





web开发指南
This article was provided by Toptal. Thank you for supporting the partners who make SitePoint possible.
本文由Toptal提供。 感谢您支持使SitePoint成为可能的合作伙伴。
This guide offers a sampling of effective questions to help evaluate the breadth and depth of a candidate’s mastery of web development, including client-side, server-side, transport, and database related topics.
本指南提供了一些有效问题的样本,以帮助评估候选人对Web开发的掌握的广度和深度,包括客户端,服务器端,传输和数据库相关主题。
Before we embark on the journey of identifying world-class web developers, we must first define exactly what we mean by “web development”. Are we referring to the development of a web site? Or the development of a web service? Or the development of a complex web-based application? The truth is that web development is an extremely broad term that can legitimately encompass any or all of the above. Accordingly, this guide touches on multiple aspects of web development, some or all of which will be relevant to the specific context in which you may be looking to hire.
在开始确定世界一流的Web开发人员之前,我们必须首先明确定义“ Web开发”的含义。 我们指的是网站的开发吗? 还是开发Web服务? 还是开发复杂的基于Web的应用程序? 事实是,Web开发是一个极为宽泛的术语,可以合理地包含上述任何或全部内容。 因此,本指南涉及Web开发的多个方面,其中某些或全部与您可能希望雇用的特定上下文有关。
This guide intentionally focuses on the conceptual and architectural underpinnings of web development, rather than delving into the specifics of any specific web technologies (such as JavaScript, Ruby on Rails, PHP, and so on). Accordingly, this guide presents “technology-agnostic” web developer interview questions relating to:
本指南有意侧重于Web开发的概念和体系结构基础,而不是深入研究任何特定Web技术(例如JavaScript , Ruby on Rails , PHP等)的细节。 因此,本指南提出了“与技术无关”的Web开发人员面试问题,涉及以下方面:

Admittedly, doing justice to many of the topics herein would warrant posts of their own. Nonetheless, this guide strives to provide at least a meaningful overview of key issues and topics relating to web development in which a highly-experienced web developer can be expected to be well-versed.
诚然,对本文中的许多主题保持公义是有根据的。 尽管如此,本指南仍力求至少提供与Web开发相关的关键问题和主题的有意义的概述,在这些方面中,可以期望经验丰富的Web开发人员是熟练的。
客户端(基于浏览器的开发) (Client-side (browser-based development))
Browser-based development presents numerous unique challenges to the developer, ranging from cross-browser anomalies, to sandbox limitations, to diverse performance characteristics across a wide array of client platforms and devices. Adept client-side web developers will be highly skilled at navigating these obstacles.
基于浏览器的开发给开发人员带来了众多独特的挑战,从跨浏览器异常到沙箱限制,再到各种客户端平台和设备的各种性能特征。 熟练的客户端Web开发人员将具有克服这些障碍的高超技巧。
问:在客户端至少讨论三个重点领域,以帮助减少页面加载时间。 (Q: Discuss at least three areas of focus on the client side to help reduce page load time.)
Performance is central to a user’s experience with any application. Users have become increasingly intolerant of slow page load times and, knowing this, the large search engines actually quantify that time for each of the pages that their bots crawl.
性能对于用户使用任何应用程序的体验至关重要。 用户变得越来越无法容忍页面加载速度慢,并且知道这一点,大型搜索引擎实际上量化了他们的机器人爬网的每个页面的时间。
Making the initial page request, getting the initial response contents of a page to the client, parsing that content and making subsequent requests for resource items (which in themselves are a round trip to and from the server), and then running any JavaScript can all contribute to page load time.
发出初始页面请求,将页面的初始响应内容发送给客户端,解析该内容并随后请求资源项(它们本身是往返于服务器的往返),然后运行任何JavaScript都可以有助于页面加载时间。
There are in fact numerous techniques to employ and areas to focus on to help improve page load time. Here are just a few examples:
实际上,有许多技术可以使用,并且需要重点关注以帮助缩短页面加载时间。 这里只是几个例子:
Avoid “render blocking”. When the browser’s parser engine encounters a tag in the HTML that accesses some external resource (such as a
<script>, <image>, <iframe>, etc.) the engine pauses to wait for that resource to download fully to the client before continuing. Even worse, in the case of a<script>tag with asrcattribute, the browser will also execute that script before it moves on to process the rest of the page. This becomes particularly problematic when that script may subsequently make another request. Most browsers provide an async attribute that you can add to those tags to avoid this type of blocking. Another strategy is to identify resources that you can delay loading until they are actually needed.避免“渲染阻止”。 当浏览器的解析器引擎在HTML中遇到访问某些外部资源(例如
<script>, <image>, <iframe>等)的标记时,引擎将暂停以等待该资源完全下载到客户端之前,继续。 更糟糕的是,对于具有src属性的<script>标记,浏览器还将在继续处理该页面的其余部分之前执行该脚本。 当该脚本随后可以发出另一个请求时,这尤其成问题。 大多数浏览器都提供了async属性,您可以将其添加到这些标签中,以避免这种类型的阻止。 另一种策略是确定可以延迟加载直到真正需要它们的资源。- Optimize images. Probably the largest resources you will load into a page are your images. Optimizing them for transport can prove to be very beneficial, as appropriate sizing can substantially reduce page load times. For example, don’t use a 600px by 400px image for a 120px by 80px thumbnail. It’s also helpful to pick the best compression format and to turn off certain format features. 优化图像。 图片可能是您将加载到页面中的最大资源。 对它们进行优化以进行传输可能非常有益,因为适当的大小调整可以大大减少页面加载时间。 例如,对于120px x 80px的缩略图,请勿使用600px x 400px的图像。 选择最佳的压缩格式并关闭某些格式功能也很有帮助。
- Minimize round-trip requests. The round-trip of retrieving resources (images, etc.) from the server can be a huge problem for page load times. Since the fewer requests a page makes, the faster it will be, one technique to help performance is to combine resources together into fewer requests where possible. For example, non-user generated images are a prime candidate here. A round-trip to the server just to retrieve a single 16×16 smiley face emoticon, for example, is extremely inefficient. 最小化往返请求。 从服务器检索资源(图像等)的往返对于页面加载时间可能是一个巨大的问题。 由于页面发出的请求越少,它就会越快,因此一种有助于提高性能的技术是在可能的情况下将资源组合在一起以减少请求。 例如,非用户生成的图像是此处的主要候选对象。 例如,仅检索单个16×16笑脸表情符号到服务器的往返效率极低。
问:提供跨浏览器开发挑战的示例,包括避免或解决这些挑战的一些技巧。 (Q: Provide examples of cross-browser development challenges, including some tips on avoiding them or addressing them.)
