





As you may know, I am the author and maintainer of the PHP League‘s CommonMark Markdown parser. This project has three primary goals:
您可能知道,我是PHP League的CommonMark Markdown解析器的作者和维护者。 该项目具有三个主要目标:
fully support the entire CommonMark spec
完全支持整个CommonMark规范
match the behavior of the JS reference implementation
匹配JS参考实现的行为
- be well-written and super-extensible so that others can add their own functionality. 具有良好的编写能力和超强的可扩展性,以便其他人可以添加自己的功能。
This last goal is perhaps the most challenging, especially from a performance perspective. Other popular Markdown parsers are built using single classes with massive regex functions. As you can see from this benchmark, it makes them lightning fast:
最后一个目标可能是最具挑战性的,尤其是从性能角度而言。 其他流行的Markdown解析器是使用具有大量正则表达式功能的单个类构建的。 从该基准中可以看到,它使它们闪电般快速:
| Library | Avg. Parse Time | File/Class Count |
|---|---|---|
| Parsedown 1.6.0 | 2 ms | 1 |
| PHP Markdown 1.5.0 | 4 ms | 4 |
| PHP Markdown Extra 1.5.0 | 7 ms | 6 |
| CommonMark 0.12.0 | 46 ms | 117 |
| 图书馆 | 平均 解析时间 | 文件/类计数 |
|---|---|---|
| 解析器1.6.0 | 2毫秒 | 1个 |
| PHP Markdown 1.5.0 | 4毫秒 | 4 |
| PHP Markdown Extra 1.5.0 | 7毫秒 | 6 |
| CommonMark 0.12.0 | 46毫秒 | 117 |
Unfortunately, because of the tightly-coupled design and overall architecture, it’s difficult (if not impossible) to extend these parsers with custom logic.
不幸的是,由于紧密的设计和整体架构,很难(如果不是不可能)用自定义逻辑扩展这些解析器。
For the League’s CommonMark parser, we chose to prioritize extensibility over performance. This led to a decoupled object-oriented design which users can easily customize. This has enabled others to build their own integrations, extensions, and other custom projects.
对于联盟的CommonMark解析器,我们选择优先考虑可扩展性而不是性能。 这导致了脱钩的面向对象设计, 用户可以轻松地对其进行自定义 。 这使其他人可以构建自己的集成 , 扩展和其他自定义项目 。
The library’s performance is still decent — the end user probably can’t differentiate between 42ms and 2ms (you should be caching your rendered Markdown anyway). Nevertheless, we still wanted to optimize our parser as much as possible without compromising our primary goals. This blog post explains how we used Blackfire to do just that.
库的性能仍然不错–最终用户可能无法区分42ms和2ms(无论如何,您都应该缓存渲染的Markdown)。 尽管如此,我们仍然希望在不损害我们主要目标的情况下尽可能优化分析器。 这篇博客文章解释了我们如何使用Blackfire做到这一点。
使用Blackfire进行分析 (Profiling with Blackfire)
Blackfire is a fantastic tool from the folks at SensioLabs. You simply attach it to any web or CLI request and get this awesome, easy-to-digest performance trace of your application’s request. In this post, we’ll be examining how Blackfire was used to identify and optimize two performance issues found in version 0.6.1 of the league/commonmark library.
