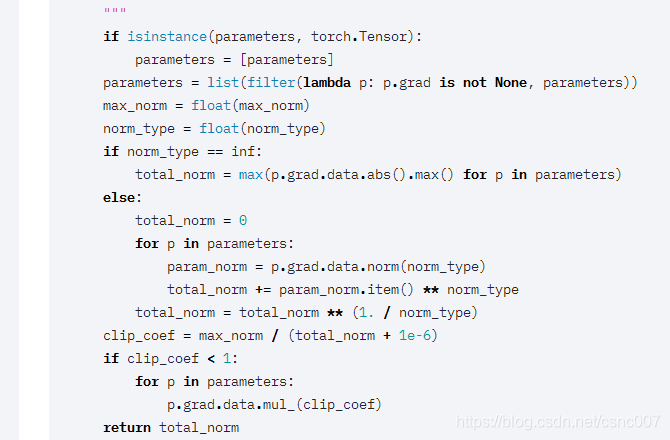
默认为l2(norm type)范数,对网络所有参数求l2范数,和最大梯度阈值相比,如果clip_coef<1,范数大于阈值,则所有梯度值乘以系数。
使用:
optimizer.zero_grad()
loss, hidden = model(data, hidden, targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
optimizer.step()python - How to properly do gradient clipping in pytorch? - Stack Overflow https://stackoverflow.com/questions/54716377/how-to-properly-do-gradient-clipping-in-pytorch
但是,clip_grad_norm还不够狠,有时候失效,这个时候更狠的就出来了:
torch.nn.utils.clip_grad_value_(model.parameters(), number)

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