Few things in software development are as likely to cause premature hair loss as dealing with cross-browser issues and anomalies. Even if you’re just looking to support fairly current versions of popular browsers (such as IE, Firefox, and Chrome), you are still likely to encounter places where your code or layout simply doesn’t work (or at least, doesn’t work well) in one of the browsers.
与跨浏览器问题和异常处理相比,软件开发中很少有东西会导致过早脱发。 即使您只是希望支持相当流行的浏览器的最新版本(例如IE,Firefox和Chrome),您仍然可能会遇到代码或布局根本不起作用(或至少不起作用)的地方。不能正常工作)在其中一种浏览器中。
The issues are sufficiently inconsistent and gnarly that no single guide can provide a foolproof recipe for avoiding them, but there are certain things you can do to help minimize, and protect yourself from, these issues.
这些问题非常矛盾且令人生厌,没有哪一个指南可以提供避免这些问题的万无一失的方法,但是您可以做一些事情来帮助最小化这些问题并保护自己免受这些问题的侵害。
Here are some techniques to help minimize CSS-related anomalies across multiple browsers:
以下是一些有助于最大程度地减少跨多个浏览器CSS相关异常的技术 :
Browser reset stylesheets. The idea behind a browser reset stylesheet is to put you in control of the default style of all elements. For example, a very minimal starting point for a reset script might be as follows:
浏览器重置样式表。 浏览器重置样式表的想法是让您控制所有元素的默认样式。 例如,重置脚本的最低限度起点可能如下:
* { margin: 0; padding: 0; border: 0; }- Having this snippet of CSS run before all other stylesheets enables you to override any element properties you desire, knowing that anything you don’t override will still be fairly consistent on all browsers. 通过在所有其他样式表之前运行此CSS代码段,可以使您覆盖所需的任何元素属性,因为知道所有未覆盖的内容在所有浏览器中仍然相当一致。
Provide CSS “fallbacks”. When using newer CSS property values (that may not yet be supported by all browsers), it’s good to provide sensible fallbacks for those browsers that don’t yet support the property value you want to use. Older browsers will skip the newer property values that they don’t understand and will simply use the older (fallback) properties that they recognize, whereas newer browsers will understand both the fallbacks and the newer properties and will use the newer ones in place of the older ones. (Note:For this to work properly in newer browsers, the fallbacks must appear before the new properties in your CSS so that newer browsers prefer the newer properties.)
提供CSS“后备”。 使用较新CSS属性值(可能并非所有浏览器都支持)时,最好为那些尚不支持您要使用的属性值的浏览器提供合理的备用。 较旧的浏览器将跳过他们不了解的较新属性值,而只会使用其能够识别的较旧(后备)属性,而较新的浏览器将理解后备和较新属性,并会使用较新的属性代替比较老的 ( 注意 :要使其在较新的浏览器中正常运行,必须在CSS的新属性之前显示后备,以便较新的浏览器更喜欢较新的属性。)
User browser-specific prefixes for CSS property values. Although the prior two techniques have the distinct advantage of not requiring any browser-specific definitions or code, front-end web development is such that browser-specific solutions to at least some degree are not always avoidable. For example, browsers will sometimes support their own, work-in-progress version of some W3C-standard CSS property value. In such circumstances, the use of browser-specific prefixes these values can be a useful and reasonable approach (commonly used prefixes include -webkit- for Chrome and Safari, -moz- for Firefox, and -ms- for Internet Explorer). For example, the following CSS snippet employs vendor prefixes to provide gradient support in browser versions that do not yet support the W3C standard gradient property (it’s somewhat ugly, but it’s reliable and it works):
CSS属性值的特定于用户浏览器的前缀。 尽管前两种技术具有不需要任何特定于浏览器的定义或代码的显着优势,但是前端Web开发使得在某种程度上始终不能避免特定于浏览器的解决方案。 例如,浏览器有时会支持自己的某些W3C标准CSS属性值的进行中版本。 在这种情况下,使用浏览器特定的前缀这些值可能是一种有用且合理的方法(常见的前缀包括-webkit-(对于Chrome和Safari),-moz-(对于Firefox)和-ms-(对于Internet Explorer))。 例如,以下CSS片段使用供应商前缀在尚不支持W3C标准渐变属性的浏览器版本中提供渐变支持(虽然有点难看,但可靠且有效):
/* Vendor prefixes */ background: -webkit-gradient(linear, 50% 100%, 50% 0%, color-stop(0%, #2c99ce), color-stop(76%, #459dcf), color-stop(95%, #74b9e0), color-stop(100%, #abe1fa)); background: -webkit-linear-gradient(bottom, #2c99ce, #459dcf 76%, #74b9e0 95%, #abe1fa); background: -moz-linear-gradient(bottom, #2c99ce, #459dcf 76%, #74b9e0 95%, #abe1fa); background: -o-linear-gradient(bottom, #2c99ce, #459dcf 76%, #74b9e0 95%, #abe1fa); /* W3C Standard */ background: linear-gradient(bottom, #2c99ce, #459dcf 76%, #74b9e0 95%, #abe1fa);And if all else fails in IE… IE can be particularly ornery so, if more generic techniques like the ones above still don’t achieve the desired result in IE, you may be forced to use IE conditional comments. These hacks were voluntarily added by Microsoft to its browsers to help address IE’s inconsistencies. Since they come in the form of HTML comments, other browsers will simply ignore them:
如果IE中的所有其他操作都失败了,则IE可能特别麻烦,因此,如果上述通用技术仍然无法在IE中达到预期的效果,您可能会被迫使用IE条件注释 。 Microsoft自愿将这些黑客添加到其浏览器中,以帮助解决IE的不一致问题。 由于它们以HTML注释的形式出现,因此其他浏览器将简单地忽略它们:
<!--[if IE 8]> <link href="/ie8hacks.css" rel="stylesheet" type="text/css" /> <![endif]--> <!--Or, for IE5 through IE7--> <!--[if (gt IE 5)&(lte IE 8)]> <p>Dude, looks like it's time to update your browser!</p> <![endif]-->
On the JavaScript side of the world, there are also ways to deal with cross-browser idiosyncrasies.
