



1. BIRCH 算法概述
BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)聚类算法聚类特征树(Clustering Feature Tree,CF Tree)来帮助快速地聚类。该算法由Wisconsin-Madison大学 Tian Zhang博士于1996年提出,该算法在处理数据样本较多的大数据集时,能够以低成本的内存消耗,完成高质量的聚类。
2.算法原理与步骤
BIRCH算法采用B-树的思想实现,这棵树的每一个节点是由若干个聚类特征(Clus- tering Feature,CF)组成。算法的核心是聚类特征,CF-Tree由CF组成,每个CF可以定义为一个三元组
CF=(n,LS,SS)
聚类特征本质上是给定簇的统计汇总,可以有效地对数据进行压缩,而且基于聚类特可以很容易推导出簇的许多统计量和距离度量。
聚类特征本质上是给定簇的统计汇总。使用聚类特征,可以很容易推导出簇的许多有用的统计量。
例如,簇的形心xo、半径R和直径D,如图所示。
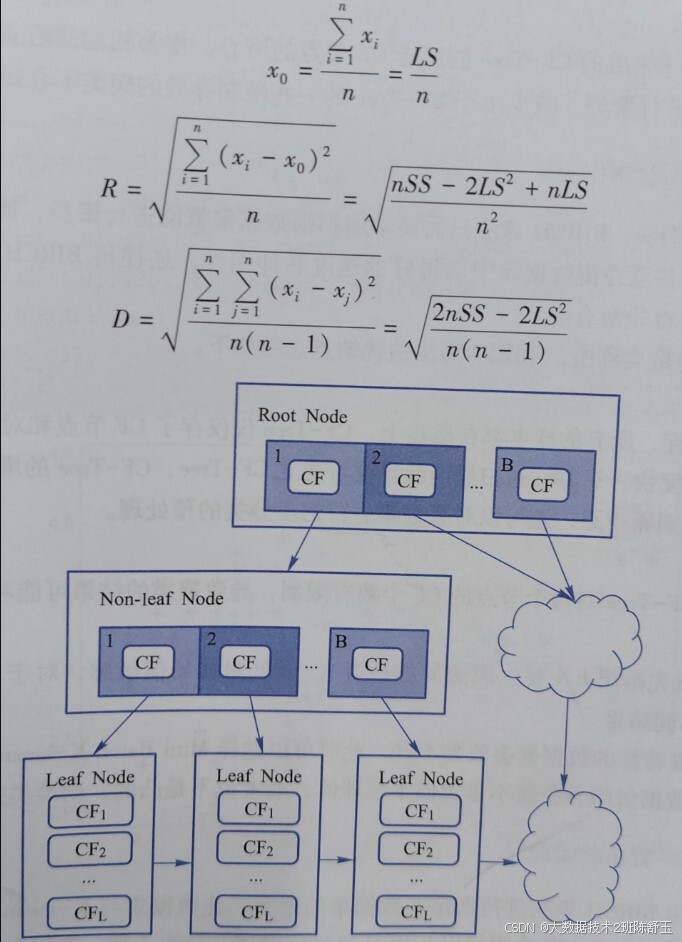
BIRCH 主要包括两个阶段:
阶段 1:BIRCH读取数据样本,在内存中建立初始CF-Tree,保留数据的内在聚类结构。
阶段2:BIRCH采用某个(选定的)聚类算法对CF-Tree的叶结点进行聚类,把稀疏的簇当作离群点删除,而把稠密的簇合并为更大的簇。该阶段可使用任意聚类算法。 BIRCH算法的主要步骤描述如下:
①读取样本,在内存中建立一棵CF-Tree。
② 将第一步建立的CF-Tree进行筛选,去除异常节点。
③利用其他聚类算法(如K-means)对所有的CF元组进行聚类,得到一棵比较好的CF-Tree,消除由于样本读人顺序导致的不合理的树结构,以及一些由于节点CF个数限制导致的树结构分裂。
④利用步骤③生成的CF-Tree的所有CF节点的质心,作为初始质心点,对所有的样本点按距离远近进行聚类。减少由于CF-Tree的一些限制导致的聚类不合理的情况。
3.BIRCH 算法适用场景
借助于CF-Tree,BIRCH算法只需要单遍扫描数据集就能进行聚类,同时帮助聚类方法在大型数据库甚至在流数据库中取得好的速度和伸缩性,还使得BIRCH方法对新对象增量或动态聚类也非常有效。相对于其他聚类算法,BIRCH算法的优缺点总结如下。
(1)优点
①节约内存,所有的样本都在磁盘上,CF-Tree仅仅存了CF节点和对应的指针。
②聚类速度快,只需一遍扫描训练集就可建立CF-Tree,CF-Tree的增删改都很快。
③可以识别噪声点,还可以对数据集进行初步分类的预处理。
(2)缺点
①由于CF-Tree对每个节点的CF个数有限制,导致聚类的结果可能和真实的类别分布不同。
② 必须事先给出k(要生成的簇的数目),而且对初始值敏感,对于不同的初始值,可能会导致不同结果。
