









再次看hadoop源码收集每一步使用到的参数用于后期调优
官网地址:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
计算切片大小规则:
Blocksize:一般是128M或者256M,本地跑MR是32M
ComputeSplitSize=Math.max(minSize, Math.min(maxSize, blockSize));
| 参数名 | 默认值 | 说明(或从官网) |
| mapreduce.input.fileinputformat.split.minsize | 1 | 映射输入的最小大小块应拆分为。请注意,某些文件格式可能具有最小分割大小,该大小优先于此设置。 |
| mapreduce.input.fileinputformat.split.maxsize |
| 最大切分块。单位字节 |
| mapreduce.input.fileinputformat.list-status.num-threads | 1 | 用于列出和获取指定输入路径的块位置的线程数。注意:如果使用自定义的非线程安全路径过滤器,则不应使用多个线程。(这个) |
| dfs.block.size/dfs.blocksize | 134217728B | 块大小 默认128M |
| mapreduce.job.maps | 2 | 每个作业的默认map任务数,当mapreduce.framework.name为本地时被忽略 |
| mapreduce.job.reduces | 1 | 每个作业的默认reduce任务数,当mapreduce.framework.name为本地时被忽略 |
| mapreduce.job.queuename | Default | 作业提交的队列,这必须与系统的mapred-queues.xml中定义的队列之一匹配。同样,队列的ACL设置必须允许当前用户向队列提交作业。在指定队列之前,请确保为系统配置了队列,并且允许访问以将作业提交到队列。 |
| mapreduce.map.memory.mb |
| Map任务需要的容器的内存大小 |
| mapreduce.task.io.sort.mb | 100 | 排序文件时需要使用的缓冲内存总量 |
| mapreduce.map.sort.spill.percent | 0.8 | 序列化缓冲区中的软限制,一旦到达,线程将开始将内容溢出到后台的磁盘中 |
| mapreduce.map.combine.minspills | 3 | map阶段溢出文件后调用merge合并文件,如果溢出文件超过3个,且聚合类不为null,则聚合后写入磁盘。代码如下: |
| mapreduce.map.output.compress | false | map输出是否压缩 |
| mapreduce.map.output.compress.codec | Org.apache.hadoop.io.compress.DefaultCodec | 压缩格式,默认defultCodec压缩方式 |
| mapreduce.task.io.sort.factor
| 10 | 排序文件时一次合并的流的数量。这确定了打开的文件句柄数量(maptask和reducetask都存在) |
| mapreduce.reduce.shuffle.input.buffer.percent | 0.70(reduce堆内存的百分之70)最大 | 在shuffle期间要从最大堆大小分配到存储map输出的内存百分比(shuffle的复制阶段,从map阶段输出的结果复制到reduce内存,用来存放map输出缓冲区占reduce堆内存的百分比) |
| mapreduce.reduce.shuffle.memory.limit.percent | 0.25 | 单个shuffle可以消耗的内存限制的最大百分比。有效值[0.0,1.0],如果值为0.0,则将map输出的直接该写到磁盘(比如5个map,reduce获取每个map分区的数据大小如果超过该阈值,则直接写入到磁盘) |
| mapreduce.reduce.shuffle.merge. percent | 0.66 | 初始化内存中的使用阈值,map输出缓冲区的阈值,超过该比例将进行合并和溢写磁盘。比如在reduce阶段,用于存放map输出的内存为500M,那么当内存达到500*0.66=330M,会触发合并写入。(这个阈值是对读取所有map的分区数到内存的总和,如果总和超过0.66,则sort并执行combiner后溢写到磁盘) |
| mapreduce.reduce.shuffle.parallelcopies | 5 | 在shuffle的copy阶段,默认的并行传输数由reduce运行 |
| mapreduce.reduce.input.buffer.percent | 0.0 | 在reduce过程中,内存中保存map输出的空间占整个堆空间的比例。默认情况下,reduce任务开始前所有的map输出合并到磁盘,以便reduce提供尽可能多的内存。如果reduce需要的内存较少,可以增加此值以最小化磁盘访问次数。如果这个参数大于0,就会有一定量的数据被缓存在内存并输送到reduce |
| mapreduce.reduce.merge.memtomem.enabled | false | 是否开启内存到内存的合并 |
| mapreduce.reduce.merge.memtomem. threshold | 10 |
|
| mapreduce.reduce.memory.mb |
| Reduce任务的容器大小 |


(map阶段调用merge合并文件的时候,超过默认的3个文件并且combiner类不为null)

Map阶段合并排序阈值。

(如果读取map端输出的文件内容size大小与maxSingleShuffleLimit作对比,如果超过配置的mapreduce.reduce.shuffle.memory.limit.percent的大小,则写入磁盘,反之读入到内存中,在读入内存的同时,也是会写入到文件中,文件名为:map_0.out.merged,如果当前reduce任务执行完毕,则清楚该文件(目的是为了防止reduceTASK出现任务,再次分配的时候可以直接从文件中读取到内存,不需要再去从map输出文件中拉取文件写入。),在调用OnDiskMapOutput()写入磁盘,会产生临时文件tmpPath路径,文件名为map_0.out1。
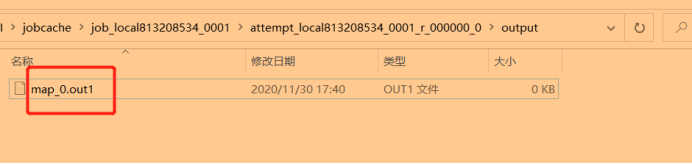
如果写入到磁盘的文件数大于等于(2*ioSortFactor -1)则开始合并

)

(判断已使用的内存是否大于内存限制,如果已使用小于内存限制,则允许shuffle在内存中进行。内存限制由配置mapreduce.reduce.shuffle.input.buffer.percent控制)

(在最后读取从map输出的结果到内存后,然后调用closeInMemoryFile()的方法,以为只是关闭些资源,一看,也是有些内涵的。在第1步,判断commitMemory提交的内存(也就是该reducetask任务中所有获取map输出的内容的总内存大小),如果大于等于配置的mergeThreshold(该值由mapreduce.reduce.shuffle.merge.percent*memoryLimit)的大小,则开启合并操作。如果小于,并且memTomerge不为null,则第2步,判断如果inMemoryMapOutput.size()大于等于memToMemMergeOutputsThreshold(由mapreduce.reduce.merge.memtomem.threshold)的值 ,则开始启动memTomem合并操作。)
在类:MergeManagerImpl的方法finalMerge,最后合并方法中,方法段讲解:

(getMaxInMemReduceLimit()方法获取reduce端的内存限制,由配置mapreduce.reduce.input.buffer.percent * (reduceJVM * mapreduce.reduce.shuffle.input.buffer.percent) 计算得到内存大小,默认为0.0,如果默认,则内存中的数据以及磁盘文件不超过ioSortFactory,那么内存的数据都会spill到磁盘中,如果设置1.0,如果内存很多,可以设置为1.0,那么就会将内存中的数据直接输入到reduce函数作为reduce方法的输入)

InMemory在内存中存在读取map数据的分区数据,并且溢写到spill到磁盘的文件数小于配置的ioSortFactor值,则将内存中的数据必须spill到磁盘中,以下图就是spill后的效果。
1代表是超过单个shuffle的阈值然后直接spill到磁盘,磁盘文件名:map_0.out。
2代表就是内存中在最后必须spill到磁盘,生成的文件名为:map_1.out.merged。

并且最后将两个文件一起做最后的合并sortandspill。
















 214
214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









