





pear
I was recently looking for a hosting service for an application I was developing. I decided to investigate Orchestra.io, as I was expecting it to get surges of traffic at specific points during each year and needed the application to scale accordingly. In the process of reviewing documentation for Orchestra.io, I found that it doesn’t allow file uploads. Instead, it’s recommended that Amazon S3 be used for file hosting.
我最近正在为正在开发的应用程序寻找托管服务。 我决定研究Orchestra.io ,因为我希望它在每年的特定时间点会激增流量,因此需要相应地扩展应用程序。 在审查Orchestra.io的文档的过程中,我发现它不允许文件上传 。 相反,建议将Amazon S3用于文件托管。
If you aren’t familiar with it, S3 is an online storage web service that is part of Amazon Web Services (AWS). It provides access to fairly cheap storage through a variety of web service interfaces. This article will demonstrate how to sign up for an Amazon S3 account and use PEAR’s Services_Amazon_S3 package to interact with S3 in your own application.
如果您不熟悉S3,它是一种在线存储Web服务,它是Amazon Web Services(AWS)的一部分。 它通过各种Web服务接口提供对相当便宜的存储的访问。 本文将演示如何注册Amazon S3帐户以及如何使用PEAR的Services_Amazon_S3程序包在您自己的应用程序中与S3进行交互。
注册Amazon S3 (Registering for Amazon S3)
The first step in this process is to sign up for your own S3 account at aws.amazon.com/s3. Once there, find and click the “Sign Up Now” button on the right and then simply follow the provided instructions.
此过程的第一步是在aws.amazon.com/s3上注册您自己的S3帐户。 到达那里后,找到并单击右侧的“立即注册”按钮,然后只需按照提供的说明进行操作即可。
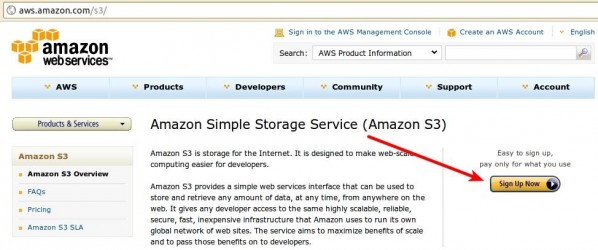
Shortly afterward, you should receive an e-mail at the address you provided with further instructions. If you don’t, or you lose your copy, you can simply go to the AWS Management Console at console.aws.amazon.com/s3. This area of the site will provide you with your Access Identifiers, credentials that are required for you to be able to write data to S3. If you’ve used a web service API that required an access token, these Access Identifiers serve the same purpose. Once you’ve opened the Console page, look in the top right-hand corner for a menu labeled with your name. Click on it to expand it and click on the “Security Credentials” option.
之后不久,您应该在提供的进一步说明的地址处收到一封电子邮件。 如果不这样做,或者丢失了副本,则可以简单地转到console.aws.amazon.com/s3上的AWS管理控制台。 该站点的该区域将为您提供访问标识符,这些标识符是您能够将数据写入S3所必需的。 如果您使用了需要访问令牌的Web服务API,则这些访问标识符具有相同的目的。 打开“控制台”页面后,在右上角查找带有您的名字的菜单。 单击它以展开它,然后单击“安全凭据”选项。
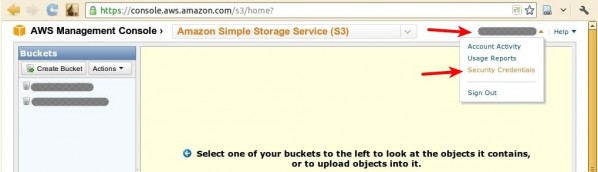
Once you’re on the “Security Credentials” page, scroll down and find the “Access Credentials” section. Here, you’ll find your Access Key ID displayed. Click on the “Show” link near it to display your Secret Access Key. These two pieces of information are all that’s needed to access your S3 account. Be sure to keep them safe.