Blackfire是SensioLabs员工的绝佳工具。 您只需将其附加到任何Web或CLI请求上,即可获得应用程序请求的出色且易于理解的性能跟踪。 在本文中,我们将研究如何使用Blackfire来识别和优化在League / Commonmark库的0.6.1版本中发现的两个性能问题。
Let’s start by profiling the time it takes league/commonmark to parse the contents of the CommonMark spec document:
让我们开始分析联盟/通用标记解析CommonMark规范文档的内容所花费的时间:
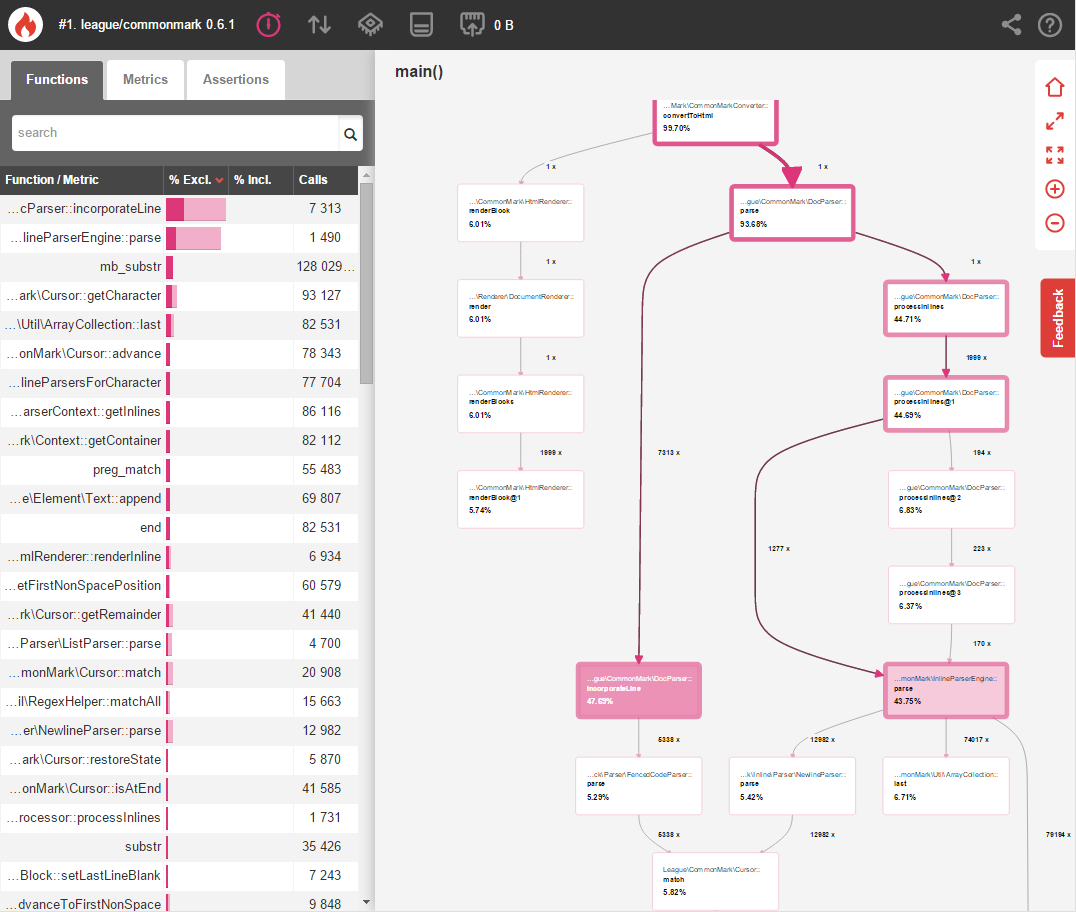
Later on we’ll compare this benchmark to our changes in order to measure the performance improvements.
稍后,我们将将此基准与我们的更改进行比较,以衡量性能改进。
Quick side-note: Blackfire adds overhead while profiling things, so the execution times will always be much higher than usual. Focus on the relative percentage changes instead of the absolute “wall clock” times.
