







Calico与Flannel,容器虚拟化网络方案中涉及到的方案是2个:基于隧道、基于路由,基于隧道具备普适性,比如flannel的vxlan、udp模式,Calico的IPIP模式
每个主机上都要安装calico或者flannel的agent进程,这些agent进程会从etcd这样的集中式数据库中查询到一个私有网段,然后这台主机上的容器后续就都用这些ip地址了,核心就是每个agent拿到一个网段后,就修改dockerd的启动参数,加上--bip,就可以控制容器的IP地址了。
既然是隧道,就好像汽车坐轮船摆渡一样,涉及到数据包的封包/解包,意思就是自己无法把数据包发出去,那就借助外力,很显然,摆渡是需要成本的,会消耗CPU以及增加网络延迟。
封包/解包
- 容器和容器之间通信(跨主机),数据包的源IP和目的IP都是容器的IP,很明显是无法路由的,下面还是耍魔法
- 得在host主机上做一个魔法操作,让这个容器的数据包A能够送到host主机上的flannel或者calico这种网络插件的agent进程,等于说汽车得找到轮船,由轮船帮你把数据包送出去
- agent拿到数据包以后,就会把数据包进行改头换面,把数据包A重新塞到另外一个数据包B里面,这个数据包B的源IP和目的IP都是host主机的IP地址。很明显,host主机的IP是互联互通的;
- 数据包送到目标宿主机后,解封,得到原始数据包,然后在宿主机上想办法,把这个数据包再送到对应的容器里面去处理
- 这么一搞的话,2端的容器就有了一种互联互通的幻觉
- 因为host主机的IP地址是工作在OSI模型的第3层(第4层是TCP/UDP,第2层是MAC链路层),所以是可以跨路由的,也就是说宿主机本身跨网段经过路由器,也是没有任何影响的,这个隧道方案具备普适性了,优势很明显,只要host主机在IP层可以互联互通,就可以确保容器可以互联互通。
- 但是封包解包浪费CPU,额外封包增加的数据,会浪费带宽
flannel vxlan和calico ipip模式都是隧道方案,但是calico的封装协议IPIP的header更小,所以性能比flannel vxlan要好一点点
基于路由
这就比较OK了,虽然容器无法跨主机路由,但是真的是数据包无法到达吗,2台物理主机明明是插着网线的,信号绝对可以互联互通,所谓的不能,都是路由表搞的贵,而且os内核是根据路由表转发数据的,所以只要在路由表做文章即可。flannel的host-gw模式,以及calico的bgp模式都是基于路由的。
- Agent搞到一个虚拟IP网段,这个和基于隧道是一样的,目的是让容器具备全集群唯一的ip地址,各个host上的agent搞到的虚拟ip网段是唯一的,不会重叠,每个agent弄到的ip地址段都存放在etcd里面
- 每个宿主机上面都安装了calico的agent,用虚拟ip网段给本机的容器分配IP地址,假设现在创建了一个容器A,它的IP地址是IP1,此时宿主机上就会创建一条路由规则:如果有发给IP1的数据包,就把数据包送到这个容器的虚拟网卡上,言下之意数据包送到了这个容器的虚拟网卡上,自然就会进入容器的网络协议栈了,容器也就收到数据包了,数据接收成功。
举个例子,现在我这边机器上启动了一个Pod它的IP是10.233.115.11,那么必然在本机会有一条路由规则,它的目的是10.233.115.11,通过哪个Iface送过去呢,这里是cali68ffbc58d02,我们来看看这个cali68ffbc58d02是什么?