在JavaScript的世界上,还有一些方法可以处理跨浏览器的特质。
Historically, the most common way this was done was through browser detection (a.k.a., “browser sniffing”) to detect what browser version the client is running . While this can work, it has a number of drawbacks. Most notably, it requires the developer to hardcode behavior based on the known/presumed capabilities of the detected browser and version. And it’s also worth noting that browser identity can be spoofed in many modern browsers. It is therefore not surprising that even jQuery advises against using its $.browser property.
从历史上看,最常见的方法是通过浏览器检测(也称为“浏览器嗅探”)来检测客户端正在运行的浏览器版本。 尽管这可以起作用,但它具有许多缺点。 最值得注意的是,它要求开发人员根据检测到的浏览器和版本的已知/假定功能对行为进行硬编码。 还要指出的是,在许多现代浏览器中都可以欺骗浏览器身份。 因此,即使jQuery也建议不要使用其$.browser属性也就不足为奇了。
The technique that jQuery advocates, and which is generally the recommended approach these days, is known as feature detection. Rather than relying on potentially flawed a priori knowledge of a browser’s capabilities, feature detection uses the more robust approach of determining dynamically what is and what is not supported by the client’s browser. Here’s an example:
jQuery提倡的技术(通常是当今推荐的方法)称为功能检测 。 功能检测不是依靠潜在的有缺陷的先验知识来了解浏览器功能,而是使用更强大的方法来动态确定客户端浏览器所支持和不支持的功能。 这是一个例子:
// this function adds an event listener reliably using feature detection
function myAddEventListener(event, listener) {
if (window.addEventListener) {
// Browser supports "addEventListener"
window.addEventListener(event, listener, false);
} else if(window.attachEvent) {
// Browser supports "attachEvent"
window.attachEvent("on" + event, listener);
}
}
/* ... */
myAddEventListener("load", myListener);And of course, whatever techniques you employ, no matter how bulletproof you believe they are, be sure to test thoroughly in all browsers that you intend to support.
当然,无论您采用哪种技术,无论您认为它们有多么出色的防弹技术,都一定要在打算支持的所有浏览器中进行全面测试。
问:比较并对比SASS,LESS和CSS,包括两者的优缺点。 (Q: Compare and contrast SASS, LESS and CSS, including advantages and disadvantages of each.)
First, to define our terms:
首先,定义我们的术语:
- CSS: Cascading Style Sheets CSS:级联样式表
- SASS: Syntactically Awesome Style Sheets SASS:语法很棒的样式表
- LESS Leaner Cascading Style Sheets LESS精简级联样式表
CSS refers to a set of static instructions that all W3C-compliant browsers (and others for that matter) understand. That static nature makes CSS simple. For each element that you want to customize, you need to have some combination of style rules coded that together will shape how it will look. That fact limits the opportunity for code reuse (throwing DRY out the window).
CSS是指所有W3C兼容浏览器(以及与此相关的其他浏览器)都可以理解的一组静态指令。 静态性质使CSS变得简单。 对于要自定义的每个元素,您需要对样式规则进行某种组合编码,以共同塑造外观。 这个事实限制了代码重用的机会(将DRY丢给窗口)。
Both SASS and LESS are derivative languages of CSS, but where they differ from CSS is that they make use of preprocessing to parse respective instructions into valid CSS. This preprocessing provides both languages with mechanisms for variables, inheritance, mixins, nested rules, logical operators and even loops. These are tools to address some of the major inconveniences of writing CSS, without having to dive into completely different languages such as PHP or JavaScript, since the syntax is very similar to CSS in both cases.
SASS和LESS都是CSS的派生语言,但它们与CSS的不同之处在于它们利用预处理将各自的指令解析为有效CSS。 这种预处理为两种语言提供了变量,继承,混合,嵌套规则,逻辑运算符甚至循环的机制。 这些工具可解决一些编写CSS的主要不便之处,而不必深入研究完全不同的语言(例如PHP或JavaScript),因为这两种语法都非常类似于CSS。
User interfaces and websites are becoming increasingly complex, as is landscape of browser layout engines (webkit, gecko, etc.). The ability to handle some of this complexity with dynamic rules can prove to be a big time saver in managing the look and feel of an application.
用户界面和网站以及浏览器布局引擎(webkit,gecko等)的格局正变得越来越复杂。 用动态规则处理这种复杂性的能力在管理应用程序的外观和感觉上可以节省大量时间。
A familiar example of the potential benefit of using preprocessed languages is in color management. Changing a site’s color palette in normal CSS can be arduous. Several files will normally need to be combed for the references to a specific color to be changed, and for each reference found, the question “do we want to change this one?” must be asked. On the other hand, with SASS or LESS, one could simply modify a single color variable and all references to that color variable will then reflect that change.
使用预处理语言的潜在好处的一个常见示例是颜色管理。 在普通CSS中更改网站的调色板可能很困难。 通常需要整理几个文件才能更改要更改的特定颜色的引用,对于找到的每个引用,都存在一个问题:“我们是否要更改此颜色?” 必须问。 另一方面,使用SASS或LESS,可以简单地修改单个颜色变量,然后对该颜色变量的所有引用将反映该更改。

服务器端 (Server-side)
The server is normally the workhorse of an application. It authenticates requests, processes data, applies business logic, and builds responses. Servers, and services, that are well architected and designed can make a significant difference in the performance and usability of your system.
