





介绍 (Introduction)
It’s time to talk about exceptions or, rather, exceptional situations. Before we start, let’s look at the definition. What is an exceptional situation?
现在是时候讨论例外或例外情况了。 在开始之前,让我们看一下定义。 有什么例外情况?
This is a situation that makes the execution of current or subsequent code incorrect. I mean different from how it was designed or intended. Such a situation compromises the integrity of an application or its part, e.g. an object. It brings the application into an extraordinary or exceptional state.
这种情况会使当前或后续代码的执行不正确。 我的意思是与设计或意图不同。 这种情况损害了应用程序或其部分(例如对象)的完整性。 它将应用程序置于异常或异常状态。
But why do we need to define this terminology? Because it will keep us in some boundaries. If we don’t follow the terminology, we can get too far from a designed concept which may result in many ambiguous situations. Let’s see some practical examples:
但是为什么我们需要定义这个术语呢? 因为它将使我们保持一定的界限。 如果我们不遵循术语,那么我们可能会偏离设计概念,而设计概念可能会导致很多歧义。 让我们看一些实际的例子:
struct Number
{
public static Number Parse(string source)
{
// ...
if(!parsed)
{
throw new ParsingException();
}
// ...
}
public static bool TryParse(string source, out Number result)
{
// ..
return parsed;
}
}This example seems a little strange, and it is for a reason. I made this code slightly artificial to show the importance of problems appearing in it. First, let’s look at the Parse method. Why should it throw an exception?
这个例子似乎有些奇怪,这是有原因的。 我对代码进行了人工处理,以显示其中出现问题的重要性。 首先,让我们看一下Parse方法。 为什么要抛出异常?
- Because the parameter it accepts is a string, but its output is a number, which is a value type. This number can’t indicate validity of calculations: it just exists. In other words, the method has no means in its interface to communicate a potential problem. 因为它接受的参数是字符串,但其输出是数字,这是一种值类型。 该数字不能表示计算的有效性:它只是存在。 换句话说,该方法在其界面中没有传达潜在问题的手段。
- On the other hand, the method expects a correct string that contains some number and no redundant characters. If it doesn’t contain, there is a problem in prerequisites to the method: the code which calls our method has passed wrong data. 另一方面,该方法需要包含一些数字且没有多余字符的正确字符串。 如果不包含该方法,则该方法的先决条件就会出现问题:调用我们方法的代码传递了错误的数据。
Thus, the situation when this method gets a string with incorrect data is exceptional because the method can return neither a correct value nor anything. Thus, the only way is to throw an exception.
因此,此方法获取带有错误数据的字符串的情况非常特殊,因为该方法既不能返回正确的值,也不能返回任何值。 因此,唯一的方法是引发异常。
The second variant of the method can signal some problems with input data: the return value here is boolean which indicates successful execution of the method. This method doesn’t need to use exceptions to signal any problems: they are all covered by the false return value.
该方法的第二种变体可以表示输入数据存在一些问题:此处的返回值为boolean ,表示该方法已成功执行。 该方法不需要使用异常来表示任何问题:它们都由false返回值覆盖。
总览 (Overview)
Exceptions handling might look as easy as ABC: we just need to place try-catch blocks and wait for corresponding events. However, this simplicity became possible due to the tremendous work of CLR and CoreCLR teams that unified all the errors that come from all directions and sources into the CLR. To understand what we are going to talk about next, let’s look at a diagram:
异常处理看起来就像ABC一样容易:我们只需要放置try-catch块并等待相应的事件。 但是,由于CLR和CoreCLR团队的巨大工作将来自各个方向和来源的所有错误统一到CLR中,因此这种简化变得可能。 为了理解接下来要讨论的内容,让我们看一下图:
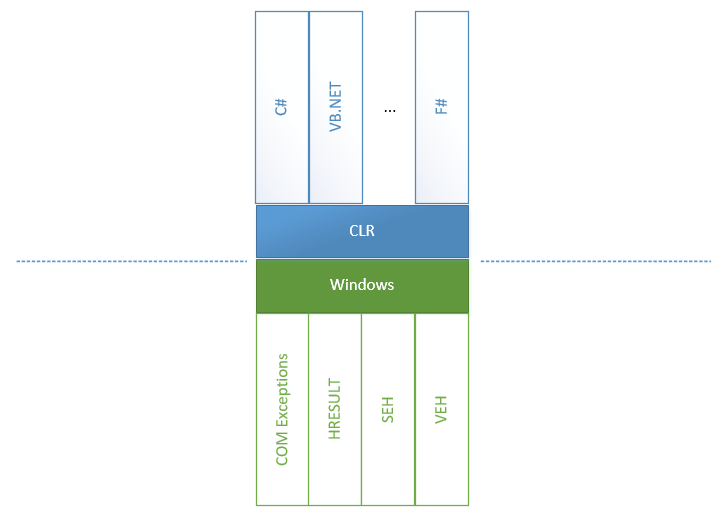
We can see that inside big .NET Framework there are two worlds: everything that belongs to CLR and everything that doesn’t, including all possible errors appearing in Windows and other parts of the unsafe world.
