







可以看得出来,支持hostgw、udp、vxlan等模式,还支持跑在公有云上,如果用vxlan,那么内核必须支持。hostgw模式性能好,沒啥依赖,设置简单,不涉及到原始packet的封包和解包,它的思路是直接修改物理主机的路由表, 前提是要求多台物理主机必须在2层可达(必须在同一个网段内,可以直接通过mac地址就可以互相通信)
说到host-gw模式下什么叫物理主机通过mac地址就可以互相通信?AB要通信,A发arp报文得到B的mac地址,然后发出以太网报文,交换机就根据以太网报文中的目标mac地址,就可以把数据包发给B,这就叫通过mac地址通信,不涉及路由,不涉及到L3(IP层)
至于flannel的UDP模式是不建议使用的,纯粹是玩玩的,优先用vxlan和host-gw模式。
还有一个ipip模式,也是内核支持的一种隧道模式,很简单,开销很低,但是只能重新封包ipv4的单播报文。

要让flanneld进程跑起来,需要一个配置文件,默认从/etc/kube-flannel/net-conf.json读取,因为flannel是在整个k8s集群范围内管理pod的网络,所以第一个参数Network就确定整个pod的IP地址范围,很明显,下面的案例中的私有网络很大,可以容纳狂多的POD
{
"Network": "10.0.0.0/8",
"SubnetLen": 20,
"SubnetMin": "10.10.0.0",
"SubnetMax": "10.99.0.0",
"Backend": {
"Type": "udp",
"Port": 7890
}
}
 这是它的源码,没有思路直接看源码是徒劳无效的,所以先搞清楚flannel背后的设计思路以及相关的其他一些理论知识点。
这是它的源码,没有思路直接看源码是徒劳无效的,所以先搞清楚flannel背后的设计思路以及相关的其他一些理论知识点。
1、动态路由,如果是一个小网络,比如一家公司,几百号人,隔离出三五个、十来个网段,那么直接在路由器上配置静态路由就行了,大不了网管员辛苦一些,手动telnet到路由器上,敲命令,把一条一条路由规则敲进去呗,但是网络大了以后,或者说网络调整比较频繁的时候,靠人手动敲命令就不现实了,此时动态路由登场,比如OSPF,BGP,每个路由器只需要知道自己连着哪些网段即可,然后路由器之间交换信息,最终形成路由表,这就不需要人为介入了,实现了自动化
2、假设有10台主机,每个上面安装了docker,每个上面的dockerd进程会给每个容器分配IP,这特么会造成一个问题,主机上的容器的IP地址会重复,这就无法让容器跨物理主机通信了,比如AB两台物理主机上的容器的IP都是172.16.3.15,这还怎么通信
3、现在让flanneld来做这个IP地址分配的事情,它用到了etcd数据库,flaneld给每个物理主机分配了一个IP网段,然后修改dockerd的启动参数,加上--bip参数,这样的话,dockerd在创建容器的时候,就限制了容器的IP地址范围,也就是通过flanned间接获取到了全局唯一的IP地址,flanneld会把容器的IP地址存放在etcd数据库中

4、A、B2台物理机器上各有1个容器,IP分别是172.16.3.15、172.16.3.16,那究竟怎么跨主机通信呢?本来如果容器C1和C2都在同一个物理主机上的话,它们会链接到Linux的bridge桥上,这个bridge就相当于是一个交换机,那么自然可以通信,现在都跨主机了,而且我们知道主机的IP地址根本就不是172.16.3.x这种IP,主机的IP比如是192.168.25.24
5、我猜测思路是这样,假设C1(172.16.3.15)要和C2(172.16.3.16)进行TCP/IP通信,A主机要能够检测这个数据包p,然后发现3.16这个容器不在本主机上,查询etcd后发现它在B主机上,好,现在A主机就把这个数据包p重新封装一下,由A主机给B主机发一个UDP报文,把这个数据包p封装到UDP数据包中直接发给B,B收到以后,把UDP报文解开一看,我靠,原来是个发给C2的数据包p啊,然后就把这个数据包p丢给容器C2,那么容器C2不就拿到数据了嘛
那这个地方就在于,怎么把C1的数据包捕获到?搞网络通信协议的人需要对内核比较懂,才知道如何捕获到C1这个容器发出去的数据包!而且这个数据包可以是TCP、UDP,甚至是ICMP报文!