服务器通常是应用程序的主力军。 它对请求进行身份验证,处理数据,应用业务逻辑并构建响应。 架构和设计合理的服务器和服务可以对系统的性能和可用性产生重大影响。
问:描述一些服务器端缓存要考虑的方法,技术和注意事项。 (Q: Describe some approaches, techniques, and considerations to be considered for server-side caching.)
With individual servers often serving the needs of hundreds if not thousands of clients, it is reasonably likely that they’ll receive (and need to respond to) multiple identical requests. Moreover, even requests that are not identical may still overlap in terms of the responses they need to provide. Accordingly, server-side caching can help improve performance by avoiding wasted use of server-side resources to perform the same operations redundantly.
由于单个服务器通常满足数百个甚至数千个客户端的需求,因此它们很有可能会收到(并且需要响应)多个相同的请求。 此外,就要求提供的响应而言,即使是不完全相同的请求也可能会重叠。 因此,服务器端缓存可以避免浪费服务器端资源来重复执行相同的操作,从而有助于提高性能。
Here are a few common key considerations to take into account when establishing a caching strategy:
在建立缓存策略时,以下是一些常见的关键注意事项:
- Cache size. Although RAM is generally cheap these days, consideration needs to be given to capacity (i.e., the amount of memory available) when setting your cache size. Allocating too high a percentage of total memory to the cache can have an overall impact on performance that is actually more detrimental than beneficial. 缓存大小。 尽管这些天RAM通常很便宜,但在设置缓存大小时需要考虑容量(即可用内存量)。 将太多的总内存分配给高速缓存可能会对性能产生总体影响,而实际上这是不利的,而不是有益的。
- Expiration of cache entries. Setting appropriate expiry on your cache elements and invalidating key value stores when your data changes can help with capacity as well. 高速缓存条目已过期。 在数据更改时,在缓存元素上设置适当的到期时间并使键值存储无效也可以帮助提高容量。
- Cache contents. Of course, deciding what to cache is perhaps the biggest challenge when designing a caching strategy. You might be inclined to cache data that is expensive to generate or compute, but depending how rarely it is used, this could be a waste of precious cache space. 缓存内容。 当然,在设计缓存策略时,决定要缓存的内容可能是最大的挑战。 您可能倾向于缓存生成或计算昂贵的数据,但是取决于数据的使用频率,这可能会浪费宝贵的缓存空间。
- Granularity of cache entries. Data objects are often comprised of multiple “sub-objects”. Should the object be stored in the cache including all its “sub-objects” or should be cached separately (or perhaps even not at all)? There’s no one-size-fits-all answer here; it all depends on the structure of your database and the nature and frequency of the client queries against that data store. 缓存条目的粒度。 数据对象通常由多个“子对象”组成。 该对象应该存储在包括其所有“子对象”的缓存中还是应该单独缓存(甚至根本不缓存)? 这里没有一种千篇一律的答案。 这一切都取决于数据库的结构以及针对该数据存储的客户端查询的性质和频率。
问:请解释什么是会话,并提供有关如何在服务器端跟踪会话的一般说明。 (Q: Explain what sessions are and provide a general description of how they are tracked on the server side.)
A session is a mechanism for persisting user data across multiple related requests. The process takes an identifying key as part of the incoming request, which in browser-based interactions typically come in the form of a client cookie.
会话是一种在多个相关请求之间持久保存用户数据的机制。 该过程将一个识别密钥作为传入请求的一部分,在基于浏览器的交互中,该密钥通常以客户端cookie的形式出现。
An application will instantiate a session object into memory. It can then add data to that object about how the current user is interacting with the application. When the application completes its execution cycle, it will close the session, and as such, the data gets serialized and written to some tier that can store the data for use in the next request for that user. The technology need only be able fulfill that storage requirement and so it can be a database, file, or some caching technology.
应用程序将实例化会话对象到内存中。 然后,它可以将有关当前用户如何与应用程序交互的数据添加到该对象。 当应用程序完成其执行周期时,它将关闭该会话,因此,数据将被序列化并写入可以存储该数据以供该用户的下一个请求中使用的某个层。 该技术仅需要能够满足该存储要求,因此它可以是数据库,文件或某些缓存技术。

运输 (Transport)
All too often, a web developer will have solid skills in a specific technology, but will fall short in their understanding of “how the pieces fit together”. In contrast, a top web developer will have a solid grasp on how requests are made, structured, and responded to.
Web开发人员常常会在特定技术上具有扎实的技能,但对“各个部分如何组合在一起”的理解将不足。 相比之下,顶尖的Web开发人员将对请求的发出,组织和响应方式有扎实的掌握。
问:什么是REST?什么是RESTful Web服务? 描述其特征。 (Q: What is REST and what is a RESTful Web Service? Describe its characteristics.)
REST (REpresentational State Transfer) is a client/server architecture in which data and functionality are considered resources and are accessed using Uniform Resource Identifiers (URIs). The resources are acted upon by using a set of simple, well-defined operations. REST is designed to use a stateless communication protocol, typically HTTP.
