





In the first part of this series we learned how to extract packaged objects from a legacy Access database. In this second part we’ll learn how to extract Acrobat PDF documents and take a brief look at a selection of image formats.
在本系列的第一部分中,我们学习了如何从旧版Access数据库中提取打包的对象。 在第二部分中,我们将学习如何提取Acrobat PDF文档,并简要介绍一些图像格式。
The only similarity that PDF, GIF, PNG, etc., have when stored in an Access database is that they are all wrapped in an OLE container consisting of a variable length header and trailer. As we shall see, the trailer can be ignored as it was with the package discussed in Part 1. The header is more useful, but doesn’t contain all the information we need.
当将PDF,GIF,PNG等存储在Access数据库中时,唯一的相似之处在于它们全部包裹在OLE容器中,该容器由可变长度的标头和标头组成。 就像我们将看到的那样,可以像在第1部分中讨论的包那样忽略预告片。标头更有用,但不包含我们需要的所有信息。
Adobe Acrobat文件 (Adobe Acrobat Documents)
In the test database used for this article, there’s a PDF stored in record number 13:
在本文使用的测试数据库中,记录号13中存储着一个PDF:
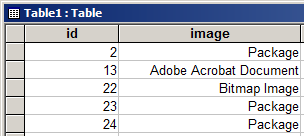
The identification of an Adobe Acrobat Document (PDF) in an Access database OLE object field is achieved using the same method we learned in Part 1 – inspect the first fifty or so bytes looking for a recognisable sequence of characters.
使用我们在第1部分中学习的相同方法,可以在Access数据库OLE对象字段中识别Adobe Acrobat文档(PDF)–检查前五十个字节左右以寻找可识别的字符序列。
Applying the same method of extracting a chunk of data from the OLE field, then converting it from hexadecimal to decimal, and displaying it in a hex viewer, makes it clear that although we definitely have a PDF stored in the field, we have no other information such as the original name of the PDF or its original file size:
应用相同的方法从OLE字段中提取数据块,然后将其从十六进制转换为十进制,然后在十六进制查看器中显示,这很清楚,尽管我们确实在该字段中存储了PDF,但是我们没有其他信息,例如PDF的原始名称或原始文件大小:
Fortunately, there’s another technique we can use to extract the PDF. Every PDF always starts with the character sequence %PDF and ends with the sequence %%END. This can be verified easily by loading a small PDF in a plain text editor. Alternatively, load one into a hex viewer:
幸运的是,还有另一种我们可以用来提取PDF的技术。 每个PDF总是以字符序列%PDF开头,并以字符%% END结尾。 通过在纯文本编辑器中加载小的PDF可以轻松地验证这一点。 或者,将其加载到十六进制查看器中:

Here I’ve shown only the first and last few bytes, as these are where the PDF delimiters are. The next step is to apply this technique to the contents of the OLE field and find the location of the start and end and of the embedded PDF:
在这里,我仅显示了前几个字节,因为这是PDF分隔符所在的位置。 下一步是将此技术应用于OLE字段的内容,并找到开始和结束以及嵌入式PDF的位置:

Note that it’s the hexadecimal character sequences that we need to search for; that is, when using PHP’s strpos() function to find the start of the embedded PDF, look for 25504446. When looking for the end, 2525454F46 is the relevant character sequence.
注意,这是我们需要搜索的十六进制字符序列; 也就是说,使用PHP的strpos()函数查找嵌入式PDF的开头时,请查找25504446。在查找结尾时,2525454F46是相关的字符序列。
So what do we have now? We’ve identified the OLE object as type Acrobat Document, and we have the start and end locations of the embedded file. We thus have all we need to extract the original file from the OLE field using PHP’s substr() function.
那么我们现在有什么呢? 我们已经将OLE对象标识为Acrobat Document类型,并且有了嵌入式文件的开始和结束位置。 因此,我们拥有使用PHP的substr()函数从OLE字段中提取原始文件所需的全部。
其他对象类型 (Other Object Types)
Before discussing popular images types, it’s worth taking a moment to improve the switch statement presented in Part 1. For the catch-all default condition we simply displayed a message. It’d be much more useful if any unknown OLE types were extracted and saved to disk for later analysis. The new function extractUnknown() takes the entire contents of the OLE field, converts it from hexadecimal to decimal, then saves it to disk using the record ID as its file name. This allows us to view any unknown OLE type in a hex viewer later to ascertain the type of the embedded object. We’ll need this in the next section to identify which records have embedded images.