总之一句话就是:flannel是把将容器发出去的以太网数据包装在另一种网络包里面进行路由转发和通信,目前已经支持UDP、VxLAN、AWS VPC和GCE路由等数据转发方式,默认的节点间数据通信方式是UDP转发。host-gw模式不涉及到封包和解包。
Docker本身创建的网桥是怎么路由的? 
同理,在每个主机上一旦安装了flanneld,也会创建出一个类似docker0一样的网桥,一般就是叫flannel0,说到这里有必要再解释一下linux的bridge技术,可见知识的应用是有互相补充的关系的,不懂Linux bridge技术,就不会懂docker在单机上的容器之间的通信,更不用谈跨主机的容器通信。
Linux的bridge技术
bridge是一个虚拟网络设备,所以具有网络设备的特征,可以配置IP、MAC地址等;其次,bridge是一个虚拟交换机,和物理交换机有类似的功能
对于普通的网络设备来说,只有两端,从一端进来的数据会从另一端出去,如物理网卡从外面网络中收到的数据会转发给内核协议栈,而从协议栈过来的数据会转发到外面的物理网络中。也就是说物理网卡上收到的高低电平电信号,会被锁到网卡的FIFO中,网卡的FIFO可以理解为一堆晶体管组成的寄存器,操作系统内核会从网卡的FIFO中把数据读走,读到内核使用的内存中,最后还要从内核使用的内存再搬运一次到用户态内存中,这样用户态的代码才能读取到字节数组,涉及到数据从网卡的FIFO到内核态内存、再到用户态内存中。
而bridge不同,bridge有多个端口,数据可以从任何端口进来,进来之后从哪个口出去和物理交换机的原理差不多,要看mac地址,也就是说有mac-port映射表,记得以前监控交换机的时候,构建拓扑图,就涉及到通过snmp查询交换机的mac地址表。
要理解bridge,最好是先动手做一下试验,然后才是内核代码,内核代码太复杂,非必要先不去研究,但是通过iproute2工具集做试验,还是很好的,加深印象
yum info iproute
已安装的软件包
名称 :iproute
架构 :x86_64
版本 :4.11.0
发布 :30.el7
大小 :1.8 M
源 :installed
来自源:anaconda
简介 : Advanced IP routing and network device configuration tools
网址 :http://kernel.org/pub/linux/utils/net/iproute2/
协议 : GPLv2+ and Public Domain
描述 : The iproute package contains networking utilities (ip and rtmon, for example)
: which are designed to use the advanced networking capabilities of the Linux
: kernel.
[root@linux3 ~]# ip
Usage: ip [ OPTIONS ] OBJECT { COMMAND | help }
ip [ -force ] -batch filename
where OBJECT := { link | address | addrlabel | route | rule | neigh | ntable |
tunnel | tuntap | maddress | mroute | mrule | monitor | xfrm |
netns | l2tp | fou | macsec | tcp_metrics | token | netconf | ila |
vrf }
OPTIONS := { -V[ersion] | -s[tatistics] | -d[etails] | -r[esolve] |
-h[uman-readable] | -iec |
-f[amily] { inet | inet6 | ipx | dnet | mpls | bridge | link } |
-4 | -6 | -I | -D | -B | -0 |
-l[oops] { maximum-addr-flush-attempts } | -br[ief] |
-o[neline] | -t[imestamp] | -ts[hort] | -b[atch] [filename] |
-rc[vbuf] [size] | -n[etns] name | -a[ll] | -c[olor]}
本质要会ip命令,详情:http://kernel.org/pub/linux/utils/net/iproute2/,下面新建一个网桥,类型指定为bridge,其实ip命令参数超多
[root@linux3 ~]# ip link add name br0 type bridge
[root@linux3 ~]# ip link set br0 up
[root@linux3 ~]# ifconfig
br0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::ac9f:f3ff:fe12:7d9f prefixlen 64 scopeid 0x20<link>
ether ae:9f:f3:12:7d:9f txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 656 (656.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
这个地方还涉及到一个叫做veth的虚拟网络设备,看ip link help就可以知道,它支持的type中有veth,这个是啥?