REST(代表性状态转移)是一种客户端/服务器体系结构,其中数据和功能被视为资源,可以使用统一资源标识符(URI)进行访问。 通过使用一组简单的,定义明确的操作对资源进行操作。 REST设计为使用无状态通信协议,通常为HTTP。
As discussed in the Java EE Tutorial, the following principles encourage RESTful applications to be simple, lightweight, and fast:
正如Java EE教程中讨论的那样,以下原则鼓励RESTful应用程序简单,轻量和快速:
- Resource identification through URI: A RESTful web service exposes a set of resources that identify the targets of the interaction with its clients. Resources are identified by URIs, which provide a global addressing space for resource and service discovery. 通过URI进行资源标识:RESTful Web服务公开了一组资源,这些资源标识了与其客户端进行交互的目标。 资源由URI标识,URI为资源和服务发现提供了全局寻址空间。
Uniform interface: Resources are manipulated via a specific set request types, the most common of which are:
统一接口:资源通过特定的设置请求类型进行操作,其中最常见的是:
- GET: Retrieves data from the server (should only retrieve data and should have no other effect). GET:从服务器检索数据(应仅检索数据,不应有其他影响)。
- POST: Sends data to the server for a new entity. It is often used when uploading a file or submitting a completed web form. POST:将数据发送到服务器以获取新实体。 上载文件或提交完整的Web表单时经常使用它。
- PUT: Similar to POST, but used to update an existing entity. PUT:与POST类似,但用于更新现有实体。
- DELETE: Remove data from the server. 删除:从服务器删除数据。
- Self-descriptive messages: Resources are decoupled from their representation so that their content can be accessed in a variety of formats. Metadata about the resource is available and used, for example, to control caching, detect transmission errors, negotiate the appropriate representation format, and perform authentication or access control. 自我描述消息:资源与它们的表示分离,因此可以以多种格式访问其内容。 有关资源的元数据可用并用于控制缓存,检测传输错误,协商适当的表示格式以及执行身份验证或访问控制。
- Stateful interactions through hyperlinks: Every interaction with a resource is stateless; that is, request messages are self-contained. Stateful interactions are based on the concept of explicit state transfer. Several techniques exist to exchange state, such as URI rewriting, cookies, and hidden form fields. State can be embedded in response messages to point to valid future states of the interaction. 通过超链接的状态交互:与资源的每次交互都是无状态的; 也就是说,请求消息是独立的。 有状态的交互基于显式状态转移的概念。 存在几种交换状态的技术,例如URI重写,cookie和隐藏的表单字段。 可以将状态嵌入响应消息中,以指向交互的有效将来状态。
If measured by the number of web services that use it, the RESTful Web Service (RWS) has emerged in recent years alone as the clear favorite over the previously-championed SOAP protocol. RWS’ relative ease of use is largely to be credited. In fact, REST has had such a large impact on the web that it has mostly displaced SOAP-based and WSDL-based interface design because it’s a considerably simpler style to use.
如果以使用它的Web服务的数量来衡量,RESTful Web Service(RWS)仅在最近几年就已成为对先前倡导的SOAP协议的最爱。 RWS的相对易用性在很大程度上要归功于它。 实际上,REST在Web上产生了如此巨大的影响,以至于它取代了基于SOAP和基于WSDL的界面设计,因为它使用起来相当简单。
问:简要说明以下每个HTTP请求方法:TRACE,OPTIONS,CONNECT和PATCH。 (Q: Give a brief description of each of the following HTTP Request Methods: TRACE, OPTIONS, CONNECT, and PATCH.)
Beyond the four standard RESTful Web Service operations already discussed, there are four additional methods that more advanced web developers may be familiar with:
除了已经讨论的四种标准RESTful Web Service操作之外,更高级的Web开发人员可能还熟悉四种其他方法:
- TRACE: Provides a means to test what a machine along the network path receives when a request is made. As such, it simply returns what was sent. 跟踪:提供一种方法来测试发出请求时网络路径上的计算机所接收的内容。 这样,它仅返回已发送的内容。
- OPTIONS: Allows a client to request information about the request methods supported by a service (or for the server where the service resides by using a * wildcard in the URI). The relevant response header is Allow and it simply lists the supported methods. 选项:允许客户端请求有关服务(或使用URI中的*通配符的服务所驻留的服务器)所支持的请求方法的信息。 相关的响应标头是Allow,它仅列出了支持的方法。
- HEAD: Same as a GET method for a resource, but returns only the response headers (i.e., with no entity-body). HEAD:与资源的GET方法相同,但仅返回响应头(即没有实体主体)。
- CONNECT: Primarily used to establish a network connection to a resource (usually via some proxy that can be requested to forward an HTTP request as TCP and maintain the connection). Once established, the response sends a 200 status code and a “Connection Established” message. CONNECT:主要用于建立与资源的网络连接(通常通过某些代理,可以请求该代理将HTTP请求作为TCP转发并维护连接)。 建立后,响应将发送200状态代码和“连接已建立”消息。
Some common techniques for HTTP server push include:
HTTP服务器推送的一些常见技术包括:
WebSocket API. WebSockets make it possible to open an interactive communication session between a client browser and a server. With this API, the client can send messages to a server and receive event-driven responses without having to poll the server for a reply.
WebSocket API 。 WebSockets使打开客户端浏览器和服务器之间的交互式通信会话成为可能。 使用此API,客户端可以将消息发送到服务器并接收事件驱动的响应,而不必轮询服务器以获取答复。
Pushlets. Pushlets are based on an open Source HTTP-based publish/subscribe framework that is AJAX-enabled. The approach takes advantage of persistent HTTP connections, leaving the response perpetually open (i.e., the server never terminates the response), effectively fooling the browser to remain in “loading” mode after the initial page load could be considered complete. The server then periodically sends snippets of JavaScript to update the content of the page, thereby achieving push capability. By using this technique, the client doesn’t need Java applets or other plug-ins in order to keep an open connection to the server. The client is automatically notified about new events, pushed by the server. (One serious drawback of this method, however, is the lack of control the server has over the browser timing out; a page refresh is always necessary if a timeout occurs on the browser end.)
Pushlets 。 Pushlets基于启用AJAX的基于HTTP的开源发布/订阅框架。 该方法利用了持久的HTTP连接,使响应永久打开(即,服务器永不终止响应),有效地欺骗了浏览器,使其在初始页面加载被视为完成之后仍保持在“加载”模式。 然后,服务器会定期发送JavaScript片段以更新页面的内容,从而实现推送功能。 通过使用此技术,客户端不需要Java小程序或其他插件即可保持与服务器的开放连接。 服务器将推送有关新事件的自动通知客户端。 (但是,此方法的一个严重缺点是服务器缺乏对浏览器超时的控制;如果在浏览器端发生超时,则始终需要刷新页面。)
Long polling. Long polling is really just a variation of the traditional polling technique, but it allows emulating a push mechanism under circumstances where a real push is not possible, such as sites with security policies that require rejection of incoming HTTP Requests. With long polling, the client requests information from the server exactly as in normal polling, except it polls at a much slower frequency. If the server does not have any information available for the client when the poll is received, instead of sending an empty response, the server holds the request open and waits for response information to become available. Once it does, the server immediately sends a response to the client, completing the open request. The usual response latency (the time between when the information first becomes available and the next client request) otherwise associated with polling clients is thereby eliminated.
