







1.shuffle过程介绍:
shuffle的本意是洗牌,混洗,是把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据
2.为什么MapReduce计算模型要需要shuflle过程?
我们都知道MapReduce计算模型包括两个重要的阶段:Map映射,负责数据的过滤分发,Reduce是规约,负责数据的合并和计算.Reduce的计算数据来源于Map, Map数据的输出是Reduce阶段的数据输入,Reduce阶段需要通过shuffle来获取数据,
我们从map阶段的数据输出到reduce阶段的数据输入整个过程可以广义称为shuffle, shuffle横跨Map端和Reduce端, 在map端进行split过程,在reduce端包括copy和sort过程, 如下图所示:
shuffle过程
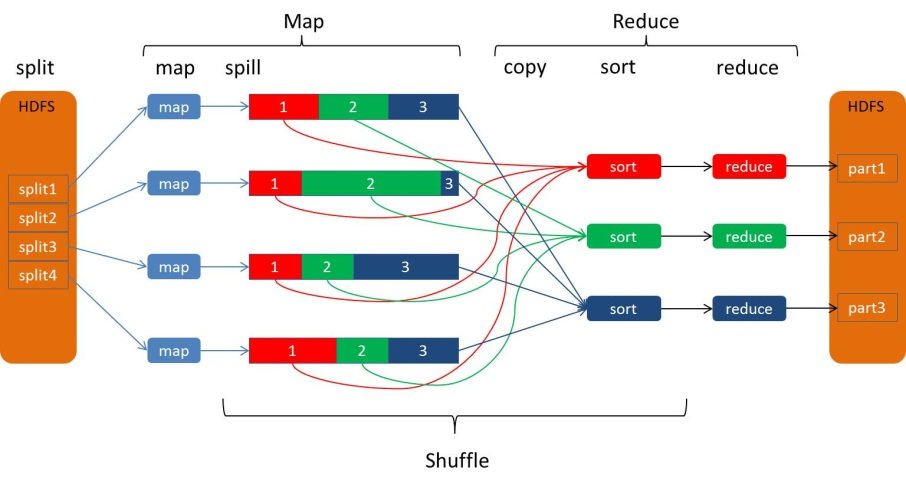
split过程
split过程包括输出,排序,
溢写、合并等步骤,其中如图所示:
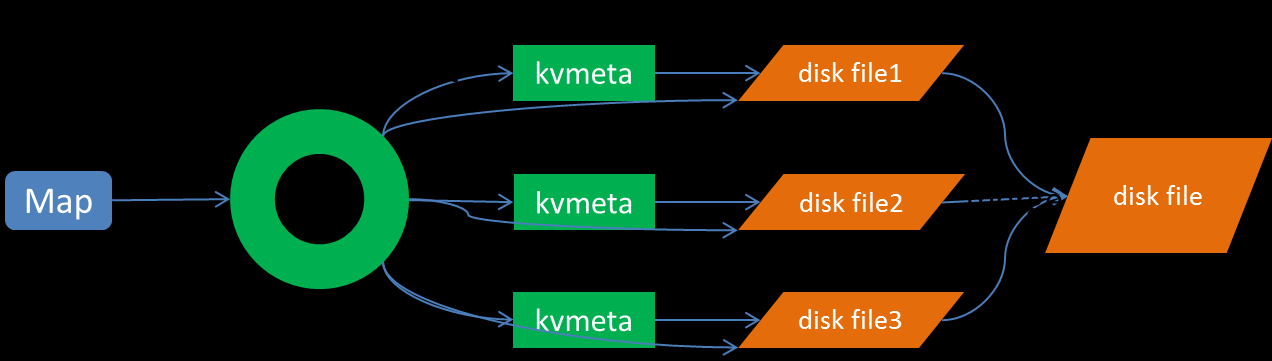
Collect过程
每个Map任务不断地以对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据
Sort过程
先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序
Spill过程
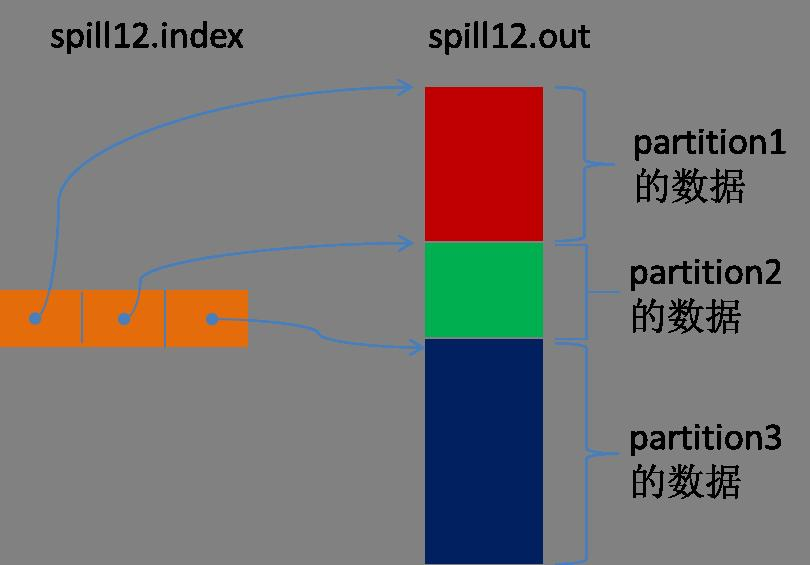
Spill线程为这次Spill过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out”的文件。Spill线程根据排过序的Kvmeta挨个partition的把数据吐到这个文件中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍历完。一个partition在文件中对应的数据也叫段(segment)。
所有的partition对应的数据都放在这个文件里,虽然是顺序存放的,但是怎么直接知道某个partition在这个文件中存放的起始位置呢?强大的索引又出场了。有一个三元组记录某个partition对应的数据在这个文件中的索引:起始位置、原始数据长度、压缩之后的数据长度,一个partition对应一个三元组。然后把这些索引信息存放在内存中,如果内存中放不下了,后续的索引信息就需要写到磁盘文件中了:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out.index”的文件,文件中不光存储了索引数据,还存储了crc32的校验数据。(spill12.out.index不一定在磁盘上创建,如果内存(默认1M空间)中能放得下就放在内存中,即使在磁盘上创建了,和spill12.out文件也不一定在同一个目录下。)
每一次Spill过程就会最少生成一个out文件,有时还会生成index文件,Spill的次数也烙印在文件名中。索引文件和数据文件的对应关系如下图所示:















 4528
4528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









