





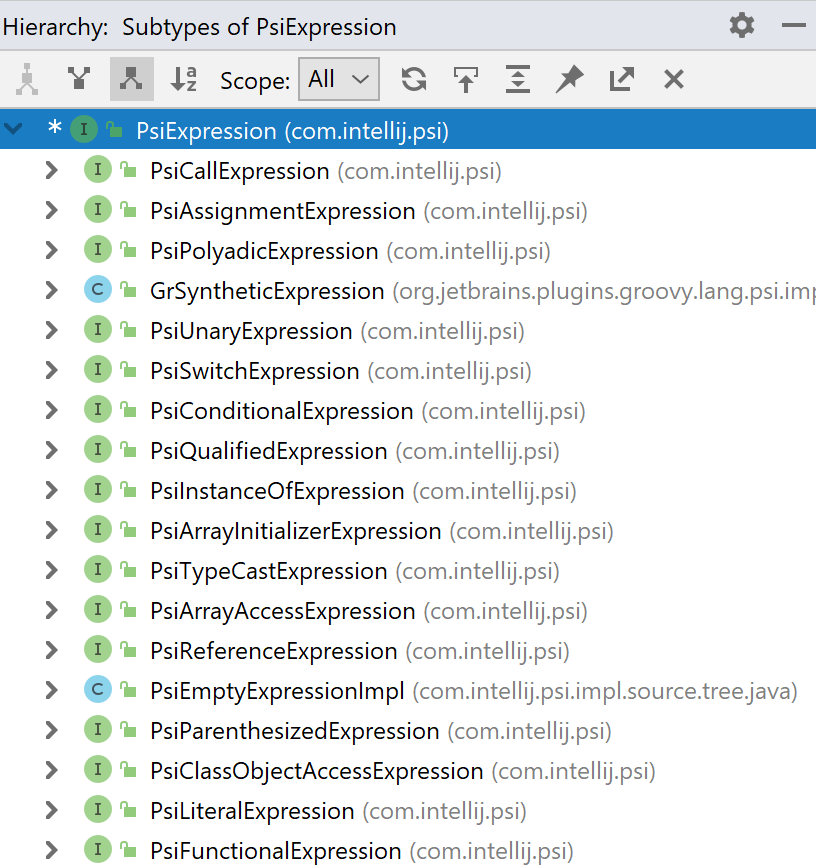
Code search and navigation are important features of any IDE. In Java, one of the commonly used search options is searching for all implementations of an interface. This feature is often called Type Hierarchy, and it looks just like the image on the right.
代码搜索和导航是任何IDE的重要功能。 在Java中,常用的搜索选项之一是搜索接口的所有实现。 此功能通常称为“类型层次结构”,它看起来就像右边的图像一样。
It's inefficient to iterate over all project classes when this feature is invoked. One option is to save the complete class hierarchy in the index during compilation since the compiler builds it anyway. We do this when the compilation is run by the IDE and not delegated, for example, to Gradle. But this works only if nothing has been changed in the module after the compilation. In general, the source code is the most up-to-date information provider, and indexes are based on the source code.
调用此功能时,遍历所有项目类的效率很低。 一种选择是在编译期间将完整的类层次结构保存在索引中,因为无论如何编译器都会构建它。 当编译是由IDE运行而不是委托给Gradle时,我们会执行此操作。 但这仅在编译后模块中未进行任何更改的情况下有效。 通常,源代码是最新的信息提供者,而索引基于源代码。
Finding immediate children is a simple task if we are not dealing with a functional interface. When searching for implementations of the Foo interface, we need to find all the classes that have implements Foo and interfaces that have extends Foo, as well as new Foo(...) {...} anonymous classes. To do this, it is enough to build a syntax tree of each project file in advance, find the corresponding constructs, and add them to an index. There is, however, an intricacy here: you might be looking for the com.example.goodcompany.Foo interface, while org.example.evilcompany.Foo is actually used. Can we put the full name of the parent interface into the index in advance? It can be tricky. For example, the file where the interface is used may look like this:
如果我们不处理功能接口,那么找到直子是一个简单的任务。 在搜索Foo接口的实现时,我们需要找到所有implements Foo的类和extends Foo接口,以及new Foo(...) {...}匿名类。 为此,预先构建每个项目文件的语法树,找到相应的构造,然后将它们添加到索引中就足够了。 但是,这里有一个复杂之处:您可能正在寻找com.example.goodcompany.Foo接口,而实际上是在使用org.example.evilcompany.Foo 。 我们可以预先将父接口的全名放入索引中吗? 这可能很棘手。 例如,使用该接口的文件可能如下所示:
// MyFoo.java
import org.example.foo.*;
import org.example.bar.*;
import org.example.evilcompany.*;
class MyFoo implements Foo {...}By looking at the file alone, it's impossible to tell what the actual fully qualified name of Foo is. We'll have to look into the content of several packages. And each package can be defined in several places in the project (for example, in several JAR files). If we perform proper symbol resolution when analyzing this file, indexing will take a lot of time. But the main problem is that the index built on MyFoo.java will depend on other files as well. We can move the declaration of the Foo interface, for example, from the org.example.foo package to the org.example.bar package, without changing anything in the MyFoo.java file, but the fully qualified name of Foo will change.