[root@linux3 ~]# ip link help
Usage: ip link add [link DEV] [ name ] NAME
[ txqueuelen PACKETS ]
[ address LLADDR ]
[ broadcast LLADDR ]
[ mtu MTU ] [index IDX ]
[ numtxqueues QUEUE_COUNT ]
[ numrxqueues QUEUE_COUNT ]
type TYPE [ ARGS ]
ip link delete { DEVICE | dev DEVICE | group DEVGROUP } type TYPE [ ARGS ]
ip link set { DEVICE | dev DEVICE | group DEVGROUP }
[ { up | down } ]
[ type TYPE ARGS ]
[ arp { on | off } ]
[ dynamic { on | off } ]
[ multicast { on | off } ]
[ allmulticast { on | off } ]
[ promisc { on | off } ]
[ trailers { on | off } ]
[ carrier { on | off } ]
[ txqueuelen PACKETS ]
[ name NEWNAME ]
[ address LLADDR ]
[ broadcast LLADDR ]
[ mtu MTU ]
[ netns { PID | NAME } ]
[ link-netnsid ID ]
[ alias NAME ]
[ vf NUM [ mac LLADDR ]
[ vlan VLANID [ qos VLAN-QOS ] [ proto VLAN-PROTO ] ]
[ rate TXRATE ]
[ max_tx_rate TXRATE ]
[ min_tx_rate TXRATE ]
[ spoofchk { on | off} ]
[ query_rss { on | off} ]
[ state { auto | enable | disable} ] ]
[ trust { on | off} ] ]
[ node_guid { eui64 } ]
[ port_guid { eui64 } ]
[ xdp { off |
object FILE [ section NAME ] [ verbose ] |
pinned FILE } ]
[ master DEVICE ][ vrf NAME ]
[ nomaster ]
[ addrgenmode { eui64 | none | stable_secret | random } ]
[ protodown { on | off } ]
ip link show [ DEVICE | group GROUP ] [up] [master DEV] [vrf NAME] [type TYPE]
ip link xstats type TYPE [ ARGS ]
ip link afstats [ dev DEVICE ]
ip link help [ TYPE ]
TYPE := { vlan | veth | vcan | dummy | ifb | macvlan | macvtap |
bridge | bond | team | ipoib | ip6tnl | ipip | sit | vxlan |
gre | gretap | ip6gre | ip6gretap | vti | nlmon | team_slave |
bond_slave | ipvlan | geneve | bridge_slave | vrf | macsec }
- veth和其它的网络设备都一样,一端连接的是内核协议栈
- veth设备是成对出现的,顾名思义,veth-pair 就是一对的虚拟设备接口,和 tap/tun 设备不同的是,它都是成对出现的。一端连着协议栈,一端彼此相连着

- 一个设备收到协议栈的数据发送请求后,会将数据发送到另一个设备上去。

ip link add veth0 type veth peer name veth1
ip addr add 192.168.3.11/24 dev veth0
ip link set veth0 up
ip link set veth1 up
再给veth1也配置一个ip地址
ip addr add 192.168.3.12/24 dev veth1
[root@linux3 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.2.1 0.0.0.0 UG 100 0 0 ens33
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.2.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.3.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
192.168.3.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1
[root@linux3 ~]# ifconfig
veth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.3.11 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::f43d:8cff:fe4e:d03b prefixlen 64 scopeid 0x20<link>