长时间轮询 。 长轮询实际上只是传统轮询技术的一种变体,但是它允许在无法进行真正推送的情况下(例如,具有安全策略要求拒绝传入HTTP请求的站点)模拟推送机制。 使用长轮询时,客户端向服务器请求的信息与正常轮询中的请求完全相同,只是轮询频率要慢得多。 如果在收到轮询时服务器没有可供客户端使用的任何信息,则服务器将保持打开请求并等待响应信息变为可用,而不是发送空响应。 完成后,服务器将立即向客户端发送响应,从而完成打开请求。 从而消除了原本与轮询客户端相关联的常规响应等待时间(信息首次可用时与下一个客户端请求之间的时间)。
Flash XMLSocket relays. This technique, used by various chat applications, makes use of the XMLSocket object in a single-pixel Adobe Flash movie. Under the control of JavaScript, the client establishes a TCP connection to a unidirectional relay on the server. The relay server does not read anything from this socket; instead it immediately sends the client a unique identifier. The client then makes an HTTP request to the web server, including this identifier. The web application can then push messages addressed to the client to a local interface of the relay server, which relays them over the Flash socket.
Flash XMLSocket中继 。 各种聊天应用程序使用的这项技术利用了单像素Adobe Flash电影中的XMLSocket对象。 客户端在JavaScript的控制下,建立到服务器上单向中继的TCP连接。 中继服务器不会从此套接字读取任何内容; 而是立即向客户端发送一个唯一标识符。 然后,客户端向Web服务器发出HTTP请求,包括该标识符。 然后,Web应用程序可以将发送给客户端的消息推送到中继服务器的本地接口,该接口通过Flash套接字中继这些消息。

数据库 (Database)
As mentioned previously, there are many pieces to the web development puzzle, and not every qualified web developer will necessarily be skilled at all of them. Accordingly, many web developers may focus predominantly on the client side and will therefore have little expertise in the database domain. However, efficient database design, access, and manipulation is fairly central to the performance of most web-based systems and, as such, a web developer with strong database expertise can be extremely valuable to your project.
如前所述,Web开发难题涉及很多方面,并不是每个合格的Web开发人员都必须具备所有技能。 因此,许多Web开发人员可能主要专注于客户端,因此在数据库领域的专业知识很少。 但是,有效的数据库设计,访问和操作对于大多数基于Web的系统的性能至关重要,因此,具有强大数据库专业知识的Web开发人员对您的项目可能非常有价值。
问:标准化数据库是什么意思? 如何去做呢? 描述数据库规范化的潜在结果。 (Q: What does it mean to normalize a database? How does one go about doing it? Describe a potential consequence of database normalization.)
Database normalization is the process of organizing the fields and tables of a relational database to minimize redundancy. Normalization usually involves dividing large tables into smaller (and less redundant) tables and defining relationships between them. The objective is to isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database using the defined relationships.
数据库规范化是组织关系数据库的字段和表以最小化冗余的过程。 规范化通常涉及将大表划分为较小(和较少冗余)的表,并定义它们之间的关系。 目的是隔离数据,以便可以仅在一个表中进行字段的添加,删除和修改,然后使用定义的关系传播到数据库的其余部分。
A good way to begin to normalize your database is to first assess it against the normal forms of relational database theory. These normal forms provide criteria for determining a table’s degree of immunity against logical inconsistencies and anomalies. A database that satisfies the requirements of a certain level, must also satisfy all the previous levels. The first three of these levels are the ones most commonly used and are as follows:
开始规范数据库的一个好方法是首先根据关系数据库理论的正常形式对其进行评估。 这些标准形式提供了确定表对逻辑不一致和异常的免疫程度的标准。 满足一定级别要求的数据库还必须满足所有以前的级别。 这些级别中的前三个是最常用的级别,如下所示:
- First Normal Form (1NF) – Each field should represent one and only one value per entity; i.e., there should only be a single value per field (atomicity). For example, a Person may have two phone numbers. If an application stores both of them in the same field (e.g., the phone_number column of a table), that table does not meet the criteria for 1NF. 第一范式(1NF)–每个字段应代表一个实体,并且每个实体只能代表一个值; 即,每个场(原子性)应该只有一个值。 例如,一个人可能有两个电话号码。 如果应用程序将它们都存储在同一字段中(例如,表的phone_number列),则该表不符合1NF的条件。
- Second Normal Form (2NF) – No partial dependencies of columns on the primary key are allowed. For example, if a table has a multi-column primary key, none of the other columns can be dependent on only a susbet of the columns that comprise the primary key. 第二范式(2NF)–主键上的列不允许部分依赖。 例如,如果表具有多列主键,则其他任何列都不能仅依赖于构成主键的列的可疑状态。
- Third Normal Form (3NF) – All non-primary-key fields must be dependent on the primary key. If fields that are not part of the primary index are dependent on other non-primary fields for their values, then that table is not in the third normal form. For example, a table that includes a total column that is a sum of other fields in that row does not meet the criteria for 3NF. 第三范式(3NF)–所有非主键字段必须依赖于主键。 如果不属于主索引的字段的值依赖于其他非主字段的值,则该表不是第三范式。 例如,包含总计列(该行中其他字段的总和)的表不符合3NF的条件。
Assessing the compliance of your database with these normal forms can help identify and eliminate redundancies in your data model that can make it more efficient (and incidentally, this can also be beneficial in terms of determining the granularity of the entries in your cache). But as with anything in life, normalization does have its costs. The very act of spreading your data across several tables will likely require an increased number of table joins in your queries, which can also complicate your queries and possibly even your code. It also eliminates some potentially beneficial indexing scenarios, since data from multiple tables cannot be indexed. Retrieval can become expensive as well, and much more complicated when trying to filter or sort data in one table based on the values in another.