③对高维特征的数据聚类效果不好。此时可以选择MiniBatch K-means。
④ 如果数据集的分布簇不是类似于超球体,或者说不是凸的,则聚类效果不好。
4. BIRCH 算法的实现
使用BIRCH算法进行鸢尾花数据集的聚类,此数据集与K-means算法实验中的数据一致。同样,本小节希望利用BIRCH算法将鸢尾花分为3类,示例代码。
#引入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import Birch
from sklearn.metrics import calinski_harabaz_score 
#读取数据
data = pd.read_csv('iris.csv')
data.head()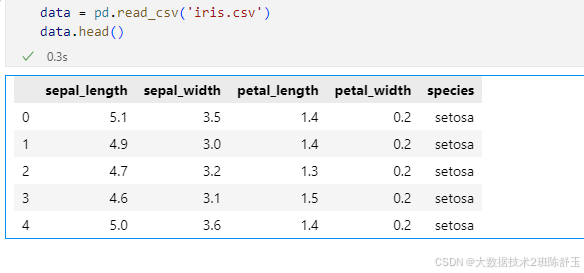
#describe,info看一下
data.describedata.info()
#切分
x = data[['sepal_length','sepal_width','petal_length','petal_width']].values
#构造模型,设置参数:类别数量为3
#模型训练(把x丢进去)
model = Birch(n_clusters=3)
model.fit(x)
#获取模型的聚类具体结果,(每个样本数据什么类别),把它保存在label_pred
label_pred = model.labels_
#画图看看聚类结果
x0 = x[label_pred==0]
x1 = x[label_pred==1]
x2 = x[label_pred==2]
#开始画图
plt.scatter(x0[:,0],x0[:,2],c='red',marker='o',label='cluster 1')
plt.scatter(x1[:,0],x1[:,2],c='green',marker='*',label='cluster 2')
plt.scatter(x2[:,0],x2[:,2],c='blue',marker='+',label='cluster 3')
plt.xlabel('sepal_length')
plt.ylabel('sepal_width')
plt.legend()
plt.show()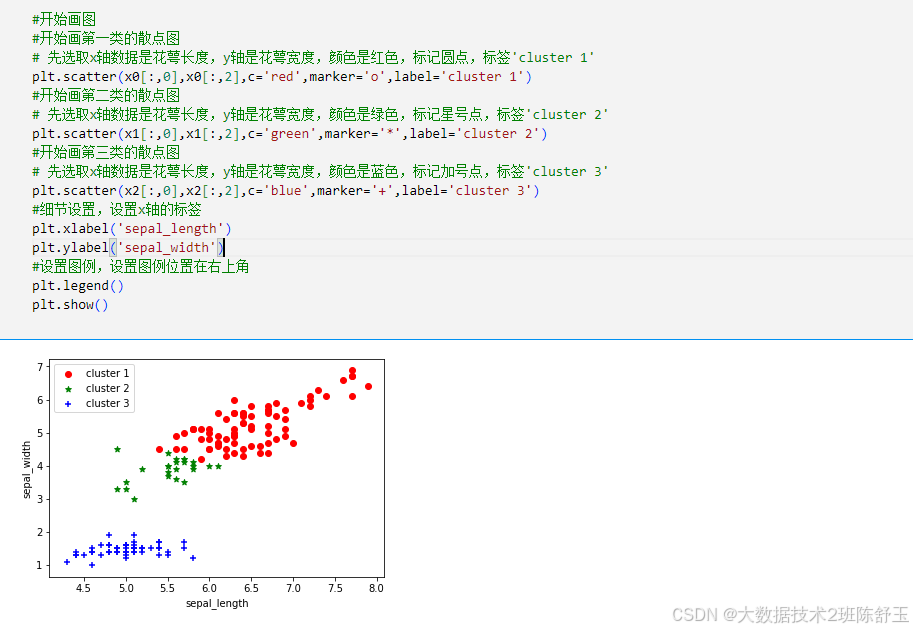
calinski_harabaz_score(x,label_pred)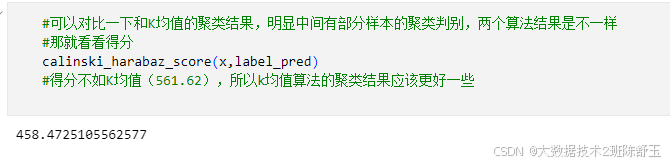

















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