进入“安全凭据”页面后,向下滚动并找到“访问凭据”部分。 在这里,您会找到显示的访问密钥ID。 单击旁边的“显示”链接以显示您的秘密访问密钥。 这两项信息都是访问S3帐户所需的全部信息。 确保安全。
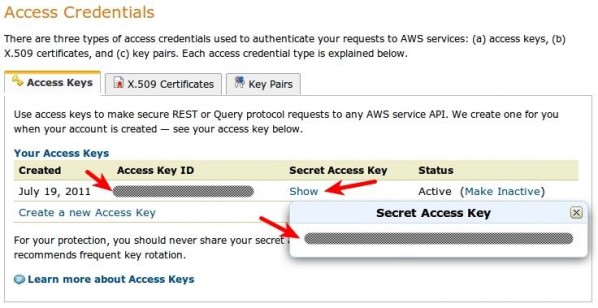
The two tabs next to the “Access Keys” tabs are specific to services other than S3. More specifically, X.509 certificates are used for making secure requests when using AWS SOAP APIs (with the exception of those for S3 and Mechanical Turk – those use Access Keys instead) and Key Pairs are used for Amazon CloudFront and EC2.
“访问键”选项卡旁边的两个选项卡特定于S3以外的服务。 更具体地说,X.509证书用于在使用AWS SOAP API时发出安全请求(S3和Mechanical Turk除外,它们使用访问密钥),而密钥对则用于Amazon CloudFront和EC2。
Now that you have your Access Identifiers, return to the console page. On the left you’ll find a listing of buckets, which will start out empty. A bucket is simply a named container for a set of files. If you’re using S3 on multiple sites, this mechanism can help you to keep your files for each site separate and organized. You’ll need to create a bucket before you proceed.
现在您已经有了访问标识符,请返回到控制台页面。 在左侧,您会找到一个存储桶列表,该列表将开始为空。 存储桶只是一组文件的命名容器。 如果您在多个站点上使用S3,则此机制可以帮助您将每个站点的文件分开并组织。 在继续操作之前,您需要创建一个存储桶 。
安装服务_Amazon_S3 (Installing Services_Amazon_S3)
Next, you need an installation of the Services_Amazon_S3 PEAR package. It’s possible but unlikely that your server already has one unless you have administrative privileges. As such, you’ll probably need a local PEAR copy suitable for a shared hosting environment.
接下来,您需要安装Services_Amazon_S3 PEAR软件包。 除非您具有管理特权,否则您的服务器可能已经拥有一台服务器,但这种可能性不大。 因此,您可能需要适合共享托管环境的本地PEAR副本 。
The easiest way to do this is to create this installation on a machine for which you do have administrative privileges and an existing PEAR installation, then copy that installation to your intended hosting environment. On a *NIX system, this can be accomplished by running the following commands from a terminal:
最简单的方法是在您确实具有管理特权和现有PEAR安装的计算机上创建此安装,然后将该安装复制到您预期的托管环境中。 在* NIX系统上,这可以通过从终端运行以下命令来完成:
root@foobox:~# pear config-create `pwd` .pearrc
root@foobox:~# pear -c .pearrc install -o Services_Amazon_S3
This will create a pear directory within the current working directory. Within that directory is a php directory that contains the actual PHP code for the installed PEAR package and its dependencies. This is the only directory you need to make use of the S3 code in your own code; you can copy it or its contents as-is into whatever directory in your project is reserved for third-party dependencies.
这将在当前工作目录中创建一个pear目录。 在该目录中是一个php目录,其中包含已安装的PEAR软件包及其依赖项的实际PHP代码。 这是您需要在自己的代码中使用S3代码的唯一目录。 您可以将其或其内容按原样复制到项目中为第三方依赖项保留的任何目录中。
In order to actually make use of the code, you’ll need to add the directory containing the Services subdirectory to your include_path. If /path/to/dir is the full path to the directory containing Services, it can be added to the include_path like so:
为了实际使用代码,您需要将包含Services子目录的目录添加到include_path 。 如果/path/to/dir是包含Services的目录的完整路径,则可以将其添加到include_path如下所示:
<?php
set_include_path(get_include_path() . PATH_SEPARATOR . "/path/to/dir");The remainder of this article assumes that you have a proper autoloader in place to load classes from this directory as they’re used.
本文的其余部分假定您已准备好适当的自动加载器 ,以在使用它们时从此目录加载类。
使用服务_Amazon_S3 (Using Services_Amazon_S3)
There are two ways to use Services_Amazon_S3: programmatically using the API, or via streams using the stream wrapper. While code using streams can be more concise, it can also be susceptible to bugs in the PHP core related to stream contexts. An example of this is a bug fixed in PHP 5.3.4 where the copy() function did not actually use the $context parameter value if one was provided. It’s recommended that you check the PHP changelog against your PHP version before deciding which method to use.