快速旁注: Blackfire在对事物进行概要分析时会增加开销,因此执行时间将始终比平时高得多。 关注于相对百分比变化,而不是绝对的“挂钟”时间。
优化1 (Optimization 1)
Looking at our initial benchmark, you can easily see that inline parsing with InlineParserEngine::parse() accounts for a whopping 43.75% of the execution time. Clicking this method reveals more information about why this happens:
查看我们的初始基准测试,您可以轻松地看到,使用InlineParserEngine::parse()进行内联解析占执行时间的高达43.75%。 单击此方法将显示有关发生这种情况的更多信息:
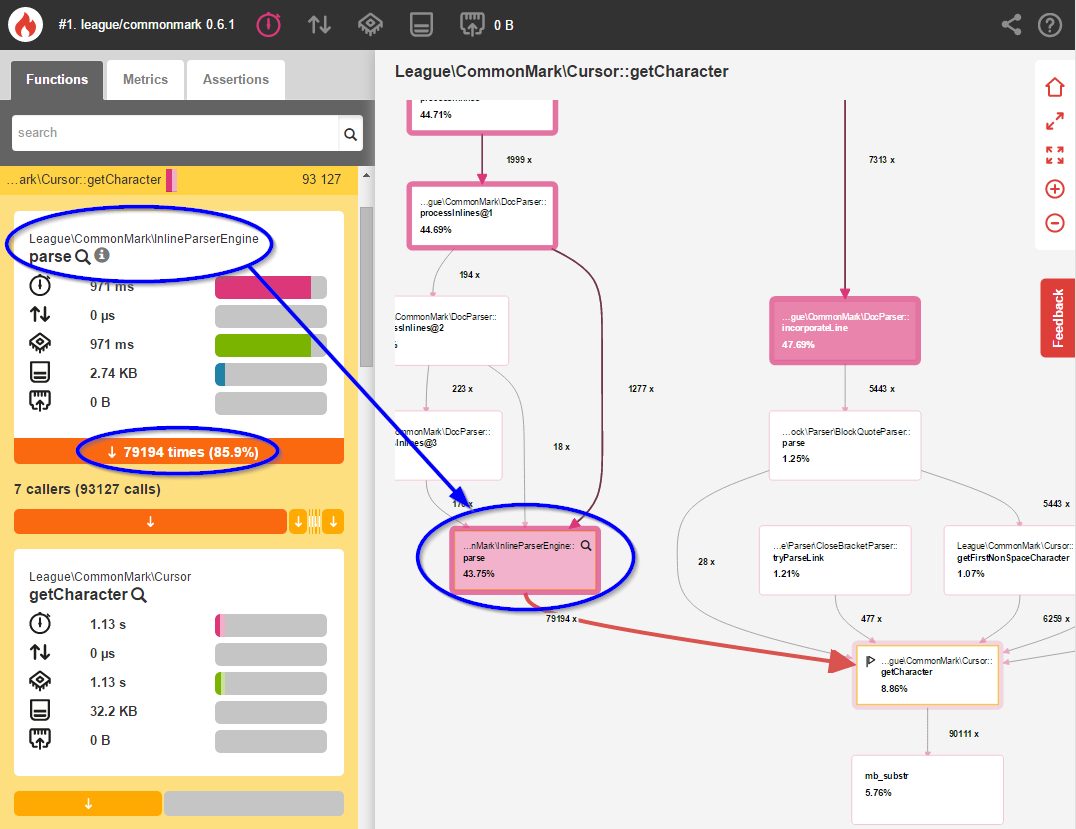
Here we see that InlineParserEngine::parse() is calling Cursor::getCharacter() 79,194 times — once for every single character in the Markdown text. Here’s a partial (slightly-modified) excerpt of this method from 0.6.1:
在这里,我们看到InlineParserEngine::parse()调用Cursor::getCharacter() 79,194次—对于Markdown文本中的每个单个字符一次。 这是此方法的部分摘录(略作修改),摘自0.6.1:
public function parse(ContextInterface $context, Cursor $cursor)
{
// Iterate through every single character in the current line
while (($character = $cursor->getCharacter()) !== null) {
// Check to see whether this character is a special Markdown character
// If so, let it try to parse this part of the string
foreach ($matchingParsers as $parser) {
if ($res = $parser->parse($context, $inlineParserContext)) {
continue 2;
}
}
// If no parser could handle this character, then it must be a plain text character
// Add this character to the current line of text
$lastInline->append($character);
}
}Blackfire tells us that parse() is spending over 17% of its time checking every. single. character. one. at. a. time. But most of these 79,194 characters are plain text which don’t need special handling! Let’s optimize this.