仅通过查看文件,就无法确定Foo的实际完全限定名称是什么。 我们将不得不研究几个软件包的内容。 每个包都可以在项目中的多个位置定义(例如,在几个JAR文件中)。 如果我们在分析此文件时执行正确的符号解析,则索引将花费大量时间。 但是主要的问题是,基于MyFoo.java构建的索引MyFoo.java将依赖于其他文件。 例如,我们可以将Foo接口的声明从org.example.foo包移动到org.example.bar包,而无需更改MyFoo.java文件中的任何内容,但是Foo的完全限定名称将会更改。
In IntelliJ IDEA, indexes depend only on the content of a single file. On the one hand, it is very convenient: the index associated with a specific file becomes invalid when the file is changed. On the other hand, it imposes major restrictions on what can be put into the index. For example, it does not allow the fully qualified names of parent classes to be saved reliably in the index. But, in general, it's not that bad. When requesting a type hierarchy, we can find everything that matches our request by a short name, and then perform the proper symbol resolution for these files and determine whether that's what we are looking for. In most cases, there won't be too many redundant symbols and the check won't take long.
在IntelliJ IDEA中,索引仅取决于单个文件的内容。 一方面,这非常方便:更改文件时,与特定文件关联的索引变为无效。 另一方面,它对可放入索引的内容施加了主要限制。 例如,它不允许将父类的完全限定名称可靠地保存在索引中。 但是,总的来说,还算不错。 请求类型层次结构时,我们可以通过短名称找到与请求相匹配的所有内容,然后对这些文件执行正确的符号解析,并确定这是否是我们要查找的内容。 在大多数情况下,冗余符号不会太多,检查也不会花费很长时间。
Things change, however, when the class whose children we are looking for is a functional interface. Then, in addition to the explicit and anonymous subclasses, there'll be lambda expressions and method references. What do we put into the index now, and what is to be evaluated during the search?
但是,当我们要寻找其孩子的班级是一个功能接口时,情况就变了。 然后,除了显式和匿名子类外,还将有lambda表达式和方法引用。 我们现在将什么放入索引中,以及在搜索过程中要评估什么?
Let's assume we have a functional interface:
假设我们有一个功能接口:
@FunctionalInterface
public interface StringConsumer {
void consume(String s);
}The code contains different lambda expressions. For instance:
该代码包含不同的lambda表达式。 例如:
() -> {} // a certain mismatch: no parameters
(a, b) -> a + b // a certain mismatch: two parameters
s -> {
return list.add(s); // a certain mismatch: a value is returned
}
s -> list.add(s); // a potential matchIt means we can quickly filter out lambdas that have an inappropriate number of parameters or a clearly inappropriate return type, for example, void instead of non-void. It is usually impossible to determine the return type more precisely. For instance, in s -> list.add(s) you will have to resolve list and add, and, possibly, run a regular type inference procedure. It takes time and depends on the content of other files.
这意味着我们可以快速筛选出参数数量不合适或返回类型明显不合适的lambda,例如,void而非non-void。 通常不可能更精确地确定返回类型。 例如,在s -> list.add(s)您将必须解析list和add ,并且可能运行常规的类型推断过程。 这需要时间,并取决于其他文件的内容。
We’re lucky if the functional interface takes five arguments. But if it only takes one, the filter will keep a huge number of unnecessary lambdas. It's even worse when it gets to method references. By the way it looks, one cannot tell whether a method reference is suitable or not.
