







深度学习的优化方法包括SGD、SGD with momentum(动量)、Adagrad、RMSProp、Adam
为什么要优化?
做优化的目的是找到在使用traning data时,找到的模型的参数使得Loss最小。
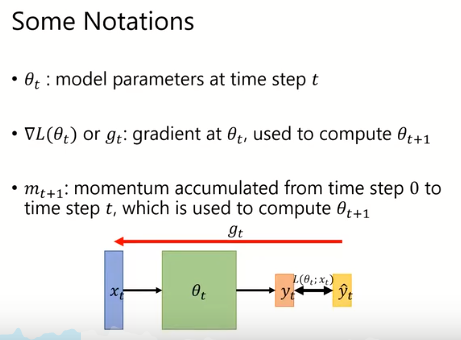
mt+1包含了时间段从0到t内的计算得到的gradient。(并不是完全的gradient,进行了某些改进)。
图中为普通的神经网络架构。xt表示在第t个time step上输入的变量,θt表示在第t个time step上模型的参数,yt表示在第t个time step上模型得到的预测值。再通过与正确值计算得到LOSS,计算梯度找到最小的θ。这个是ON-LINE的模型。(在一个时间段内只输入一个样本训练)。
OFF-LINE
在一个time step里用全部的样本数据来计算(但不是之前的gradient descent,不是将所有的样本累加得到Loss,而是在同一个时刻将所有样本放进去模型计算得到不同的yt)。这种的会面临一个问题,就是计算的时候没有那么大的基底空间或资源。
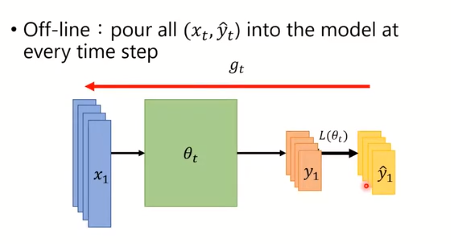
在这里假设我们用的是off-line,且不考虑遇到的问题。因为这种的在训练模型时一次可以看到全部样本数据。
SGD
原有的对Linear Regression计算Loss的方法是将所有的sample数据计算之后加和,,才做梯
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