Blackfire告诉我们parse()花费了超过17%的时间检查每个对象。 单。 字符。 之一。 在。 一个。 时间 。 但是,这些79,194个字符中的大多数都是纯文本,不需要特殊处理! 让我们对其进行优化。
Instead of adding a single character at the end of our loop, let’s use a regex to capture as many non-special characters as we can:
与其在循环的末尾添加单个字符,不如使用正则表达式来捕获尽可能多的非特殊字符:
public function parse(ContextInterface $context, Cursor $cursor)
{
// Iterate through every single character in the current line
while (($character = $cursor->getCharacter()) !== null) {
// Check to see whether this character is a special Markdown character
// If so, let it try to parse this part of the string
foreach ($matchingParsers as $parser) {
if ($res = $parser->parse($context, $inlineParserContext)) {
continue 2;
}
}
// If no parser could handle this character, then it must be a plain text character
// NEW: Attempt to match multiple non-special characters at once.
// We use a dynamically-created regex which matches text from
// the current position until it hits a special character.
$text = $cursor->match($this->environment->getInlineParserCharacterRegex());
// Add the matching text to the current line of text
$lastInline->append($character);
}
}Once this change was made, I re-profiled the library using Blackfire:
做出更改后,我使用Blackfire重新配置了该库:
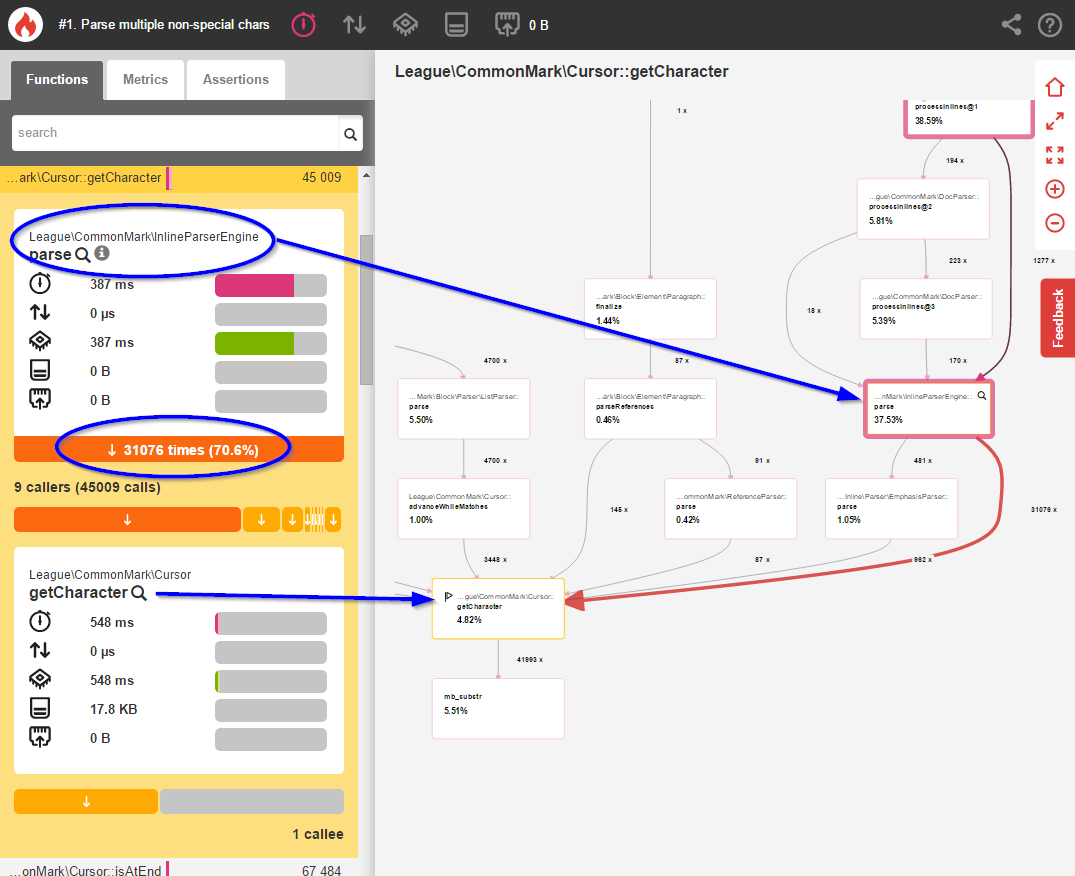
Okay, things are looking a little better. But let’s actually compare the two benchmarks using Blackfire’s comparison tool to get a clearer picture of what changed:
好的,情况看起来好一些。 但实际上,让我们使用Blackfire的比较工具比较两个基准,以更清楚地了解更改的内容:
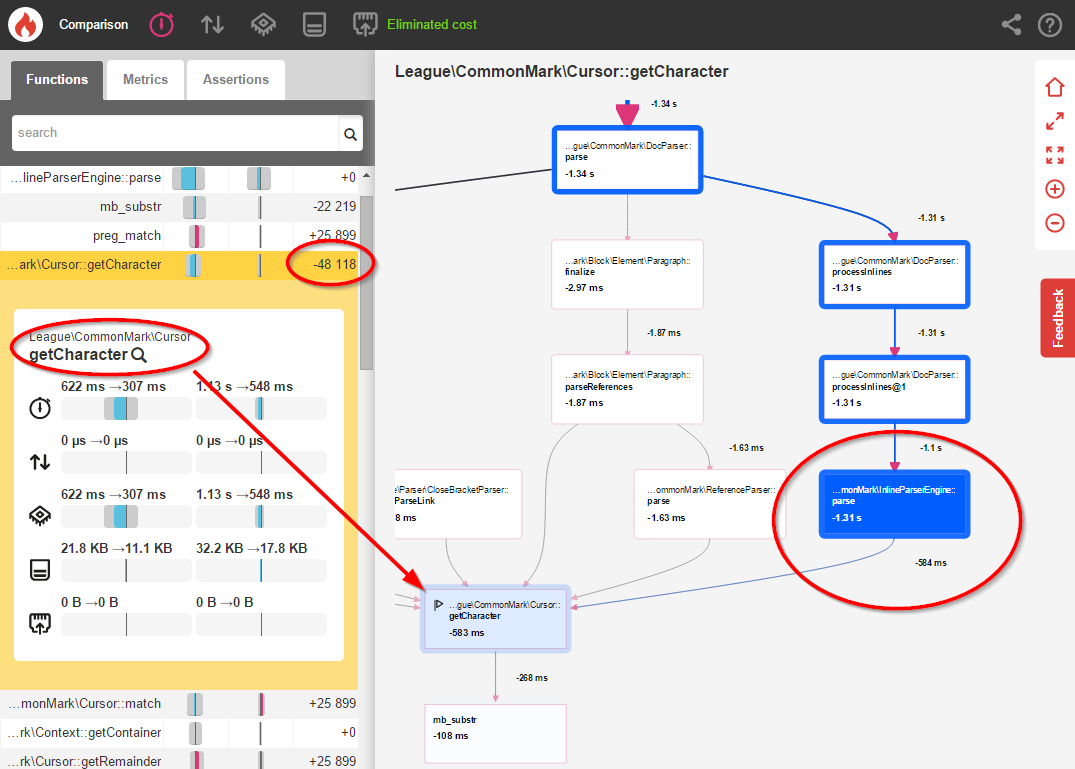
This single change resulted in 48,118 fewer calls to that Cursor::getCharacter() method and an 11% overall performance boost! This is certainly helpful, but we can optimize inline parsing even further.