如果函数接口接受五个参数,我们很幸运。 但是,如果只用一个,过滤器将保留大量不必要的lambda。 当涉及到方法引用时,情况甚至更糟。 从外观上看,无法确定方法引用是否合适。
To get things straight, it might be worth looking at what surrounds the lambda. Sometimes, it works. For instance:
为了弄清楚事情,可能值得研究一下lambda周围的东西。 有时,它可以工作。 例如:
// declaration of a local variable or a field of different type
Predicate<String> p = s -> list.add(s);
// a different return type
IntPredicate getPredicate() {
return s -> list.add(s);
}
// assignment to a variable of a different type
SomeType fn;
fn = s -> list.add(s);
// cast to a different type
foo((SomeFunctionalType)(s -> list.add(s)));
// declaration of a different type array
Foo[] myLambdas = {s -> list.add(s), s -> list.remove(s)};In all these cases, the short name of the corresponding functional interface can be determined from the current file and can be put into the index next to the functional expression, be it a lambda or a method reference. Unfortunately, in real-life projects, these cases cover a very small percentage of all lambdas. In most cases, lambdas are used as method arguments:
在所有这些情况下,可以从当前文件中确定相应功能接口的简称,并将其放在功能表达式旁边的索引中,可以是lambda或方法引用。 不幸的是,在现实生活中的项目中,这些情况仅占所有lambda的很小一部分。 在大多数情况下,lambda用作方法参数:
list.stream()
.filter(s -> StringUtil.isNonEmpty(s))
.map(s -> s.trim())
.forEach(s -> list.add(s));Which of the three lambdas can contain StringConsumer? Obviously, none. Here we have a Stream API chain that only features functional interfaces from the standard library, it can't have the custom type.
三个lambda中的哪个可以包含StringConsumer ? 显然没有。 在这里,我们有一个Stream API链,它仅具有标准库中的功能接口,而不能具有自定义类型。
However, the IDE should be able to see through the trick and give us an exact answer. What if list is not exactly java.util.List, and list.stream() returns something different from java.util.stream.Stream? Then we'll have to resolve list, which, as we know, cannot be reliably done based only on the content of the current file. And even if we do, the search should not rely on the implementation of the standard library. What if in this particular project we have replaced java.util.List with a class of our own? The search must take this into account. And, naturally, lambdas are used not only in standard streams: there are many other methods to which they are passed.
但是,IDE应该能够看透窍门并为我们提供确切的答案。 如果list不完全是java.util.List ,并且list.stream()返回的内容与java.util.stream.Stream不同,该怎么办? 然后,我们将不得不解析list ,众所周知,仅根据当前文件的内容就无法可靠地完成list 。 即使我们这样做,搜索也不应依赖于标准库的实现。 如果在这个特定项目中我们用自己的类替换了java.util.List怎么办? 搜索必须考虑到这一点。 而且,自然地,lambda不仅在标准流中使用:它们还传递给许多其他方法。
As a result, we can query the index for a list of all Java files that use lambdas with the required number of parameters and a valid return type (in fact, we only search for four options: void, non-void, boolean, and any). And what's next? Do we need to build a complete PSI tree (a kind of a parse tree with symbol resolution, type inference, and other smart features) for each of these files and perform proper type inference for lambdas? For a big project, it will take ages to get the list of all interface implementations, even if there are only two of them.
结果,我们可以在索引中查询所有使用lambda的Java文件的列表,这些文件具有必需的参数数量和有效的返回类型(实际上,我们仅搜索四个选项:void,non-void,boolean和任何)。 接下来呢? 我们是否需要为每个文件构建完整的PSI树(一种具有符号解析,类型推断和其他智能功能的解析树),并对lambda执行正确的类型推断? 对于大型项目,即使只有两个接口实现列表,也要花费很多时间。
So, we need to take the following steps:
因此,我们需要采取以下步骤:
- Ask index (not costly) 询问索引(不昂贵)
- Build PSI (costly) 建立PSI(代价高昂)
- Infer lambda type (very costly) 推断λ类型(非常昂贵)
For Java 8 and later, type inference is an extremely costly operation. In a complex call chain, there might be many substitutional generic parameters, the values of which have to be determined using the hard-hitting procedure described in Chapter 18 of the specification. For the current file, this can be done in the background, but processing thousands of unopened files this way would be an expensive task.