我们可以看到,在大型.NET Framework中,有两个世界:属于CLR的所有事物和不属于CLR的所有事物,包括Windows和不安全世界其他部分中出现的所有可能的错误。
Structured Exception Handling (SEH) is a standard way Windows handles exceptions. When
unsafemethods are called and exceptions are thrown, there is the unsafe <-> CLR conversion of exceptions in both directions: from unsafe to CLR and backward. This is because CLR can call an unsafe method which can call a CLR method in turn.结构化异常处理(SEH)是Windows处理异常的一种标准方式。 当调用
unsafe方法并引发异常时,在两个方向上都有不安全的<-> CLR异常转换:从不安全到CLR以及向后。 这是因为CLR可以调用不安全的方法,而该方法又可以依次调用CLR方法。Vectored Exception Handling (VEH) is a root of SEH and allows you to put your handlers in places where exceptions might be thrown. In particular, it used for placing
FirstChanceException.向量异常处理(VEH)是SEH的基础,它允许您将处理程序放置在可能引发异常的地方。 特别是,它用于放置
FirstChanceException。- COM+ exceptions appear when the source of a problem is a COM component. In this case, a layer between COM and a .NET method must convert a COM error into a .NET exception. 当问题的根源是COM组件时,将出现COM +异常。 在这种情况下,COM和.NET方法之间的一层必须将COM错误转换为.NET异常。
- And, of course, wrappers for HRESULT. They are introduced to convert a WinAPI model (an error code is contained in a return value, while return values are obtained using method parameters) into a model of exceptions because it is an exception that is standard for .NET. 当然,还有HRESULT的包装器。 引入它们是为了将WinAPI模型(返回值中包含错误代码,而使用方法参数获取返回值)转换为异常模型,因为这是.NET的标准异常。
On the other hand, there are languages above CLI each of which more or less have functions for handling exceptions. For example, recently VB.NET or F# had a richer exception handling functionality expressed in a number of filters that didn’t exist in C#.
另一方面,CLI之上有一些语言,每种语言或多或少都具有处理异常的功能。 例如,最近VB.NET或F#具有更丰富的异常处理功能,这些功能用C#中不存在的许多过滤器表示。
返回码与异常 (Return codes vs. exception)
Separately, I should mention a model of handling application errors using return codes. The idea of simply returning an error is plain and clear. Moreover, if we treat exceptions as a goto operator, the use of return codes becomes more reasonable: in this case, the user of a method sees the possibility of errors and can understand which errors may occur. However, let’s not guess what is better and for what, but discuss the problem of choice using a well reasoned theory.
另外,我应该提到一个使用返回码处理应用程序错误的模型。 简单地返回错误的想法是显而易见的。 此外,如果我们将异常视为goto运算符,则返回码的使用将变得更加合理:在这种情况下,方法的用户将看到错误的可能性,并可以了解可能发生的错误。 但是,我们不要猜测什么是更好的,什么是什么,而要使用合理的理论讨论选择的问题。
Let’s suppose that all methods have interfaces to deal with errors. Then all methods would look like:
假设所有方法都有接口来处理错误。 然后所有方法看起来像:
public bool TryParseInteger(string source, out int result);
public DialogBoxResult OpenDialogBox(...);
public WebServiceResult IWebService.GetClientsList(...);
public class DialogBoxResult : ResultBase { ... }
public class WebServiceResult : ResultBase { ... }And their use would look like:
它们的用法如下所示:
public ShowClientsResult ShowClients(string group)
{
if(!TryParseInteger(group, out var clientsGroupId))
return new ShowClientsResult { Reason = ShowClientsResult.Reason.ParsingFailed };
var webResult = _service.GetClientsList(clientsGroupId);
if(!webResult.Successful)
{
return new ShowClientsResult { Reason = ShowClientsResult.Reason.ServiceFailed, WebServiceResult = webResult };
}
var dialogResult = _dialogsService.OpenDialogBox(webResult.Result);
if(!dialogResult.Successful)
{
return new ShowClientsResult { Reason = ShowClientsResult.Reason.DialogOpeningFailed, DialogServiceResult = dialogResult };
}
return ShowClientsResult.Success();
}You may think this code is overloaded with error handling. However, I would like you to reconsider your position: everything here is an emulation of a mechanism that throws and handles exceptions.