ether f6:3d:8c:4e:d0:3b txqueuelen 1000 (Ethernet)
RX packets 8 bytes 656 (656.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 656 (656.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.3.12 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::a8df:d9ff:fe5e:12b8 prefixlen 64 scopeid 0x20<link>
ether aa:df:d9:5e:12:b8 txqueuelen 1000 (Ethernet)
RX packets 8 bytes 656 (656.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 656 (656.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
它常常充当着一个桥梁,连接着各种虚拟网络设备,典型的例子像“两个 namespace 之间的连接”,“Bridge、OVS 之间的连接”,“Docker 容器之间的连接” 等等,以此构建出非常复杂的虚拟网络结构,比如 OpenStack Neutron
flanneld支持的vxlan技术
【华为悦读汇】技术发烧友:认识VXLAN,华为的这篇文章很详细进行了vxlan介绍。
是一种overlay的网络技术,使用MAC in UDP的方法进行封装,共50字节的封装报文头,VXLAN(Virtual eXtensible Local Area Network,虚拟扩展局域网),是由IETF定义的NVO3(Network Virtualization over Layer 3)标准技术之一,采用L2 over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,可实现二层网络在三层范围内进行扩展,同时满足数据中心大二层虚拟迁移和多租户的需求。
NVO3是基于三层IP overlay网络构建虚拟网络的技术的统称,VXLAN只是NVO3技术之一。除此之外,比较有代表性的还有NVGRE、STT
看下面这个图,不用颜色的VM是跨主机分别属于不同的vxlan的,它们的VNI是不一样的,VNI是24个bit、3个字节,最大可达1600万,足够应付大型数据中心的租户数量了。
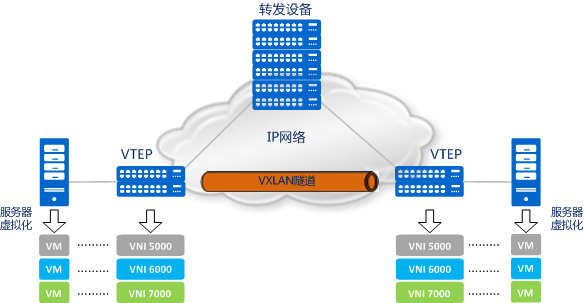
VTEP,全称VXLAN Tunnel Endpoints,VXLAN隧道端点,这玩意是vxlan网络的边缘设备,就像linux就可以用iproute2工具集中的ip命令进行创建一样,VTEP会将VM发出的原始报文封装成一个新的UDP报文,并使用物理网络的IP和MAC地址作为外层头,对网络中的其他设备只表现为封装后的参数。也就是说,网络中的其他设备看不到VM发送的原始报文。
VTEP既可以是一款独立的网络设备(比如华为的CE系列交换机),也可以是虚拟机所在的服务器,安装Linux操作系统,内核支持vxlan技术。
为了保证业务不中断,VM的迁移就必须发生在同一个二层域内(因为VM的IP地址和MAC地址不准更改!)。现在,再回头看下VXLAN网络模型,你是不是惊奇地发现,有了VTEP的封装机制和VXLAN隧道后,所谓的 “二层域”就可以轻而易举的突破物理上的界限?也就是说,在IP网络中, “明”里传输的是跨越三层网络的UDP报文,“暗”里却已经悄悄将源VM的原始报文送达目的VM。就好像在三层的网络之上,构建出了一个虚拟的二层网络,而且只要IP网络路由可达,这个虚拟的二层网络想做多大就做多大。现在,你应该明白为什么说VXLAN是一种NVO3技术了吧。
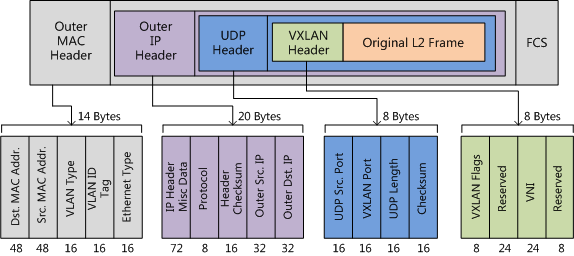
下面14+20+8+8=50,所以vxlan技术封装后要多出50个字节,其中在UDP报文内放了8个字节的VxLan header,增加VXLAN头(8字节),其中包含24比特的VNI字段,用来定义VXLAN网络中不同的租户。此外,还包含VXLAN Flags(8比特,取值为00001000)和两个保留字段(分别为24比特和8比特)。
VxLAN Header的8个字节和原始以太帧一起作为UDP的数据包。UDP头中,目的端口号(VXLAN Port)固定为4789,源端口号(UDP Src. Port)是原始以太帧通过哈希算法计算后的值。
iproute2说明
http://www.policyrouting.org/iproute2.doc.html#ss9.6
其中ip rule命令会让人觉得迷惑,好像是在操作路由表一样,其实添加、删除、修改路由表的命令是ip route,ip rule的作用是修改路由选路策略,通常都是基于目的网络来进行选路的。
ip rule用于定义路由策略,什么叫路由策略,其实它就是控制路由选择算法的规则而已。现在使用的经典路由算法仅根据数据包的目的IP地址做出路由决策,在某些情况下不仅希望根据目的IP地址,而且还希望根据其他数据包字段(如源地址、IP协议、传输协议端口,甚至数据包有效负载)对数据包进行不同的路由,要做这个事情,就要用ip rule命令,这就叫策略路由。















 2056
2056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