对于Java 8和更高版本,类型推断是一项非常昂贵的操作。 在复杂的调用链中,可能会有许多替代通用参数,这些参数的值必须使用规范第18章中所述的强制命中过程来确定。 对于当前文件,这可以在后台完成,但是以这种方式处理数千个未打开的文件将是一项昂贵的任务。
Here, however, it is possible to slightly cut corners: in most cases, we don’t need the concrete type. Unless a method accepts a generic parameter where the lambda is passed to it, the final parameter substitution step can be avoided. If we have inferred the java.util.function.Function<T, R> lambda type, we don't have to evaluate the values of the substitutional parameters T and R: it is already clear whether to include the lambda into search results or not. However, it won't work for a method like this:
但是,在这里可以稍微偷工减料:在大多数情况下,我们不需要具体的类型。 除非方法接受将lambda传递给它的通用参数,否则可以避免最后的参数替换步骤。 如果我们推断出java.util.function.Function<T, R> lambda类型,则不必评估替换参数T和R的值:已经很清楚是否将lambda包含在搜索结果中或不。 但是,它不适用于这样的方法:
static <T> void doSmth(Class<T> aClass, T value) {}This method can be called with doSmth(Runnable.class, () -> {}). Then the lambda type will be inferred as T, substitution still required. However, this is a rare case. We can actually save some CPU time here, but only about 10%, so this doesn't solve the problem in its essence.
可以使用doSmth(Runnable.class, () -> {})调用此方法。 然后,lambda类型将被推断为T ,仍然需要替换。 但是,这种情况很少见。 实际上,我们可以在这里节省一些CPU时间,但只能节省大约10%,因此这本质上不能解决问题。
Alternatively, when the precise type inference is too complicated, it can be made approximate. Unlike the specification suggests, let it work only on the erased class types and make no reduction of the set of constraints, but simply follow a call chain. As long as the erased type does not include generic parameters, everything is fine. Let's consider the stream from the example above and determine whether the last lambda implements StringConsumer:
或者,当精确类型推断太复杂时,可以使其近似。 与规范所建议的不同,让它仅适用于已擦除的类类型,并且不减少约束集,而只是遵循调用链。 只要擦除的类型不包含通用参数,一切都很好。 让我们考虑上面示例中的流,并确定最后一个lambda是否实现StringConsumer :
listvariable →java.util.Listtypelist变量→java.util.List类型List.stream()method →java.util.stream.StreamtypeList.stream()方法→java.util.stream.Stream类型Stream.filter(...)method →java.util.stream.Streamtype, we don't have to considerfilterargumentsStream.filter(...)方法→java.util.stream.Stream类型,我们不必考虑filter参数similarly,
Stream.map(...)method →java.util.stream.Streamtype类似地,
Stream.map(...)方法→java.util.stream.Stream类型Stream.forEach(...)method → such a method exists, its parameter hasConsumertype, which is obviously notStringConsumer.Stream.forEach(...)方法→这样的方法存在,其参数具有Consumer类型,显然不是StringConsumer。
And that's how we could do without regular type inference. With this simple approach, however, it is easy to run into overloaded methods. If we do not perform proper type inference, we cannot choose the correct overloaded method. Sometimes it's possible, however: if methods have a different number of parameters. For example:
这就是我们无需常规类型推断就可以做到的方式。 但是,使用这种简单方法,很容易遇到重载方法。 如果我们不执行正确的类型推断,则无法选择正确的重载方法。 但是,有时这是可能的:如果方法具有不同数量的参数。 例如:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));Here we can see that:
在这里我们可以看到:
There are two
CompletableFuture.supplyAsyncmethods; the first one takes one argument and the second takes two, so we choose the second one. It returnsCompletableFuture.有两种
CompletableFuture.supplyAsync方法; 第一个带有一个参数,第二个带有两个参数,因此我们选择第二个。 它返回CompletableFuture。There are two
thenRunAsyncmethods as well, and we can similarly choose the one that takes one argument. The corresponding parameter hasRunnabletype, which means it is notStringConsumer.thenRunAsync方法也有两种,我们可以类似地选择采用一个参数的方法。 相应的参数具有Runnable类型,这意味着它不是StringConsumer。
If several methods take the same number of parameters or have a variable number of parameters but look appropriate, we'll have to search through all the options. Often it's not that scary:
如果几种方法采用相同数量的参数或具有可变数量的参数但看上去合适,那么我们将必须搜索所有选项。 通常情况并不那么可怕:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));new StringBuilder()obviously createsjava.lang.StringBuilder. For constructors, we still resolve the reference, but complex type inference is not required here. Even if there wasnew Foo<>(x, y, z), we would not infer the values of the type parameters since onlyFoois of interest to us.new StringBuilder()显然会创建java.lang.StringBuilder。 对于构造函数,我们仍然解析该引用,但是这里不需要复杂的类型推断。 即使有new Foo<>(x, y, z),我们也不会推断类型参数的值,因为只有Foo是我们感兴趣的。There are a lot of
StringBuilder.appendmethods that take one argument, but they all returnjava.lang.StringBuildertype, so we do not care about the types offooandbar.有很多采用一个参数的
StringBuilder.append方法,但是它们都返回java.lang.StringBuilder类型,因此我们不在乎foo和bar的类型。There's one
StringBuilder.charsmethod, and it returnsjava.util.stream.IntStream.有一个
StringBuilder.chars方法,它返回java.util.stream.IntStream。There's a single
IntStream.forEachmethod, and it takesIntConsumertype.有一个
IntStream.forEach方法,它采用IntConsumer类型。
Even if several options remain, you can still track them all. For example, the lambda type passed to ForkJoinPool.getInstance().submit(...) may be Runnable or Callable, and if we are looking for another option, we can still discard this lambda.