您可能会认为此代码因错误处理而超载。 但是,我希望您重新考虑自己的立场:这里的所有内容都是对引发和处理异常的机制的仿真。
How can a method report a problem? It can do it by using an interface for reporting errors. For example, in TryParseInteger method such interface is represented by a return value: if everything is OK, the method will return true. If it’s not OK, it will return false. However, there is a disadvantage here: the real value is returned via out int result parameter. The disadvantage is that on the one hand the return value is logically and by perception has more "return value” essence than that of out parameter. On the other hand, we don’t always care about errors. Indeed, if a string intended for parsing comes from a service that generated this string, we don’t need to check it for errors: the string will always be correct and good for parsing. However, suppose we take another implementation of the method:
方法如何报告问题? 它可以通过使用用于报告错误的界面来做到这一点。 例如,在TryParseInteger方法中,此类接口由返回值表示:如果一切正常,该方法将返回true 。 如果不正常,它将返回false 。 但是,这里有一个缺点:实际值是通过out int result参数返回的。 缺点是:一方面,返回值在逻辑上是合理的,并且根据感知,它比“ out参数具有更多的“返回值”本质;另一方面,我们并不总是关心错误。解析来自生成该字符串的服务,我们不需要检查它是否有错误:该字符串将始终正确且对解析有用,但是,假设我们采用了该方法的另一种实现:
public int ParseInt(string source);Then, there is a question: if a string does have errors, what should the method do? Should it return zero? This won’t be correct: there is no zero in the string. In this case, we have a conflict of interests: the first variant has too much code, while the second variant has no means to report errors. However, it’s actually easy to decide when to use return codes and when to use exceptions.
然后,有一个问题:如果字符串确实有错误,该方法应该做什么? 它应该返回零吗? 这是不正确的:字符串中没有零。 在这种情况下,我们存在利益冲突:第一个变量的代码太多,而第二个变量没有报告错误的方法。 但是,实际上很容易决定何时使用返回码以及何时使用异常。
If getting an error is a norm, choose a return code. For example, it is normal when a text parsing algorithm encounters errors in a text, but if another algorithm that works with a parsed string gets an error from a parser, it can be critical or, in other words, exceptional.
如果遇到错误是正常现象,请选择返回码。 例如,当文本解析算法在文本中遇到错误时,这是正常现象,但是,如果使用解析字符串的另一种算法从解析器中获取错误,则这可能很关键,或者换句话说,是异常情况。
最后尝试-捕获 (Try-Catch-Finally in brief)
A try block covers a section where a programmer expects to get a critical situation which is treated as a norm by external code. In other words, if some code considers its internal state inconsistent based on some rules and throws an exception, an external system, which has a broader view of the same situation, can catch this exception using a catch block and normalize the execution of application code. Thus, you legalize exceptions in this section of code by catching them. I think it is an important idea that justifies the ban on catching all try-catch(Exception ex){ ...} exceptions just in case.
一个try块覆盖了程序员期望遇到的一种危急情况,该情况被外部代码视为规范。 换句话说,如果某些代码根据某些规则认为其内部状态不一致并引发异常,则对相同情况有更广阔视野的外部系统可以使用catch块捕获此异常并规范应用程序代码的执行。 。 因此, 您可以通过捕获异常使代码在此部分中合法化 。 我认为,这是一个重要的想法,可以禁止所有try-catch(Exception ex){ ...}例外,以防万一 。
It doesn’t mean that catching exceptions contradicts some ideology. I say that you should catch only the errors that you expect from a particular section of code. For example, you can’t expect all types of exceptions inherited from ArgumentException or you can’t get NullReferenceException, because often it means that a problem is rather in your code than in a called one. But it’s appropriate to expect that you won’t be able to open an intended file. Even if you 200% sure you will be able, don’t forget to check.
这并不意味着捕捉例外与某些意识形态相矛盾。 我说,您应该只捕获特定代码段中预期的错误。 例如,你不能指望所有类型的继承异常ArgumentException ,或者你不能得到NullReferenceException ,因为往往意味着一个问题,而在你的代码不是在叫一个。 但是可以期望您将无法打开预期的文件。 即使您200%确信您将能够使用,也不要忘记进行检查。
The finally block is also well known. It is suitable for all cases covered by try-catch blocks. Except for several rare special situations, this block will always work. Why was such a guarantee of performance introduced? To clean up those resources and groups of objects which were allocated or captured in try block and which this block has responsibility for.
finally一块也是众所周知的。 它适用于try-catch块涵盖的所有情况。 除少数几种特殊情况外,此块将始终有效。 为什么要引入这样的性能保证? 清理那些在try块中分配或捕获并且由该块负责的资源和对象组。
This block is often used without catch block when we don’t care which error broke an algorithm, but we need to clean up all resources allocated for this algorithm. Let’s look at a simple example: a file copying algorithm needs two open files and a memory range for a cash buffer. Imagine that we allocated memory and opened one file, but couldn’t open another one. To wrap everything in one "transaction” atomically we put all three operations in a single try block (as a variant of implementation) with resources cleaned in finally. It may seem like a simplified example but the most important is to show the essence.