在讨论流行的图像类型之前,值得花一点时间来改进第1部分中介绍的switch语句。对于所有默认条件,我们只显示一条消息。 如果提取了任何未知的OLE类型并将其保存到磁盘以供以后分析,那将更加有用。 新函数extractUnknown()接收OLE字段的全部内容,将其从十六进制转换为十进制,然后使用记录ID作为其文件名将其保存到磁盘。 这样,我们便可以稍后在十六进制查看器中查看任何未知的OLE类型,以确定嵌入式对象的类型。 我们将在下一部分中使用它来识别哪些记录具有嵌入式图像。
<?php
function extractUnknown($id, $data) {
// convert entire object to decimal and save to disk
file_put_contents($id . ".txt", hex2bin($data));
}热门图片类型 (Popular Image Types)
It’s not possible to say with any certainty how image types will be identified in an OLE header in any given Access database. It may be that images will be identified as “Paint Shop Pro 6”, or perhaps they’ll be associated with some other image editing software. It depends entirely on what software was known to the system that was used to store the images and on any file associations that were configured.
无法确定地说如何在任何给定的Access数据库中的OLE标头中标识图像类型。 图像可能被标识为“ Paint Shop Pro 6”,或者可能与其他图像编辑软件相关联。 这完全取决于用于存储映像的系统已知的软件以及配置的任何文件关联。
In order to know what these unknown types are, we can make a list by running every record with an unknown OLE type through the extractUnknown() function. This will be different across the plethora of legacy Access database that exist today.
为了知道这些未知类型是什么,我们可以通过extractUnknown()函数运行具有未知OLE类型的每条记录来建立一个列表。 在当今存在的大量旧式Access数据库中,情况将有所不同。
The image formats we’ll consider here are BMP, GIF, JPEG, and PNG.
我们将在此处考虑的图像格式为BMP,GIF,JPEG和PNG。
GIF,JPEG,PNG (GIF, JPEG, PNG)
“Good news, everyone!” These three image types can be processed in exactly the same way. What’s more, it’s exactly the same method used earlier to extract an embedded PDF. First we need to find the start position of the embedded image, then the end position, then extract inclusively everything between these two points. The difference is in how we identify the embedded object. The following table summarises these crucial details:
“好消息,大家!” 可以完全相同的方式处理这三种图像类型。 而且,它与之前提取嵌入式PDF所使用的方法完全相同。 首先,我们需要找到嵌入图像的开始位置,然后是结束位置,然后包括这两个点之间的所有内容。 不同之处在于我们如何识别嵌入式对象。 下表总结了这些关键细节:

骨形态发生蛋白 (BMP)
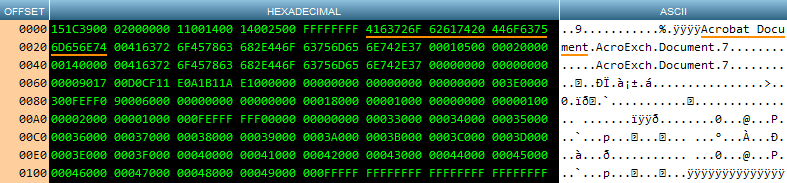
Identifying the delimiters of an embedded BMP is similar, but requires a little more work. Finding the start position is as easy as it is with the file types discussed above, but finding the end position requires a bit of math. Let’s see the two crucial elements in a hex viewer:
识别嵌入式BMP的分隔符很相似,但是需要做更多的工作。 查找开始位置就像上面讨论的文件类型一样容易,但是查找结束位置需要一些数学运算。 让我们看看十六进制查看器中的两个关键元素:

The first two bytes (BM in ASCII), underlined in orange, are the start location of the embedded BMP. The following two bytes, underlined in yellow, are the original size of the BMP stored in little-endian format. The size needs to be converted to big-endian format, then multiplied by two because the object is stored in hexadecimal format.
前两个字节(ASCII中的BM)用橙色下划线标出,它们是嵌入式BMP的起始位置。 接下来的两个字节(带黄色下划线)是以小端格式存储的BMP的原始大小。 大小需要转换为big-endian格式,然后乘以2,因为对象以十六进制格式存储。
Given that we now have the start position and the size of the embedded object, we can used the same method to extract a BMP as we used in Part 1 to extract an object from a package.
鉴于我们现在有了嵌入对象的开始位置和大小,我们可以使用与第1部分中使用的方法相同的方法提取BMP,以从包中提取对象。
放在一起 (Putting It All Together)
What follows is the PHP script from Part 1 updated to include the new functionality described above. The basic structure is identical to its previous version, and the additional conditions in the switch() statement shows how easy it is to extend the core logic of the script to accommodate other OLE types.