评估数据库是否符合这些常规形式可以帮助您识别和消除数据模型中的冗余,从而提高效率(顺便说一句,这在确定缓存中条目的粒度方面也可能是有益的)。 但是,就像生活中的任何事情一样,规范化确实有其代价。 跨多个表散布数据的行为很可能需要在查询中增加表联接的数量,这也可能使查询甚至代码复杂化。 由于无法对来自多个表的数据进行索引,因此它也消除了一些可能有益的索引方案。 检索也可能变得昂贵,并且在尝试根据另一个表中的值对一个表中的数据进行过滤或排序时会变得更加复杂。
That said, the best approach is usually a mix of these (and other architectural patterns) that suit the specific requirements of your application.
也就是说,最好的方法通常是将这些(和其他体系结构模式)混合在一起,以适合您的应用程序的特定要求。
问:描述一个哈希索引和一个BTree索引。 它们的相对优点和缺点是什么? (Q: Describe a Hash index and a BTree Index. What are some of their relative advantages and disadvantages?)
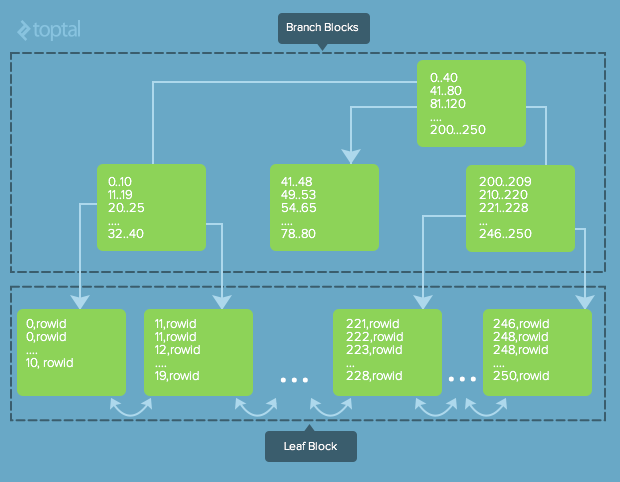
In any tree-based index, records are stored in locations called leaves. The starting point is called the root. The maximum number of children per node is called the order of the tree. The maximum number of access operations required to reach the desired leaf (data stored on the leaf) is called the depth (level). The general tree structure orders these ranges “left-to-right”. A key in a node can lead to a node where all the keys are less that its value to its left, or to a node where all the keys are greater than its value to its right.
在任何基于树的索引中,记录都存储在称为叶子的位置。 起点称为根。 每个节点的最大子代数称为树的顺序。 到达所需叶子(存储在叶子上的数据)所需的最大访问操作次数称为深度(级别)。 常规树结构将这些范围“从左到右”排序。 节点中的某个键可能会导致所有键都小于其左侧值的节点,或者导致所有键都大于其右侧值的节点。
The B-tree is a generalization of a binary search tree in that a node in a B-Tree is allowed to have more than two children. B-Tree indices help find information quickly by successively narrowing down data by assessing ranges of values stored in the node keys (nodes in the index contain keys and pointers to their child nodes). A B-Tree search starts at the root node and compares the range of keys in each child node against the key value being sought. When it finds the node whose range contains the desired key value, that node is selected and then its child nodes are assessed. This occurs until the process reaches the leaf pages where there are pointers to the actual data.
B树是二叉搜索树的概括,它允许B树中的一个节点具有两个以上的子节点。 B树索引通过评估存储在节点关键字(索引中的节点包含关键字和指向其子节点的指针)中的值的范围来依次缩小数据范围,从而帮助快速找到信息。 B树搜索从根节点开始,并将每个子节点中的键范围与要查找的键值进行比较。 当找到范围包含所需键值的节点时,将选择该节点,然后评估其子节点。 直到过程到达叶子页面(那里有指向实际数据的指针)之前,这种情况才会发生。
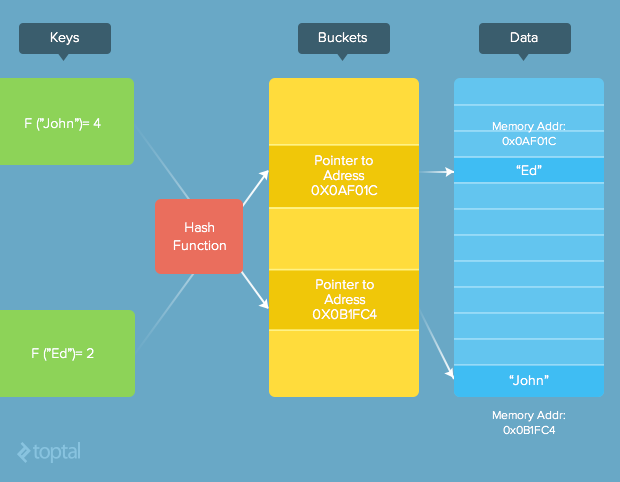
In a Hash Index, the values of the indexed column are run through a hash function to generate a location identifier for each key in the hash table. The table is divided into “buckets” and, depending on the technology employed, these buckets either contain the data values themselves or pointers to those values. Hash indexes are fast because the exact location of the bucket is known and the hash keys are ordered sequentially. Once a key location is found, the pre-hashed value (the one we are searching for) is compared to the one we’ve just found in the index to make sure it’s valid.
在哈希索引中,索引列的值通过哈希函数运行,以生成哈希表中每个键的位置标识符。 该表分为“存储桶”,根据使用的技术,这些存储桶要么包含数据值本身,要么包含指向这些值的指针。 散列索引之所以快速,是因为该存储桶的确切位置是已知的,并且散列键是按顺序排序的。 找到关键位置后,会将预哈希值(我们正在搜索的值)与我们刚刚在索引中找到的值进行比较,以确保其有效。
Hash indices work well, but only for purposes of equality comparisons. As such, hash indices can’t support queries of the form SELECT * FROM table WHERE key LIKE “valu% or SELECT * FROM table WHERE key < value. In contrast, B-Tree indices allow for much more flexibility in terms of what you can search for. Partial values and ranges of values are easily handled, all with roughly the same speed in a non-join search. In scenarios where either type of index will suite your purposes, there is no consistently “best” choice, since there are scenarios where hash indices outperform B-trees, and vice versa. It largely depends on the nature and structure of your data.