当我们不在乎哪个错误导致算法catch时,通常会在没有catch块的情况下使用此块,但是我们需要清理为此算法分配的所有资源。 让我们看一个简单的示例:文件复制算法需要两个打开的文件和一个现金缓冲区的存储范围。 想象一下,我们分配了内存并打开了一个文件,但是无法打开另一个文件。 为了将所有操作原子地包装在一个“事务”中,我们将所有三个操作放在一个try块中(作为实现的变体),并finally清除了资源,这似乎是一个简化的示例,但最重要的是展示其本质。
What C# actually lacks is a fault block which is activated whenever an error occurs. It’s like finally on steroids. If we had this, we could, for example, create a single entry point to log exceptional situations:
C#实际上缺少的是一个fault块,每当发生错误时,该fault块就会被激活。 就像finally在类固醇上一样。 如果有了这个,例如,我们可以创建一个入口点来记录异常情况:
try {
//...
} fault exception
{
_logger.Warn(exception);
}Another thing I should touch in this introduction is exception filters. It is not a new feature on the .NET platform but C# developers may be new to it: exception filtering appeared only in v. 6.0. Filters should normalize a situation when there is a single type of exception that combines several types of errors. It should help us when we want to deal with a particular scenario but have to catch the whole group of errors first and filter them later. Of course, I mean the code of the following type:
在本简介中,我应该谈到的另一件事是异常过滤器。 它不是.NET平台上的新功能,但C#开发人员可能是新手:异常筛选仅在6.0版中出现。 当单一类型的异常结合了多种类型的错误时,过滤器应将情况规范化。 当我们要处理特定的情况,但必须先捕获整个错误组,然后再过滤它们时,它应该对我们有帮助。 当然,我的意思是以下类型的代码:
try {
//...
}
catch (ParserException exception)
{
switch(exception.ErrorCode)
{
case ErrorCode.MissingModifier:
// ...
break;
case ErrorCode.MissingBracket:
// ...
break;
default:
throw;
}
}Well, we can now rewrite this code properly:
好了,我们现在可以正确地重写以下代码:
try {
//...
}
catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingModifier)
{
// ...
}
catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingBracket)
{
// ...
}The improvement here is not in the lack of switch construct. I believe this new construct is better in several things:
这里的改进不是缺少switch构造。 我相信这种新结构在以下几方面会更好:
using
whenfor filtering we catch exactly what we want and it’s right in terms of ideology;使用
when进行过滤,我们可以准确地捕获我们想要的东西,并且在意识形态方面是正确的;the code becomes more readable in this new form. Looking through code our brain can identify blocks for handling errors more easily as it initially searches for
catchand notswitch-case;代码以这种新形式变得更具可读性。 通过查看代码,我们的大脑在最初搜索
catch而不是switch-case可以更轻松地识别用于处理错误的块;the last but not least: a preliminary comparison is BEFORE entering the catch block. It means that if we make wrong guesses about potential situations, this construct will work faster than
switchin the case of throwing an exception again.最后但并非最不重要的一点:在进入catch块之前进行初步比较。 这意味着,如果我们对潜在情况做出了错误的猜测,那么在再次引发异常的情况下,此构造将比
switch更快地工作。
Many sources say that the peculiar feature of this code is that filtering happens before stack unrolling. You can see this in situations when there are no other calls except usual between the place where an exception is thrown and the place where filtering check occurs.