即使剩下几个选项,您仍然可以跟踪它们。 例如,传递给ForkJoinPool.getInstance().submit(...)的lambda类型可能是Runnable或Callable ,并且如果我们正在寻找其他选项,我们仍然可以丢弃此lambda。
Things get worse when the method returns a generic parameter. Then the procedure fails and you have to perform proper type inference. However, we have supported one case. It is well showcased in my StreamEx library, which has an AbstractStreamEx<T, S extends AbstractStreamEx<T, S>> abstract class which contains methods like S filter(Predicate<? super T> predicate). Usually people work with a concrete StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> class. In this case, you can substitute the type parameter and find out that S = StreamEx.
当该方法返回通用参数时,情况会变得更糟。 然后,该过程将失败,您必须执行正确的类型推断。 但是,我们支持一种情况。 它在我的StreamEx库中得到了很好的展示,该库具有AbstractStreamEx<T, S extends AbstractStreamEx<T, S>>抽象类,其中包含诸如S filter(Predicate<? super T> predicate) 。 通常人们使用具体的StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>>类。 在这种情况下,您可以替换type参数并找出S = StreamEx 。
That's how we've got rid of the costly type inference for many cases. But we haven't done anything with the construction of PSI. It's disappointing to have parsed a file with 500 lines of code only to find out that the lambda on line 480 does not match our query. Let's get back to our stream:
这就是我们在许多情况下摆脱昂贵的类型推断的方式。 但是我们在PSI的构建上还没有做任何事情。 解析具有500行代码的文件只是发现第480行的lambda与我们的查询不匹配,这令人失望。 让我们回到我们的流:
list.stream()
.filter(s -> StringUtil.isNonEmpty(s))
.map(s -> s.trim())
.forEach(s -> list.add(s));If list is a local variable, a method parameter, or a field in the current class, already at the indexing stage, we can find its declaration and establish that the short type name is List. Accordingly, we can put the following information into the index for the last lambda:
如果list是局部变量,方法参数或当前类中的字段(已经在索引阶段),则可以找到其声明并确定短类型名称为List 。 因此,我们可以将以下信息放入最后一个lambda的索引中:
forEachmethod which takes one argument, called on the result of aforEach方法的参数类型,该方法采用一个参数,在采用一个参数的mapmethod which takes one argument, called on the result of amap方法的结果上调用,在采用一个参数的filtermethod which takes one argument, called on the result of afilter方法的结果上调用,在streammethod which takes zero arguments, called on astream方法的结果上调用它接受零个参数,在Listobject.List对象上调用。
All this information is available from the current file and, therefore, can be placed in the index. While searching, we request such information about all lambdas from the index and try to restore the lambda type without building a PSI. First, we'll have to perform a global search for classes with the short List name. Obviously, we will find not only java.util.List but also java.awt.List or something from the project code. Next, all these classes will go through the same approximate type inference procedure that we used before. Redundant classes are often quickly filtered out. For example, java.awt.List has no stream method, therefore it will be excluded. But even if something redundant remains and we find several candidates for the lambda type, chances are none of them will match the search query, and we will still avoid building a complete PSI.