单个更改导致对该Cursor::getCharacter()方法的调用减少了48,118次 ,并且总体性能提高了11% ! 这当然是有帮助的,但是我们可以进一步优化内联解析。
优化2 (Optimization 2)
According to the CommonMark spec:
根据CommonMark规范 :
A line break … that is preceded by two or more spaces … is parsed as a hard line break (rendered in HTML as a tag)
换行符…前面有两个或多个空格…被解析为硬换行符(在HTML中作为标记呈现)
Because of this language, I originally had the NewlineParser stop and investigate every space and \n character it encountered. Here’s an example of what that original code looked like:
由于这种语言,我本来是让NewlineParser停止并调查它遇到的每个空格和\n字符的。 这是原始代码的示例:
class NewlineParser extends AbstractInlineParser {
public function getCharacters() {
return array("\n", " ");
}
public function parse(ContextInterface $context, InlineParserContext $inlineContext) {
if ($m = $inlineContext->getCursor()->match('/^ *\n/')) {
if (strlen($m) > 2) {
$inlineContext->getInlines()->add(new Newline(Newline::HARDBREAK));
return true;
} elseif (strlen($m) > 0) {
$inlineContext->getInlines()->add(new Newline(Newline::SOFTBREAK));
return true;
}
}
return false;
}
}Most of these spaces weren’t special, and it was therefore wasteful to stop at each one and check them with a regex. You can easily see the performance impact in the original Blackfire profile:
这些空间大多数都不特殊,因此在每个空间停下来并使用正则表达式检查它们是浪费的。 您可以在原始Blackfire配置文件中轻松查看性能影响:
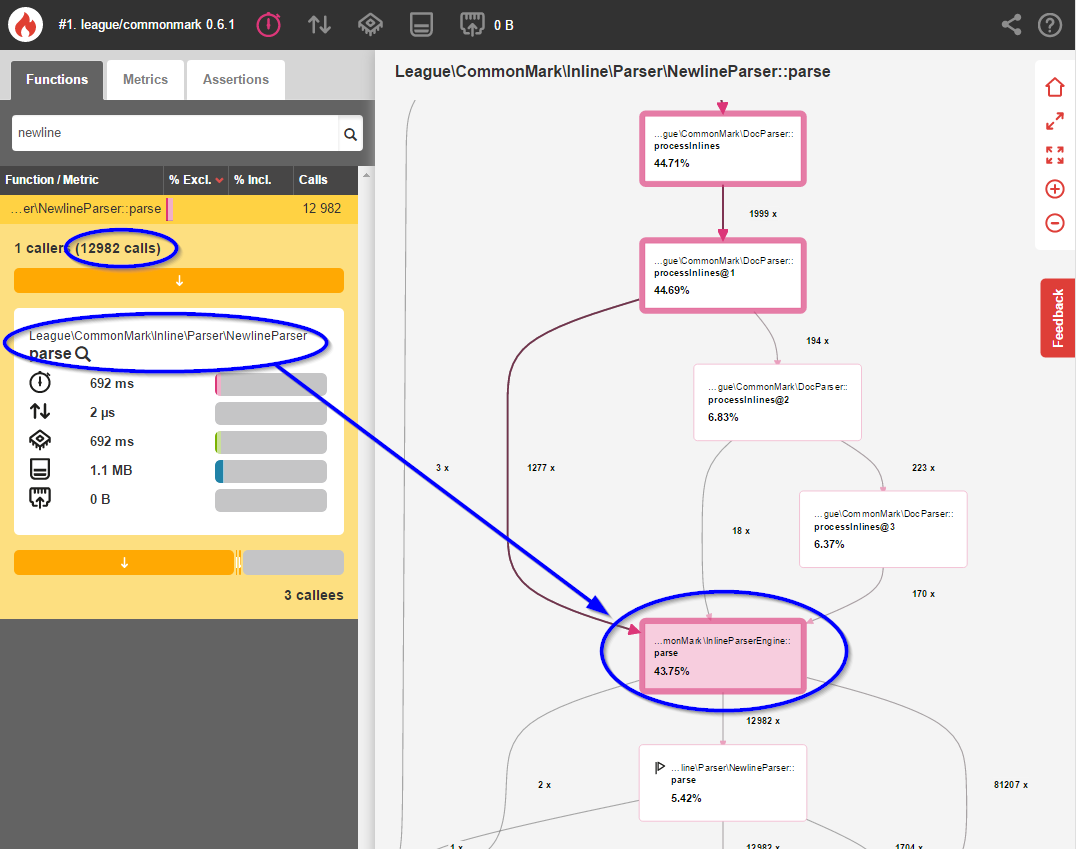
I was shocked to see that 43.75% of the ENTIRE parsing process was figuring out whether 12,982 spaces and newlines should be converted to <br> elements. This was totally unacceptable, so I set out to optimize this.