许多消息人士说,此代码的特殊功能是在堆栈展开之前进行过滤。 在抛出异常的地方和进行过滤检查的地方之间没有其他调用(通常除外)的情况下,您会看到这种情况。
static void Main()
{
try
{
Foo();
}
catch (Exception ex) when (Check(ex))
{
;
}
}
static void Foo()
{
Boo();
}
static void Boo()
{
throw new Exception("1");
}
static bool Check(Exception ex)
{
return ex.Message == "1";
}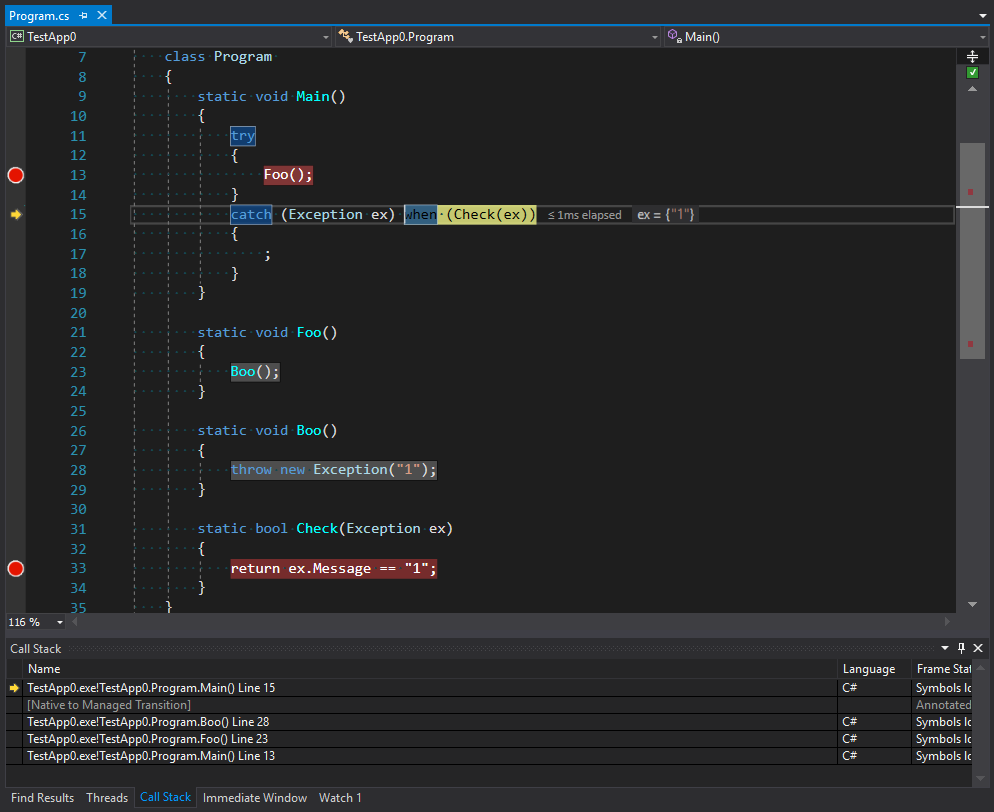
You can see from the image that the stack trace contains not only the first call of Main as the point to catch an exception, but the whole stack before the point of throwing an exception plus the second entering into Main via unmanaged code. We can suppose that this code is exactly the code for throwing exceptions that is in the stage of filtering and choosing a final handler. However, not all calls can be handled without stack unrolling. I believe that excessive uniformity of the platform generates too much confidence in it. For example, when one domain calls a method from another domain it is absolutely transparent in terms of code. However, the way methods calls work is an absolutely different story. We are going to talk about them in the next part.
从图中可以看到,堆栈跟踪不仅包含Main的第一个调用作为捕获异常的点,而且还包含抛出异常之前的整个堆栈以及通过非托管代码进入Main的第二个堆栈。 我们可以假设该代码正是在过滤和选择最终处理程序阶段抛出异常的代码。 但是,如果不展开堆栈 , 并非所有调用都可以处理 。 我相信平台的过度统一会对它产生太大的信心。 例如,当一个域从另一域调用方法时,就代码而言绝对是透明的。 但是,方法调用的工作方式完全不同。 我们将在下一部分中讨论它们。
序列化 (Serialization)
Let’s start by looking at the results of running the following code (I added the transfer of a call across the boundary between two application domains).
让我们从运行以下代码的结果开始(我添加了跨越两个应用程序域之间的边界的调用转移)。
class Program
{
static void Main()
{
try
{
ProxyRunner.Go();
}
catch (Exception ex) when (Check(ex))
{
;
}
}
static bool Check(Exception ex)
{
var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe
return ex.Message == "1";
}
public class ProxyRunner : MarshalByRefObject
{
private void MethodInsideAppDomain()
{
throw new Exception("1");
}
public static void Go()
{
var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup
{
ApplicationBase = AppDomain.CurrentDomain.BaseDirectory