接下来是对第1部分中PHP脚本进行了更新,以包括上述新功能。 基本结构与其先前的版本相同,并且switch()语句中的其他条件表明,扩展脚本的核心逻辑以容纳其他OLE类型是多么容易。
<?php $offset = array( "Packager Shell Object" =--> 168,
"Package" => 140
);
if (!function_exists("hex2bin")) {
function hex2bin($hexStr) {
$hexStrLen = strlen($hexStr);
$binStr = "";
$i = 0;
while ($i < $hexStrLen) { $a = substr($hexStr, $i, 2); $c = pack("H*", $a); $binStr .= $c; $i += 2; } return $binStr; } } $dbName = "db1.mdb"; $db = new PDO("odbc:DRIVER={Microsoft Access Driver (*.mdb)}; DBQ=$dbName; Uid=; Pwd=;"); $sql = "SELECT * FROM Table1"; foreach ($db->query($sql) as $row) {
$objName = "";
switch (getOLEType($row["image"])) {
case "Packager Shell Object":
list($objName, $objData) = extractPackage($row["image"], $offset["Packager Shell Object"]);
break;
case "Package":
list($objName, $objData) = extractPackage($row["image"], $offset["Package"]);
break;
case "Acrobat Document":
list($objName, $objData) = extractPDF($row["id"], $row["image"]);
break;
case "Paint Shop Pro 6":
case "Bitmap Image":
list($objName, $objData) = extractImage($row["id"], $row["image"]);
break;
default:
list($objName, $objData) = extractUnknown($row["id"], $row["image"]);
}
if ($objName != "") {
file_put_contents($objName, $objData);
}
}
function extractUnknown($id, $data) {
// convert entire object to decimal and save to disk
file_put_contents($id . ".txt", hex2bin($data));
}
function extractPackage($data, $offset) {
// usable header size
$headerBlock = 500;
// find name
$tmp = substr($data, $offset, 255);
$nullPos = findNullPos($tmp);
$name = substr($tmp, 0, $nullPos);
$pos = $offset + strlen($name);
// find data
// 1st full path
list($path1, $nameLen) = findFileName($data, $name, $pos, $headerBlock);
$pos = $path1 + $nameLen;
// 2nd full path
list($path2, $nameLen) = findFileName($data, $name, $pos, $headerBlock);
// check if only one full path
if ($path2 > $pos) {
$pos = $path2 + strlen($name);
}
$oleSizePos = $pos + 2;
$oleObjSize = flipEndian(substr($data, $oleSizePos, 8), 8);
$oleHeaderEnd = $oleSizePos + 8;
$objName = hex2bin(substr($tmp, 0, $nullPos));
// extract object
$objData = getBlob($data, $oleHeaderEnd, hexdec($oleObjSize) * 2);
return array($objName, $objData);
}
function extractPDF($id, $data) {
$delimiter = array(
"pdfStart" => "25504446",
"pdfEnd" => "2525454F46"
);
// %PDF - start block common to all PDFs
$offsetStart = strpos($data, $delimiter["pdfStart"], 0);
// %%EOF - end block common to all PDFs
$offsetEnd = strpos($data, $delimiter["pdfEnd"], $offsetStart) + 12;
$objData = getBlob($data, $offsetStart, $offsetEnd - $offsetStart);
return array($id . ".pdf", $objData);
}
function extractImage($id, $data) {
$delimiter = array(
"bmpStart" => "424D",
"gifStart" => "4749463839",
"gifEnd" => "003B",
"jpgStart" => "FFD8",
"jpgEnd" => "FFD9",
"pngStart" => "89504E47",
"pngEnd" => "49454E44AE426082"
);
$objName = "";
if (strpos($data, $delimiter["bmpStart"], 0) !== false) { // is object a BMP
list($objName, $objData) = extractBMP($id, $data, $delimiter["bmpStart"]);
}
elseif (strpos($data, $delimiter["gifStart"], 0) !== false) { // is object a GIF89
list($objName, $objData) = extractGIF($id, $data, $delimiter["gifStart"], $delimiter["gifEnd"]);
}
elseif (strpos($data, $delimiter["jpgStart"], 0) !== false) { // is object a JPEG
list($objName, $objData) = extractJPEG($id, $data, $delimiter["jpgStart"], $delimiter["jpgEnd"]);
}
elseif (strpos($data, $delimiter["pngStart"], 0) !== false) { // is object a PNG
list($objName, $objData) = extractPNG($id, $data, $delimiter["pngStart"], $delimiter["pngEnd"]);
}
else {
// other image types in here
}
// save to disk if object was found
if ($objName != "") {
file_put_contents($objName, $objData);
}
}
function extractBMP($id, $data, $bmpStart) {
