







紧接着上一章节的线性回归,这一周学习下逻辑回归。同样参照的资料斯坦福大学2014(吴恩达)机器学习教程中文笔记
那本文的知识体系如下:
基本知识点
定义
而线性回归 y i = w i ∗ x i + b y_{i} = w_{i}*x_{i} + b yi=wi∗xi+b,模型的范围是可以为$\left { -∞,+∞ \right } , 线 性 回 归 能 预 测 连 续 的 值 , 然 而 对 于 分 类 问 题 , 我 们 的 因 变 量 可 能 属 于 两 个 类 别 正 向 类 和 负 向 类 , 即 ,线性回归能预测连续的值,然而对于分类问题,我们的因变量可能属于两个类别正向类和负向类,即 ,线性回归能预测连续的值,然而对于分类问题,我们的因变量可能属于两个类别正向类和负向类,即y\in \left { 0,1\right } , 我 们 可 以 设 置 某 个 阈 值 来 进 行 划 分 , 那 这 个 阈 值 怎 么 选 择 呢 , 是 不 太 好 选 择 的 。 那 么 我 们 就 需 要 引 入 一 个 函 数 ,我们可以设置某个阈值来进行划分,那这个阈值怎么选择呢,是不太好选择的。那么我们就需要引入一个函数 ,我们可以设置某个阈值来进行划分,那这个阈值怎么选择呢,是不太好选择的。那么我们就需要引入一个函数g(x) , 将 模 型 的 输 出 变 量 范 围 控 制 在 ,将模型的输出变量范围控制在 ,将模型的输出变量范围控制在\left [ 0,1 \right ] , 所 以 逻 辑 回 归 的 模 型 假 设 是 : ,所以逻辑回归的模型假设是: ,所以逻辑回归的模型假设是:h_{\theta } (x)=g(\theta ^{T}X) , 其 中 ,其中 ,其中X 表 示 特 征 向 量 , 表示特征向量, 表示特征向量,g 表 示 逻 辑 函 数 , 常 用 的 逻 辑 函 数 是 s i g m o i d 函 数 表示逻辑函数,常用的逻辑函数是sigmoid函数 表示逻辑函数,常用的逻辑函数是sigmoid函数g(z)=\frac{1}{1+e^{-z} } $
所以逻辑回归的表达是:
h
θ
(
x
)
=
P
(
y
=
1
∣
x
;
θ
)
=
1
1
+
e
−
θ
T
X
h_{\theta } (x)=P(y=1|x;\theta)= \frac{1}{1+e^{-\theta ^{T} X} }
hθ(x)=P(y=1∣x;θ)=1+e−θTX1
即:给定x,通过已经确定的参数计算得到
h
θ
(
x
)
=
0.7
h_{\theta } (x)=0.7
hθ(x)=0.7,则表示有70%的概率y为正向类,相应地y为负向类的概率为30%.
解决哪些问题:
在分类问题中,我们尝试预测的是结果是否属于某一个类(例如正确或错误)。分类问题的例子有:判断一封电子邮件是否是垃圾邮件;判断一次金融交易是否是欺诈;之前我们也谈到了肿瘤分类问题的例子,区别一个肿瘤是恶性的还是良性的。
分类问题实际上就是找到一个足够优秀的判定边界。

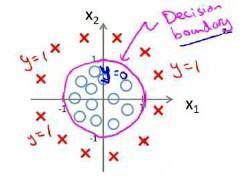
代价函数
逻辑回归的代价函数:
J
(
θ
)
=
1
m
C
o
s
t
(
h
θ
(
x
(
i
)
,
y
(
i
)
)
J(\theta )=\frac{1}{m}Cost(h_{\theta }(x^{(i)} ,y^{(i)} )
J(θ)=m1Cost(hθ(x(i),y(i))
其中:

其中
h
θ
(
x
)
h_{\theta }(x)
hθ(x)与$Cost(h_{\theta }(x ,y)) $的关系图如下:
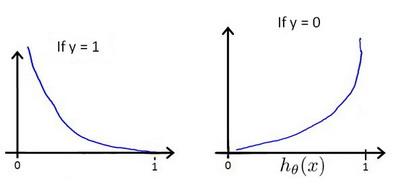
这样的话构造的$Cost(h_{\theta }(x ,y)) 函 数 的 特 点 是 : 当 实 际 函数的特点是:当实际 函数的特点是:当实际y=1 且 且 且h_{\theta }(x) 也 为 1 时 误 差 为 0 , 当 也为1时误差为0,当 也为1时误差为0,当y=1 但 但 但h_{\theta }(x) 不 为 1 时 误 差 随 着 不为1时误差随着 不为1时误差随着h_{\theta }(x) 的 变 小 而 变 大 ; 当 实 际 的 的变小而变大;当实际的 的变小而变大;当实际的y=0 且 且 且h_{\theta }(x) 也 为 0 时 代 价 为 0 , 当 也为0时代价为0,当 也为0时代价为0,当y=0 且 且 且h_{\theta }(x) 不 为 0 时 , 误 差 随 着 不为0时,误差随着 不为0时,误差随着h_{\theta }(x)$的变大而变大。
最后简化得到:
J
(
θ
)
=
1
m
∑
i
=
1
m
[
−
y
(
i
)
log
(
h
θ
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
log
(
1
−
h
θ
(
x
(
i
)
)
)
]
J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}
J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]
接着我们就可以使用梯度下降算法,对该代价函数求解最优值。
推导
推导过程在原始笔记中记录的十分详细,如下图:
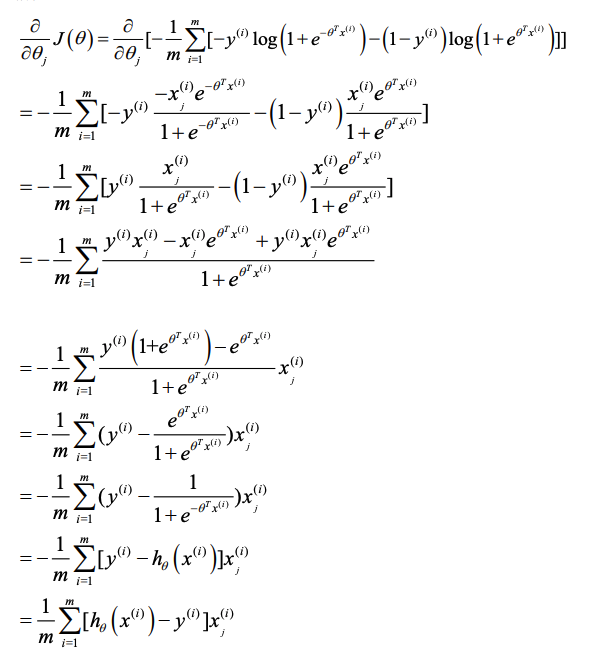
所以如果要更新参数的话,应该是通过如下式子进行更新:

与线性回归的异同
- 线性回归只能用于回归问题,逻辑回归虽然名字叫回归,但是更多用于分类问题
- 线性回归要求因变量是连续性数值变量,而逻辑回归要求因变量是离散的变量
- 线性回归与逻辑回归其梯度下降算法进行参数更新的规则是一致的,都是 θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) {\theta_j}:={\theta_j}-\alpha \frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}}){x_{j}}^{(i)}} θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i),但是线性回归与逻辑回归的表达式不太一致,线性回归的表达式为: h θ ( x ) = θ T X = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n {h_\theta}\left( x \right)={\theta^T}X={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}} hθ(x)=θTX=θ0x0+θ1x1+θ2x2+...+θnxn。而逻辑回归的表达式为: h θ ( x ) = 1 1 + e − θ T X {h_\theta}\left( x \right)=\frac{1}{1+{{e}^{-{\theta^T}X}}} hθ(x)=1+e−θTX1,所以线性回归与逻辑回归的梯度下降实际上是两个完全不同的东西。
逻辑回归的优缺碘
优点:
-
实现简单,广泛的应用于工业问题上;
-
分类时计算量非常小,速度很快,存储资源低;
-
便利的观测样本概率分数;
-
对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
-
计算代价不高,易于理解和实现;
缺点: -
当特征空间很大时,逻辑回归的性能不是很好;
-
容易欠拟合,一般准确度不太高
-
不能很好地处理大量多类特征或变量;
-
只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
-
对于非线性特征,需要进行转换;
面试考点
为何使用sigmoid函数
由于对最大熵模型以及一些分布不是很了解,我这边先补充一些来学习链接
解释logistic回归为什么要使用sigmoid函数
为什么 LR 模型要使用 sigmoid 函数,背后的数学原理是什么?
为何不继续使用均方误差作为代价函数
因为使用均方误差作为逻辑回归的代价函数,得到的代价函数是非凸函数,代价函数非凸就会影响梯度下降算法寻找全局最小值,可能会找到局部最小值
















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