});
var proxy = (ProxyRunner) dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName);
proxy.MethodInsideAppDomain();
}
}
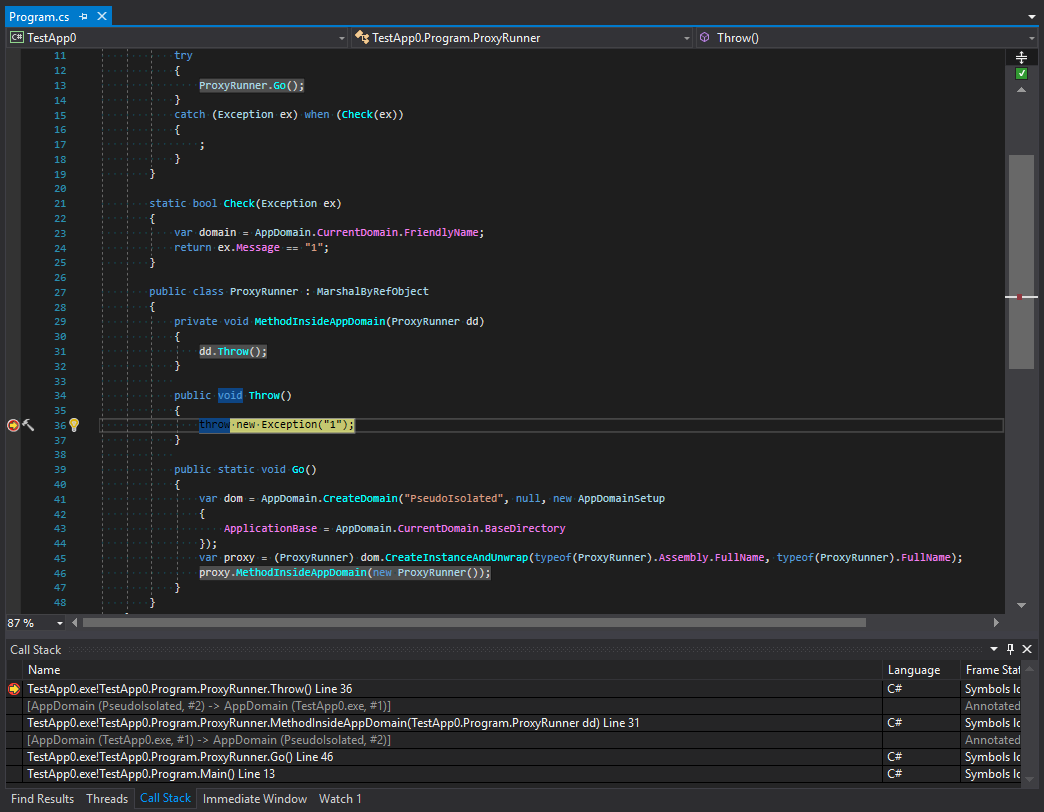
}We can see that stack unrolling happens before we get to filtering. Let’s look at screenshots. The first is taken before the generation of an exception:
我们可以看到堆栈展开是在进行过滤之前发生的。 让我们看一下屏幕截图。 第一个是在生成异常之前进行的:
The second one is after it:
第二个是:
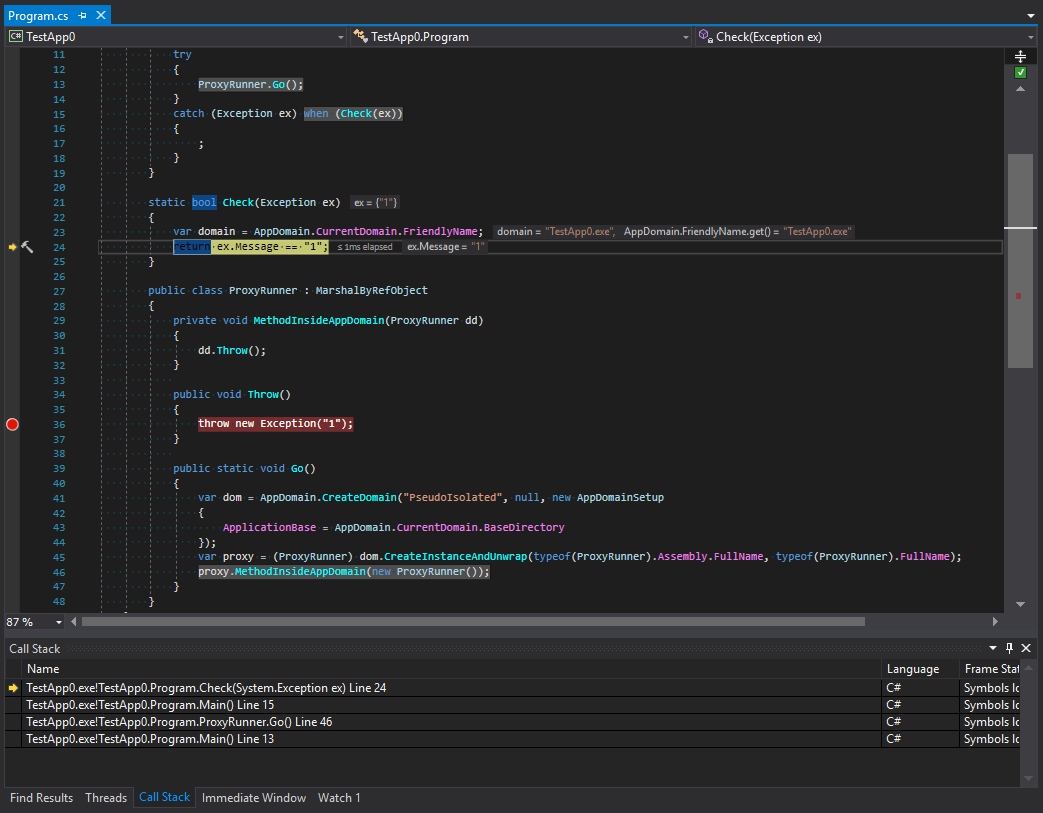
Let’s study call tracing before and after exceptions are filtered. What happens here? We can see that platform developers made something that at first glance looks like the protection of a subdomain. The tracing is cut after the last method in the call chain and then there is the transfer to another domain. But I think this looks strange. To understand why this happens let’s remember the main rule for types that organize the interaction between domains. These types should inherit MarshalByRefObject and be serializable. However, despite the strictness of C# exception types can be of any nature. What does it mean? This means that situations may occur when an exception inside a subdomain can be caught in a parent domain. Also, if a data object that can get into an exceptional situation has some methods that are dangerous in terms of security they can be called in a parent domain. To avoid this, the exception is first serialized and then it crosses the boundary between application domains and appears again with a new stack. Let’s check this theory:
让我们研究过滤异常之前和之后的调用跟踪。 这里会发生什么? 我们可以看到,平台开发人员所做的事情乍一看就像是对子域的保护。 跟踪是在调用链中的最后一个方法之后进行的,然后转移到另一个域。 但是我认为这看起来很奇怪。 要了解为什么会发生这种情况,让我们记住组织域之间交互的类型的主要规则。 这些类型应该继承MarshalByRefObject并且可以序列化。 但是,尽管C#严格,但异常类型可以是任何性质。 这是什么意思? 这意味着当子域中的异常可以在父域中捕获时,可能会发生这种情况。 同样,如果可能陷入异常情况的数据对象具有某些在安全性方面很危险的方法,则可以在父域中调用它们。 为避免这种情况,首先对异常进行序列化,然后它越过应用程序域之间的边界,并再次与新堆栈一起出现。 让我们检查一下这个理论:
[StructLayout(LayoutKind.Explicit)]
class Cast
{
[FieldOffset(0)]
public Exception Exception;
[FieldOffset(0)]
public object obj;