有两种使用Services_Amazon_S3 :以编程方式使用API,或通过使用流包装器的流。 尽管使用流的代码可能更简洁,但它也容易受到与流上下文有关PHP核心中的错误的影响。 这样的一个示例是PHP 5.3.4中修复的错误,该错误中,如果提供了一个,则copy()函数实际上并未使用$context参数值。 建议您在决定使用哪种方法之前,先对照PHP版本检查PHP更新日志。
使用S3 Stream包装器 (Using the S3 Stream Wrapper)
Let’s look at the streams method first. In addition to the access key ID and secret access key, there are two pieces of information that S3 needs about a file: a string defining who has access to the file (which is private by default) and a MIME type indicating the file’s content type (which defaults to a generic binary type that browsers won’t attempt to render). When using the streams wrapper, all this information is communicated using stream contexts. Let’s look at what processing a file upload might look like:
首先让我们看一下stream方法。 除了访问密钥ID和秘密访问密钥之外,S3还需要有关文件的两部分信息:一个字符串,该字符串定义谁有权访问该文件(默认情况下为private ),以及一个MIME类型,指示文件的内容类型(默认为浏览器不会尝试呈现的通用二进制类型)。 使用流包装器时,所有这些信息都使用流上下文进行通信。 让我们看一下文件上传的处理方式:
<?php
if (is_uploaded_file($_FILES["fieldname"]["tmp_name"])) {
Services_Amazon_S3_Stream::register();
$context = stream_context_create(array(
"s3" => array(
"access_key_id" => "access_key_id",
"secret_access_key" => "secret_access_key",
"content_type" => $_FILES["fieldname"]["type"],
"acl" => "public-read")));
copy($_FILES["fieldname"]["tmp_name"],
"s3://bucketname/" . $_FILES["fieldname"]["name"],
$context);
}This code processes a file upload submitted using an HTML form. This form contains a file field with the name fieldname. The content_type context option is assigned the MIME type provided for this field by the $_FILES superglobal. The acl context option controls who can access the file once it’s uploaded. In this case, because I was using S3 to host public static files, I used a simple public-read canned ACL that allows anyone to view it. S3 access control allows for much more fine-grained permissions; mine was a very common but simple use case.
此代码处理使用HTML表单提交的文件上传。 此表单包含一个名为fieldname的文件fieldname 。 $_FILES超全局变量为content_type上下文选项分配了为此字段提供的MIME类型。 acl上下文选项控制文件上传后谁可以访问文件。 在这种情况下,因为我使用S3托管公共静态文件,所以我使用了一个简单的public-read 罐头ACL ,任何人都可以查看它。 S3访问控制允许更多细粒度的权限; 我的是一个非常普遍但简单的用例。
Once the stream context is created, the file can be uploaded to S3 by using the copy() function. The source is a path provided by $_FILES that points to a temporary local copy of the uploaded file; once the request terminates, this copy will be deleted. The destination references the s3 wrapper, the name of the bucket to contain the file (bucketname), and finally a name for the file, in this case the original name of the file as it was uploaded as retrieved from $_FILES.
一旦创建了流上下文,就可以使用copy()函数将文件上传到S3。 源是$_FILES提供的路径,该路径指向上载文件的临时本地副本。 请求终止后,该副本将被删除。 目标引用s3包装器,包含文件的存储桶的名称( bucketname ),最后是文件的名称,在本例中,是从$_FILES检索到的上载文件的原始名称。
Note that it is possible to specify a relative path instead of just a name. If strict mode is disabled (which it is by default), S3 will simply accept the path and use the appropriate directory structure in the AWS console. Directories do not need to be created in advance in this case.
请注意,可以指定相对路径而不只是名称。 如果禁用了严格模式 (默认情况下为默认模式),则S3将仅接受路径并在AWS控制台中使用适当的目录结构。 在这种情况下,不需要预先创建目录。
One other circumstance of my particular use case was that a file may have previously been uploaded to S3 that corresponded to a particular database record. Multiple file extensions were supported and maintained when files were uploaded to S3. As such, the name of a file for a record wouldn’t always necessarily be the same and I would need to delete any existing file corresponding to a record before uploading a new one.