所有这些信息都可以从当前文件中获得,因此可以放置在索引中。 在搜索时,我们从索引中请求有关所有lambda的此类信息,并尝试在不构建PSI的情况下还原lambda类型。 首先,我们必须使用短List名称对类进行全局搜索。 显然,我们不仅会找到java.util.List而且还会找到java.awt.List或项目代码中的某些内容。 接下来,所有这些类将经历与我们之前使用的相同的近似类型推断过程。 冗余类经常被快速过滤掉。 例如, java.awt.List没有stream方法,因此将其排除在外。 但是,即使有多余的东西,并且我们找到了多个lambda类型的候选者,也没有一个与搜索查询匹配,而且我们仍将避免构建完整的PSI。
Global search could turn out to be too costly (when a project contains too many List classes), or the beginning of the chain could not be resolved in the context of one file (say, it's a field of а parent class), or the chain could break as the method returns a generic parameter. We won't give up and will try to start over with global search on the next method of the chain. For example, for the map.get(key).updateAndGet(a -> a * 2) chain, the following instruction goes to the index:
全局搜索可能成本很高(当一个项目包含太多List类时),或者无法在一个文件的上下文中解析链的开头(例如,它是父类的一个字段),或者该方法返回通用参数时,链可能会断开。 我们不会放弃,并且将尝试从全球搜索开始寻找链的下一个方法。 例如,对于map.get(key).updateAndGet(a -> a * 2)链,以下指令进入索引:
updateAndGetmethod, called on the result of aupdateAndGet方法的单个参数的类型,该方法在具有一个参数的getmethod with one parameter, called on aget方法的结果上调用,该方法在Mapobject.Map对象上调用。
Imagine we're lucky, and the project has only one Map type—java.util.Map. It does have a get(Object) method, but, unfortunately, it returns a generic parameter V. Then we'll discard the chain and look for the updateAndGet method with one parameter globally (using the index, of course). And we are happy to discover that there are only three such methods in the project: in AtomicInteger, AtomicLong, and AtomicReference classes with parameter types IntUnaryOperator, LongUnaryOperator, and UnaryOperator, respectively. If we are looking for any other type, we have already discovered that this lambda does not match the request, and we don't have to build the PSI.
假设我们很幸运,该项目只有一个Map类型java.util.Map 。 它确实具有get(Object)方法,但是不幸的是,它返回了通用参数V 然后,我们将丢弃该链,并在全局范围内寻找带有一个参数的updateAndGet方法(当然使用索引)。 我们很高兴地发现项目中只有三种这样的方法:在AtomicInteger , AtomicLong和AtomicReference类中,参数类型分别为IntUnaryOperator , LongUnaryOperator和UnaryOperator 。 如果我们正在寻找其他任何类型,我们已经发现该lambda与请求不匹配,并且我们不必构建PSI。
Surprisingly, this is a good example of a feature which works slower with time. For example, when you are looking for implementations of a functional interface and have only three of them in your project, it takes ten seconds for IntelliJ IDEA to find them. You remember that three years ago their number was the same, but the IDE provided you with the search results in just two seconds on the same machine. And though your project is huge, it has grown only by five percent over these years. It's reasonable to start grumbling about what the IDE developers have done wrong to make it so terribly slow.
令人惊讶的是,这是一个功能随时间推移变慢的很好示例。 例如,当您正在寻找功能接口的实现并且在项目中只有三个时,IntelliJ IDEA会花十秒钟的时间来找到它们。 您还记得三年前它们的数量相同,但是IDE在同一台计算机上仅两秒钟就为您提供了搜索结果。 尽管您的项目规模巨大,但这些年来仅增长了5%。 开始抱怨IDE开发人员做错了什么使它变得如此缓慢非常合理。
While we might have changed nothing at all. The search works just as it used to three years ago. The thing is that three years ago, you just switched to Java 8 and only had a hundred lambdas in your project. By now, your colleagues have turned anonymous classes into lambdas, have started using streams or some reactive library. As a result, instead of a hundred lambdas, there are ten thousand. And now, to find the three necessary ones, the IDE has to search through a hundred times more options.
虽然我们可能什么都没有改变。 搜索工作与三年前一样。 事实是,三年前,您刚切换到Java 8,而您的项目中只有100个lambda。 到目前为止,您的同事已将匿名类转换为lambda,开始使用流或某些React式库。 结果,不是一百个lambda,而是一万个。 现在,要找到三个必要的选项,IDE必须搜索一百倍以上的选项。
I said “we might” because, naturally, we get back to this search from time to time and try speeding it up. But it's like rowing up the stream, or rather up the waterfall. We try hard, but the number of lambdas in projects keeps growing very fast.
我说“我们可以”,是因为我们自然会不时返回此搜索并尝试加快搜索速度。 但这就像在溪流中划船,或者是在瀑布上划船一样。 我们尽力而为,但是项目中的lambda数量一直在快速增长。















 1683
1683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