$oleObjStart = strpos($data, $bmpStart, 0);
$oleObjSize = hexdec( flipEndian(substr($data, $oleObjStart+4, 8), 8) );
// extract object
$objData = getBlob($data, $oleObjStart, $oleObjSize * 2);
return array($id.".bmp", $objData);
}
function getBlob($data, $start, $end) {
return hex2bin(substr($data, $start, $end));
}
function flipEndian($data, $size) {
$str = "";
for ($i = $size - 2; $i >= 0; $i -= 2) {
$str .= substr($data, $i, 2);
}
return $str;
}
function findNullPos($str) {
// must start on a two-character boundary
return floor((strpos($str, "00") + 1) / 2) * 2;
}
function getOLEType($data) {
// fixed position of OLE type
$offset = 40;
$tmp = substr($data, $offset, 255);
$nullPos = findNullPos($tmp);
$tmp = substr($tmp, 0, $nullPos);
$type = hex2bin($tmp);
return $type;
}
function hexStrToCase($str, $case) {
$alphabet = 32;
$tmp = "";
$splitHex = array();
$splitHex = str_split($str, 2);
$splitTest = hex2bin($splitHex[0]);
foreach ($splitHex as $key => $value) {
switch ($case) {
case "upper":
if ((intval($value, 16) >= ord("a")) && (intval($value, 16) <= ord("z"))) { $splitHex[$key] = dechex(intval($value, 16) - $alphabet); } break; case "lower": if ((intval($value, 16) >= ord("A")) && (intval($value, 16) <= ord("Z"))) { $splitHex[$key] = dechex(intval($value, 16) + $alphabet); } break; } } $tmp = strtoupper(implode($splitHex)); return $tmp; } function hexStrToTilda1($str) { $strDot = "2E"; $strTilda1 = "7E31"; $tmp = hexStrToCase($str, "upper"); if (strlen($tmp) > 24) {
$dotPos = strrpos($tmp, $strDot);
$tmp = substr($tmp, 0, 12) . $strTilda1 . substr($tmp, $dotPos, 8);
}
return $tmp;
}
function findFileName($data, $str, $offset, $headerBlock) {
$strLen = 0;
$tmp = substr($data, 0, $headerBlock);
$strUpper = hexStrToCase($str, "upper");
$strLower = hexStrToCase($str, "lower");
$strTilda1 = hexStrToTilda1($str);
$strPos = stripos($tmp, $str, $offset);
if ($strPos === false) {
$strPos = stripos($tmp, $strUpper, $offset);
if ($strPos === false) {
$strPos = stripos($tmp, $strLower, $offset);
if ($strPos === false) {
$strPos = stripos($tmp, $strTilda1, $offset);
$strLen = strlen($strTilda1);
}
else {
$strLen = strlen($strLower);
}
}
else {
$strLen = strlen($strUpper);
}
}
else {
$strLen = strlen($str);
}
return array($strPos, $strLen);
}You’ll notice that I’ve not included code for the functions extractGIF(), extractJPEG(), and extractPNG(). That’s because I’m leaving these as an exercise for you, fellow PHP programmers – the code will be very similar to what we’ve covered for the other OLE object types.
您会注意到,我没有包含函数extractGIF() , extractJPEG()和extractPNG() 。 这是因为我将这些练习作为练习留给您,其他PHP程序员-代码将与我们为其他OLE对象类型介绍的内容非常相似。
摘要 (Summary)
In this article we’ve covered the essential elements of extracting PDFs from OLE fields in a Microsoft Access database using PHP. We also learned how to identify certain image formats, and how to extract them from their OLE container.
在本文中,我们介绍了使用PHP从Microsoft Access数据库的OLE字段中提取PDF的基本要素。 我们还学习了如何识别某些图像格式,以及如何从其OLE容器中提取它们。
Having completed this two-part introduction to how OLE objects are stored in, and can be retrieved from, a Microsoft Access database, we now have yet another tool to assist us with the migration away from legacy Access databases.
在完成了由两部分组成的关于OLE对象如何在Microsoft Access数据库中存储以及如何从Microsoft Access数据库中检索的介绍之后,我们现在有了另一个工具来协助我们从旧版Access数据库进行迁移。
You can get the code for this series on GitHub. The repo has two branches – part-1 for code to accompany the first part, and part-2 for code for this part.
您可以在GitHub上获得该系列的代码。 回购有两个分支- 部分1用于代码陪的第一部分,和部分2用于这部分代码。
Image via Fotolia
图片来自Fotolia
翻译自: https://www.sitepoint.com/extract-ole-objects-from-an-access-database-using-php-2/















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









