









这个是周志华老师的机器学习书里面的公式,表明如果基础分类器是弱分类器的 情况下,集成之后效果的效果会更好,因为我们从公式中可以看到,基分类器的数目T增长的时候,错误率是指数级下降的。
这个公式是怎么来的呢? 这个是周志华老师机器学习里的课后习题,现在咱们就来证明一下


到此我们对集成的直观理解是,如果我们有很多基分类器,他们之间独立,让他们各自预测之后,通过投票产生结果,如果数量足够多,那我们正确的概率会非常大
#AdaBoosting
AdaBoosting的主要思想是仍然是很多个弱分类器的相加,而各个分类器之间有相继产生的。
在李航老师的书里是这样解释:Adaboost的做法是,提高那些被前一轮弱分类器错误分类的样本的全职,而降低那些被正确分类的样本的权值。这样以来,那些没有得到正确分类的数据,由于其权值的加大到后一轮收到受到更大的关注。于是,分类问题被一些列的弱分类器分而治之。
在这里我总结一下我对Adaboost的整体理解。我们在用Adaboost的时候,我们根本上用的指标是让错误的期望最小化,这样做的原因是我们可以通过改变样本的权重去调整样本的分布,这样就让那些错误分类的样本得到更大的关注成为可能。
而有的人说Adaboost是做两件事情,一个是改变样本分布,让错误分类的样本得到更多的关注,一个是给那些正确率高的分类更高的权重,让他们在决策起到更大的作用。而后一句话准确来说,并不准确。因为那些正确率高的分类器是在改变权重的样本上有很高的准确率,在原数据上会不会有很高的准确率,这个是未知的,而我们的公式推导确实是给那些正确率高的分类器更高的权重,这个我更愿意把他解释为偶然。
其实Adaboost方法,本质是对指数损失函数期望最小化的问题,至于改变样本分布,调整分类器的权重其实都是副产品,只是为了方便人们理解而作的直观解释而已。
Adaboost的推导,我个人是非常喜欢周志华老师那本书里的推导,公司简洁,清晰。现在让我们就跟随周志华老师的思想,去理解Adaboost。
首先我们来看看什么是指数损失函数。

这个从直观的理解就能知道,如果f(x) 和 H(x)的值是相同,那么这个损失函数的值也会跟着变小。
而周志华老师是从公式推导,而不是像我这里用直观去表述。周志华老师最后推得的是这个公式

看到这里,读者能明白公式是怎么推导来的,同时明白:哦,指数损失函数是可以用的就OK了。
接下来,我们就来看看,针对一个基分类器,我们应该给他一个什么样的权重比较合适。

从这个公式中我们可以看到,错误越小,他的权重就这个公式结果就越大,也就是分类器的权重越大。但是我们知道,这个表达式的由来,其实是在每个新的样本分布中,为了追求最小化期望指数损失函数,求导等于零得来得。
以上我们及给出了怎么确定每个分类器得权重,现在我们再来看看怎么改变样本得分布概率。
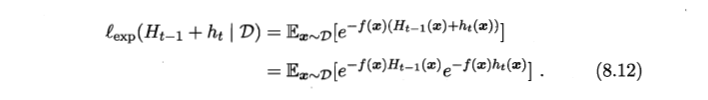
这个公式表示得意思是我们,我们已经训练了t-1个分类器,我们再寻来你第t个分类器得目标是,让第t分类器和前t-1个分类器相加,他们在原样本上的期望指数损失函数最小。这个是一个本质问题,然而我们接下来要把他转化为改变样本分布概率的问题。因为这样,算法就变成一个迭代问题,容易表示。(我的理解就是这样,就是为了容易在计算机上实现~~)



这些都是非常优美的数学公式了,如果有必要后续再更详细说明。

















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