令我震惊的是,整个解析过程的43.75%正在计算是否应将12,982个空格和换行符转换为<br>元素。 这是完全不可接受的,因此我着手对其进行优化。
Remember that the spec dictates that the sequence must end with a newline character (\n). So, instead of stopping at every space character, let’s just stop at newlines and see if the previous characters were spaces:
请记住,规范规定序列必须以换行符( \n )结尾。 因此,我们不要在每个空格字符处停下来,而只是在换行符处停下来看看前面的字符是否为空格:
class NewlineParser extends AbstractInlineParser {
public function getCharacters() {
return array("\n");
}
public function parse(ContextInterface $context, InlineParserContext $inlineContext) {
$inlineContext->getCursor()->advance();
// Check previous text for trailing spaces
$spaces = 0;
$lastInline = $inlineContext->getInlines()->last();
if ($lastInline && $lastInline instanceof Text) {
// Count the number of spaces by using some `trim` logic
$trimmed = rtrim($lastInline->getContent(), ' ');
$spaces = strlen($lastInline->getContent()) - strlen($trimmed);
}
if ($spaces >= 2 ) {
$inlineContext->getInlines()->add(new Newline(Newline::HARDBREAK));
} else {
$inlineContext->getInlines()->add(new Newline(Newline::SOFTBREAK));
}
return true;
}
}With that modification in place, I re-profiled the application and saw the following results:
完成修改后,我重新分析了该应用程序,并看到了以下结果:
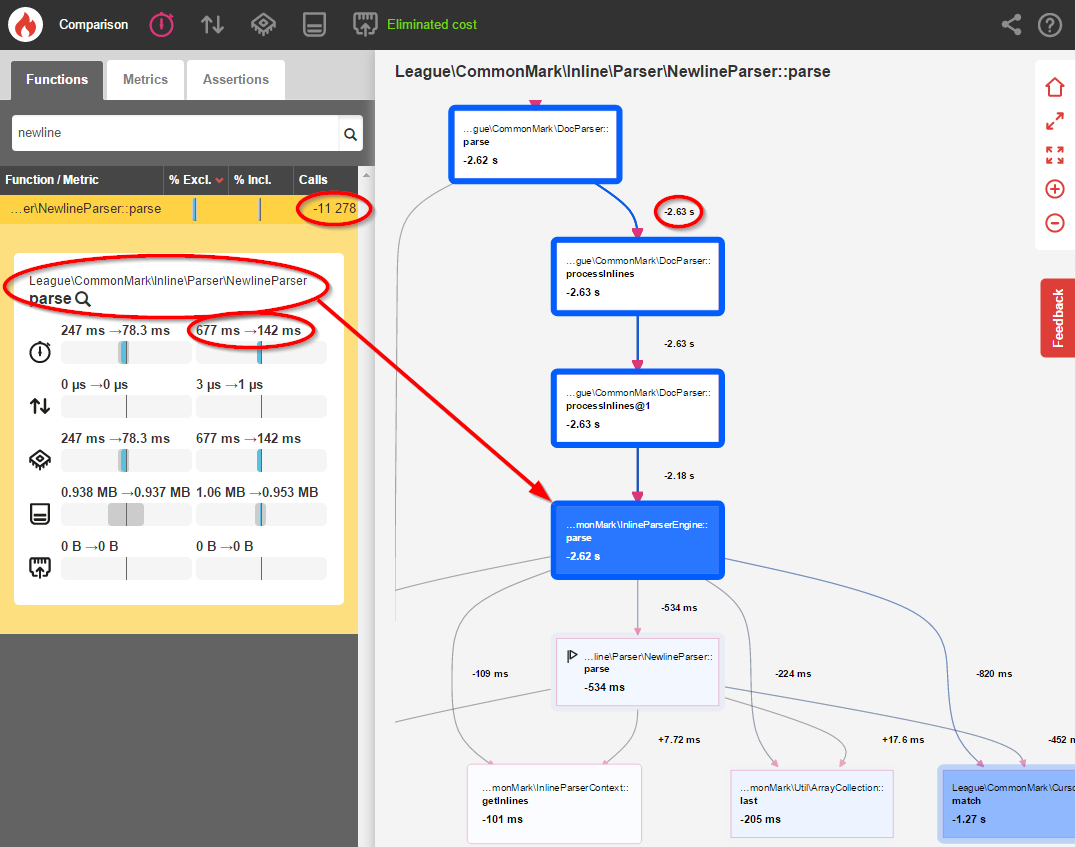
NewlineParser::parse()is now only called 1,704 times instead of 12,982 times (an 87% decrease)NewlineParser::parse()现在仅被调用1,704次,而不是12,982次(减少了87%)- General inline parsing time decreased by 61% 常规内联解析时间减少了61%