}
static void Main()
{
try
{
ProxyRunner.Go();
Console.ReadKey();
}
catch (RuntimeWrappedException ex) when (ex.WrappedException is Program)
{
;
}
}
static bool Check(Exception ex)
{
var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe
return ex.Message == "1";
}
public class ProxyRunner : MarshalByRefObject
{
private void MethodInsideAppDomain()
{
var x = new Cast {obj = new Program()};
throw x.Exception;
}
public static void Go()
{
var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup
{
ApplicationBase = AppDomain.CurrentDomain.BaseDirectory
});
var proxy = (ProxyRunner)dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName);
proxy.MethodInsideAppDomain();
}
}For C# code could throw an exception of any type (I don’t want to torture you with MSIL) I performed a trick in this example casting a type to a noncomparable one, so we could throw an exception of any type, but the translator would think that we use Exception type. We create an instance of the Program type, which is not serializable for sure, and throw an exception using this type as workload. The good news is that you get a wrapper for non-Exception exceptions of RuntimeWrappedException which will store an instance of our Program type object inside and we will be able to catch this exception. However, there is bad news that supports our idea: calling proxy.MethodInsideAppDomain(); will generate SerializationException:
因为C#代码可能引发任何类型的异常(我不想用MSIL折磨您),所以在本示例中我做了一个技巧,将类型转换为不可比较的类型,因此我们可以引发任何类型的异常,但是翻译器可以会认为我们使用Exception类型。 我们创建了一个肯定不能序列化的Program类型的实例,并使用此类型作为工作负载抛出异常。 好消息是,您获得了RuntimeWrappedException非Exception异常的包装器,该包装器将在其中存储我们的Program类型对象的实例,并且我们将能够捕获此异常。 但是,有一个坏消息支持我们的想法:调用proxy.MethodInsideAppDomain(); 将生成SerializationException :
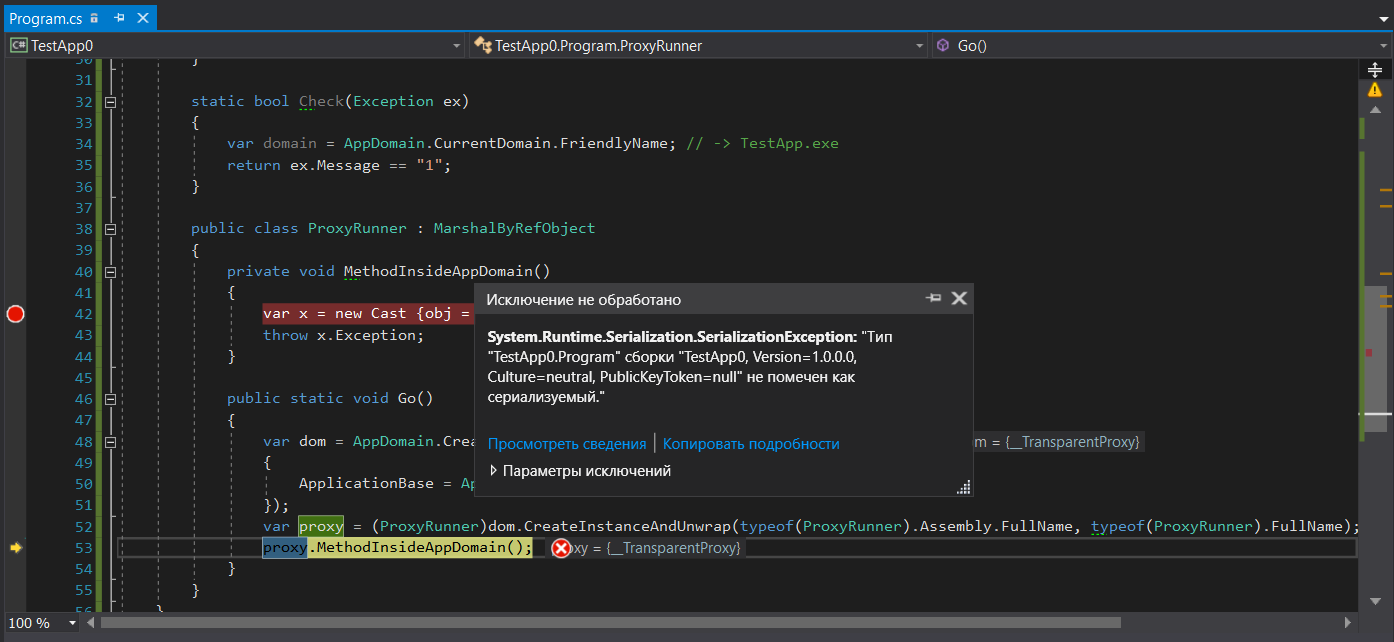
Thus, you can’t transfer such an exception between domains as it is not possible to serialize it. This, in turn, means that using exception filters for wrapping methods calls in other domains will anyway lead to stack unrolling despite that the serialization seems to be unnecessary with FullTrust settings of a subdomain.