实际上cali68ffbc58d02就是容器的虚拟网卡
- 宿主机开始用bgp协议广播路由,告诉各个主机,说:喂,我有网段net1,你们呢,最后就变成,大家互相通报自己链接的网络,举例子:
A主机说我有虚拟IP网段172.16.2.0/24,B主机收到后就把自己的路由表里面添加了一条路由规则:如果以后有发到172.16.2.0/24的数据包,就发给A主机的物理IP,言下之意就把A主机当成下一跳路由器,这感觉就好像是主机A成为虚拟IP网段172.16.2.0/24的网关了,主机变成路由器了 - 好了,现在如果主机B上有一个容器要给主机A上的容器发数据包,就会通过主机A过去,然后主机A就会检查本机的路由表,把数据包送到容器的虚拟网卡上
- 整个流程不涉及到封包/解包,但是额外多出2点了:
- 主机们充当BGP路由器,要通告自己的路由
- 每创建1个容器,就要在本机上添加一条路由规则,这会导致路由规则可能比较多(不过一般一台主机上也不可能启动那么多容器)
About Networking![]() https://docs.projectcalico.org/about/about-networkingCalico这玩意怎么理解?目的是:
https://docs.projectcalico.org/about/about-networkingCalico这玩意怎么理解?目的是:
1、让跨主机的POD互通
2、必须高效,但是背后的实现机制还要简单,不要搞的太复杂,比如隧道、比如vxlan、比如linux bridge、veth等,好多一大堆的东西,理解起来很费劲,整个链路一长的话理解就难了
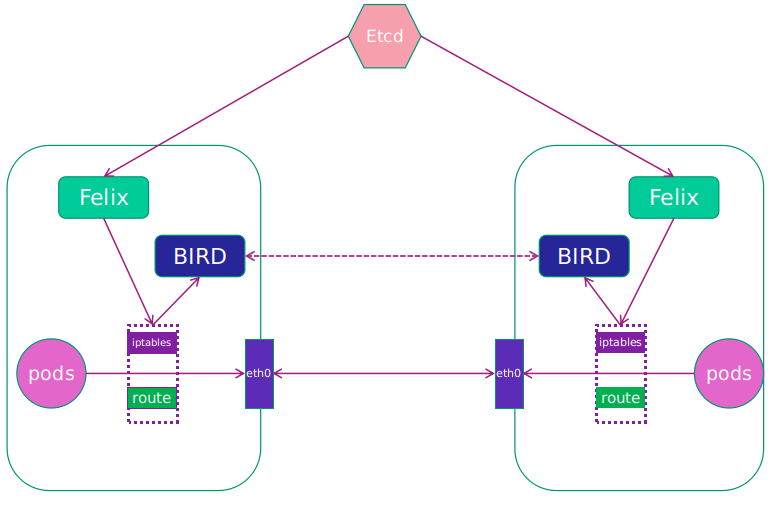
Calico网络模型主要工作组件:
1.Felix:运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。
2.etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
3.BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听 Host 上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉剩余 Host 节点,从而实现网络互通。
4.BGP Route Reflector:在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
Calico用了2种网络模型:
IPIP网络(安装Calico时默认):
流量:tunnel设备封装数据,形成隧道,承载流量。
适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。
效率:流量需要tunl0设备封装,效率略低
BGP网络:
流量:使用路由表规则导向流量
适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
效率:原生hostGW,效率高
Calico也有缺点:
(1) 缺点租户隔离问题
Calico 的三层方案是直接在 host 上进行路由寻址,那么对于多租户如果使用同一个 CIDR 网络就面临着地址冲突的问题。
(2) 路由规模问题
通过路由规则可以看出,路由规模和 pod 分布有关,如果 pod离散分布在 host 集群中,势必会产生较多的路由项,假设host有100台机器,一共有400个pod,那route -n路由表内容也是蛮多的。
(3) iptables 规则规模问题
1台 Host 上可能虚拟化十几或几十个容器实例,过多的 iptables 规则造成复杂性和不可调试性,同时也存在性能损耗(啥性能损耗,意思就是iptables规则太多,内核遍历查找iptables规则就比较消耗CPU了)
(4) 跨子网时的网关路由问题
当对端网络不为二层可达时,需要通过三层路由器时,需要网关支持自定义路由配置,即 pod 的目的地址为本网段的网关地址,再由网关进行跨三层转发
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