Overall parsing speed improved by 23%
整体解析速度提高了23%
摘要 (Summary)
Once both optimizations were implemented, I re-ran the league/commonmark benchmark tool to determine the real-world performance implications:
两种优化均实现后,我重新运行了联盟/通用标记基准工具来确定对实际性能的影响:
-
Before:
之前:
- 59ms
- 59毫秒 After: 后:
- 28ms
- 28毫秒
That’s a whopping 52.5% performance boost from making two simple changes!
进行两个简单的更改 ,可将性能提高多达52.5% !
Being able to see the performance cost (in both execution time and number of function calls) was critical to identifying these performance hogs. I highly doubt these issues would’ve been noticed without having access to this performance data.
能够看到性能成本(在执行时间和函数调用数量上)对于确定这些性能消耗至关重要。 我高度怀疑如果不访问此性能数据,是否会注意到这些问题。
Profiling is absolutely critical to ensuring that your code runs fast and efficiently. If you don’t already have a profiling tool then I highly recommend you check them out. My personal favorite happens to be Blackfire (which is “freemium”), but there other profiling tools out there too. All of them work slightly differently, so look around and find the one that works best for you and your team.
分析对于确保代码快速有效地运行至关重要。 如果您还没有分析工具,则强烈建议您将它们检出。 我个人最喜欢的是Blackfire(“免费”),但那里也有其他分析工具 。 它们的工作方式略有不同,因此请环顾四周,寻找最适合您和您的团队的产品。
An unedited version of this post was originally published on Colin’s blog. It was republished here with the author’s permission.
这篇文章的未经编辑版本最初发布在Colin的博客上 。 经作者许可,它已在此处重新发布。
翻译自: https://www.sitepoint.com/optimizing-league-commonmark-blackfire-io/















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