哈希索引工作良好,但仅用于相等比较的目的。 因此,哈希索引不能支持SELECT * FROM table WHERE key LIKE “valu% or SELECT * FROM table WHERE key < value 。 相反,B树索引在搜索内容方面具有更大的灵活性。 局部值和值范围很容易处理,在非联接搜索中,它们的速度大致相同。 在两种索引都适合您目的的方案中,没有一贯的“最佳”选择,因为在某些情况下哈希索引的性能优于B树,反之亦然。 它在很大程度上取决于数据的性质和结构。
问:简要描述和比较关系数据库,文档数据库和图形数据库。 (Q: Briefly describe and compare relational, document, and graph databases.)
Relational databases organize data into 2-dimensional tables and supports the notion of linking their contents based on known relationships. These relationships facilitate and simplify the integration and retrieval of data from multiple tables with a single query.
关系数据库将数据组织成二维表,并支持基于已知关系链接其内容的概念。 这些关系有助于并简化通过单个查询从多个表中进行数据的集成和检索。
While relational databases were a significant advance when they were originally introduced in the 1970s, new ways of storing data have since emerged that allow data to be grouped together more naturally and logically, and that loosen the restrictions on database schema. One of the most popular ways of storing data is a document database model, where each record and its associated data is thought of as a “document”. In a document database, everything related to a database object is encapsulated together. Storing data in this way has the following advantages:
尽管关系数据库在1970年代最初被引入时是一个重大的进步,但是后来出现了新的数据存储方式,可以使数据更加自然和逻辑地分组在一起,并且放宽了对数据库架构的限制。 文档数据库模型是最流行的数据存储方式之一,其中每个记录及其相关数据都被视为“文档”。 在文档数据库中,与数据库对象相关的所有内容都封装在一起。 以这种方式存储数据具有以下优点:
- Documents are independent units which makes performance better (related data is read contiguously off disk) and makes it easier to distribute data across multiple servers while preserving its locality. 文档是独立的单元,可以提高性能(从磁盘连续读取相关数据),并且可以更轻松地在多个服务器之间分发数据,同时保留其本地性。
- Application logic is easier to write. You don’t have to translate between objects in your application and SQL queries, you can just turn the object model directly into a document. 应用程序逻辑更易于编写。 您不必在应用程序中的对象和SQL查询之间进行转换,只需将对象模型直接转换为文档即可。
- Unstructured data can be stored easily, since a document contains whatever keys and values the application logic requires. In addition, costly migrations are avoided since the database does not need to know its information schema in advance. 非结构化数据可以轻松存储,因为文档包含应用程序逻辑所需的任何键和值。 另外,由于数据库不需要事先知道其信息模式,因此避免了昂贵的迁移。
Document databases generally have powerful query engines and indexing features that make it easy and fast to execute many different optimized queries. The strength of a document database’s query language is an important differentiator.
文档数据库通常具有强大的查询引擎和索引功能,可轻松快速地执行许多不同的优化查询。 文档数据库的查询语言的强度是一个重要的区别因素。
Another relatively recent advance in database modeling came about with the advent of graph databases. Graph databases, based on graph theory, use graph structures with nodes, edges, and properties to represent and store data. In a graph database, every element contains a direct pointer to its adjacent elements and no index lookups are necessary.
图数据库的出现带来了数据库建模的另一个相对较新的进展。 基于图论的图数据库使用具有结点,边线和属性的图结构来表示和存储数据。 在图形数据库中,每个元素都包含一个指向其相邻元素的直接指针,并且不需要索引查找。
Compared with relational databases, graph databases are often faster for associative datasets, and map more directly to the structure of object oriented applications. They can also scale more naturally to large datasets as they do not typically require expensive join operations. As they depend less on a rigid schema, they are more suitable to manage ad-hoc and changing data with evolving schemas. Graph databases are an especially powerful tool for graph-like queries (e.g., computing the shortest path between two nodes in the graph). Conversely, relational databases are typically faster at performing the same operation on large numbers of data elements.
与关系数据库相比,图形数据库对于关联数据集通常更快,并且更直接地映射到面向对象应用程序的结构。 由于它们通常不需要昂贵的联接操作,因此它们也可以更自然地扩展到大型数据集。 由于它们较少依赖于严格的模式,因此它们更适合于通过不断发展的模式管理临时数据和更改数据。 图数据库是用于类似图的查询(例如,计算图中两个节点之间的最短路径)的特别强大的工具。 相反,关系数据库通常在对大量数据元素执行相同操作时更快。
结语 (Wrap-up)
It is important to bear in mind that the questions provided herein are intended merely as a guide. Not every “A” candidate worth hiring will be able to properly answer them all, nor does answering them all guarantee an “A” candidate. At the end of the day, hiring remains as much of an art as it does a science.
重要的是要记住,本文提供的问题仅作为指导。 并非每个值得招聘的“ A”候选人都能正确回答所有问题,也不能全部回答都能保证一个“ A”候选人。 归根结底,招聘仍然是一门艺术和一门科学。
The questions and answers presented in this guide can be highly valuable in your quest for solid web developers, but are meant to augment an overall effective recruiting strategy, such as described in this post, In Search of the Elite Few.
本指南中提出的问题和答案对于您寻求扎实的Web开发人员而言可能是非常有价值的,但它们的目的是增强整体有效的招聘策略,例如本博文《 In Search of the Elite Few》中所述 。
翻译自: https://www.sitepoint.com/vital-guide-interviewing-web-developers/
web开发指南















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