我的特定用例的另一种情况是,先前可能已将一个文件上传到S3,该文件对应于特定的数据库记录。 将文件上传到S3时,支持并维护了多个文件扩展名。 因此,用于记录的文件名不一定总是相同,并且在上传新文件之前,我需要删除与该记录对应的任何现有文件。
If I stored the name of any existing file for a record, doing this was relatively trivial. Otherwise, it was is a bit clunky because of how the stream wrapper uses the API; I had to iterate over the files in a directory to find a file matching a predetermined prefix that indicated it corresponded to the record. Here’s how to handle both situations:
如果我将任何现有文件的名称存储为记录,则这样做相对简单。 否则,由于流包装器如何使用API,这有点笨拙。 我必须遍历目录中的文件,以找到与预定前缀匹配的文件,该前缀表明该文件与记录相对应。 这是处理两种情况的方法:
<?php
// If the existing filename is known...
unlink("s3://bucketname/path/to/file");
// If the existing filename is not known...
$it = new DirectoryIterator("s3://bucketname/path/to/dir");
foreach ($it as $entry) {
$filename = $entry->getFilename();
if (strpos($filename, $prefix) === 0) {
unlink("s3://bucketname/path/to/dir/$filename");
break;
}
}使用S3 API (Using the S3 API)
The same file upload using the S3 API would look like this:
使用S3 API上传的相同文件如下所示:
<?php
$s3 = Services_Amazon_S3::getAccount("access_key_id", "secret_access_key");
$bucket = $s3->getBucket("bucketname");
$object = $bucket->getObject($_FILES["fieldname"]["name"]);
$object->acl = "public-read";
$object->contentType = $_FILES["fieldname"]["type"];
$object->data = file_get_contents($_FILES["fieldname"]["tmp_name"]);
$object->save();All the same information is being provided to the code, it’s just done via method calls and value assignments to public properties instead of stream contexts and URLs. Again, a relative path within the bucket can be provided in place of the name in this example. As you can see, using the API to upload files requires a bit more hoop-jumping in terms of retrieving objects and manually reading in the file data before explicitly saving the object out to S3.
所有相同的信息都将提供给代码,只是通过方法调用和对公共属性的值分配(而不是流上下文和URL)来完成。 同样,在此示例中,可以提供存储桶内的相对路径来代替名称。 如您所见,在将对象明确保存到S3之前,使用API上传文件在检索对象和手动读取文件数据方面需要更多的跳跃。
However, the API does make deleting an existing file with a given prefix a bit easier than it is with the s3 stream wrapper. After obtaining the object representing the bucket containing the file, you can simply do this:
但是,与使用s3流包装器相比,该API确实使删除具有给定前缀的现有文件更加容易。 获得代表包含文件的存储桶的对象后,您可以简单地执行以下操作:
<?php
foreach ($bucket->getObjects($prefix) as $object) {
$object->delete();
}摘要 (Summary)
The Services_Amazon_S3 package makes it fairly easy to get up and running quickly with S3 even if you’ve never use the service before. It handles all the low-level details of interacting with S3 for you, leaving you to specify what data you want to operate on and what operation you want to carry out.
即使您以前从未使用过该服务,也可以通过Services_Amazon_S3软件包轻松轻松地启动和运行S3。 它为您处理了与S3交互的所有低级细节,让您指定要操作的数据以及要执行的操作。
Which method you choose, streams or API, really comes down to how you’re using S3 and what your personal preference is. As this article shows, code can be more or less verbose with either method depending on what it is that you’re doing.
选择哪种方法,流或API,实际上取决于您使用S3的方式以及您的个人喜好。 如本文所示,这两种方法中的代码多少有些冗长,这取决于您正在执行的操作。
Hopefully this article has given you a small taste of the capabilities of S3 as a service. I encourage you to read more about S3, study examples and API documentation for Services_Amazon_S3, and consider integrating them both into your applications.
希望本文使您对S3作为服务的功能有所了解。 我鼓励您阅读有关S3的更多信息 ,研究Services_Amazon_S3 示例和API文档 ,并考虑将它们都集成到您的应用程序中。
Image via Marcin Balcerzak / Shutterstock
图片来自Marcin Balcerzak / Shutterstock
翻译自: https://www.sitepoint.com/integrating-amazon-s3-using-pear/
pear















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