因此,您无法在域之间传输此类异常,因为无法对其进行序列化。 反过来,这意味着尽管使用子域的FullTrust设置似乎不需要序列化,但在其他域中将异常过滤器用于包装方法调用仍将导致堆栈展开。
Bootype and get it in another domain the casting ofBoo类型的实例并将其放在另一个域中,则(Boo)boowon’t work. In this case, serialization and deserialization will solve the problem as the object will exist in two domains simultaneously. It will exist with all its data where it was created and it will exist in the domain of usage as a proxy object, ensuring that methods of an original object are called.(Boo)boo将不起作用。 在这种情况下,序列化和反序列化将解决该问题,因为对象将同时存在于两个域中。 它将与创建时的所有数据一起存在,并且将在使用范围中作为代理对象存在,从而确保调用原始对象的方法。
By transferring a serialized object between domains you get a full copy of the object from one domain in another one while keeping some delimitation in memory. However, this delimitation is fictional. It is used only for those types that are not in Shared AppDomain. Thus, if you throw something non-serializable as an exception, but from Shared AppDomain, you won’t get an error of serialization (we can try throwing Action instead of Program). However, stack unrolling will anyway occur in this case: as both variants should work in a standard way. So that nobody will be confused.
通过在域之间传输序列化的对象,您可以从一个域中的另一个域中获得对象的完整副本,同时在内存中保留一定的界限。 但是,这种划界是虚构的。 它仅用于Shared AppDomain中没有的那些类型。 因此,如果您抛出一些不可序列化的异常,但是从Shared AppDomain抛出,则不会出现序列化错误(我们可以尝试抛出Action而不是Program )。 但是,在这种情况下,无论如何都会发生堆栈展开:因为这两种变体都应该以标准方式工作。 这样没人会感到困惑。
professional translators. You can help us with translation from Russian or English into any other language, primarily into Chinese or German. 专业翻译员共同译自俄语。 您可以帮助我们将俄语或英语翻译成任何其他语言,主要是中文或德语。This chapter was translated from Russian jointly by author and by 本章由作者和
Also, if you want thank us, the best way you can do that is to give us a star on github or to fork repository
.另外,如果您想感谢我们,最好的方法是在github上给我们加星号或分支存储库 github / sidristij / dotnetbook 。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









