





c# 值类型引用类型堆栈

免责声明 (Disclaimer)
This article does not contain material that should be used in real projects. It is simply an extension of the boundaries in which a programming language is perceived.
本文不包含实际项目中应使用的材料。 它只是感觉到编程语言的界限的扩展。
Before proceeding with the story, I strongly recommend you to read the first post about StructLayout, because there is an example that will be used in this article (However, as always).
在继续讲故事之前,我强烈建议您阅读有关StructLayout的第一篇文章,因为本文中将使用一个示例(但是,一如既往)。
史前史 (Prehistory)
Starting to write code for this article, I wanted to do something interesting using assembly language. I wanted to somehow break the standard execution model and get a really unusual result. And remembering how often people say that the reference type differs from the value types in that the first ones are located on the heap and the second ones are on the stack, I decided to use an assembler to show that the reference type can live on the stack. However, I began to run into all sorts of problems, for example, returning the address and its presentation as a managed link (I am still working on it). So I started to cheat and do something that does not work in assembly language, in C #. And in the end, there was no assembler at all.
开始为本文编写代码时,我想使用汇编语言做一些有趣的事情。 我想以某种方式打破标准执行模型,并得到一个非常不寻常的结果。 记得人们经常说引用类型与值类型的不同之处在于,第一个位于堆上,第二个位于堆栈上,我决定使用汇编程序来表明引用类型可以存在于值类型上。堆栈。 但是,我开始遇到各种各样的问题,例如,将地址及其表示形式作为托管链接返回(我仍在研究中)。 因此,我开始作弊,并在C#中做一些在汇编语言中不起作用的事情。 最后,根本没有汇编程序。
Also read recommendation — if you are familiar with the layout of reference types, I recommend skipping the theory about them (only the basics will be given, nothing interesting).
另请阅读推荐-如果您熟悉引用类型的布局,我建议跳过有关它们的理论(仅提供基本知识,没有什么有趣的意思)。
有关类型内部的一些知识(对于旧框架,现在有些偏移已更改,但总体架构相同) (A little about the types' internals(for old framework, now some offsets are changed, but overall schema is the same))
I would like to remind that the division of memory into a stack and a heap occurs at the .NET level, and this division is purely logical; there is physically no difference between the memory areas under the heap and the stack. The difference in productivity is provided only by different algorithms of working with these two areas.
我想提醒一下,将内存分为堆栈和堆是在.NET级别进行的,并且这种划分纯粹是逻辑上的。 堆和堆栈下的内存区域在物理上没有区别。 生产率的差异仅由使用这两个区域的不同算法提供。
Then, how to allocate memory on the stack? To begin with, let's understand how this mysterious reference type is arranged and what it has, that value type doesn't have.
那么,如何在堆栈上分配内存? 首先,让我们了解这种神秘的引用类型的排列方式以及它具有的值类型所没有的。
So, consider the simplest example with the class Employee.
因此,请考虑Employee类的最简单示例。
代码员工 (Code Employee)
public class Employee
{
private int _id;
private string _name;
public virtual void Work()
{
Console.WriteLine(“Zzzz...”);
}
public void TakeVacation(int days)
{
Console.WriteLine(“Zzzz...”);
}
public static void SetCompanyPolicy(CompanyPolicy policy)
{
Console.WriteLine("Zzzz...");
}
}And lets take a look at how it is presented in memory.
让我们看一下它在内存中的呈现方式。
This class is considered on the example of a 32-bit system.
在32位系统的示例中考虑此类。
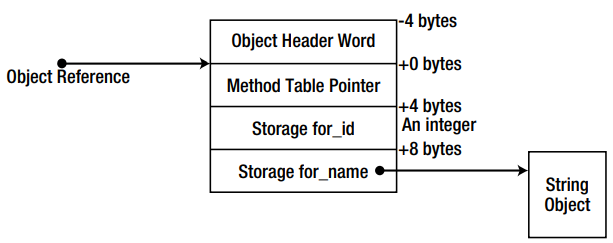
Thus, in addition to the memory for the fields, we have two more hidden fields — the index of the synchronization block (object header word title in the picture) and the address of the method table.
因此,除了这些字段的存储空间外,我们还有两个其他隐藏字段-同步块的索引(图片中的对象标头单词标题)和方法表的地址。
The first field (the synchronization block index) does not really interest us. When placing the type I decided to skip it. I did this for two reasons:
第一个字段(同步块索引)对我们并不真正感兴趣。 当放置类型时,我决定跳过它。 我这样做有两个原因:
- I am very lazy (I did not say that the reasons will be reasonable) 我很懒(我没有说理由会合理)
- For the basic operation of the object, this field is not required. 对于对象的基本操作,此字段不是必需的。
But since we have already started talking, I think it is right to say a few words about this field. It is used for different purposes (hash code, synchronization). Rather, the field itself is simply an index of one of the synchronization blocks associated with the given object. Blocks themselves are located in the table of synchronization blocks (something like global array). Creating such a block is a rather large operation, so it is not created if it is not needed. Moreover, when using thin locks, the identifier of the thread that received the lock (instead of the index) will be written there.
但是,既然我们已经开始讨论,我认为对这一领域说几句话是正确的。 它用于不同的目的(哈希码,同步)。 而是,字段本身只是与给定对象关联的同步块之一的索引。 块本身位于同步块表中(类似于全局数组)。 创建这样的块是一个相当大的操作,因此如果不需要,则不会创建它。 此外,当使用细锁时,接收到该锁的线程的标识符(而不是索引)将被写入那里。
The second field is much more important for us. Thanks to the table of type methods, such a powerful tool as polymorphism is possible (which, by the way, structures, stack kings, do not possess).
第二个领域对我们来说更为重要。 由于使用了类型方法表,因此可以使用诸如多态性这样的强大工具(顺便说一下,结构,堆栈国王不具备)。
Suppose that the Employee class additionally implements three interfaces: IComparable, IDisposable, and ICloneable.
假设Employee类另外实现了三个接口:IComparable,IDisposable和ICloneable。
Then the table of methods will look something like this.
然后,方法表将如下所示。
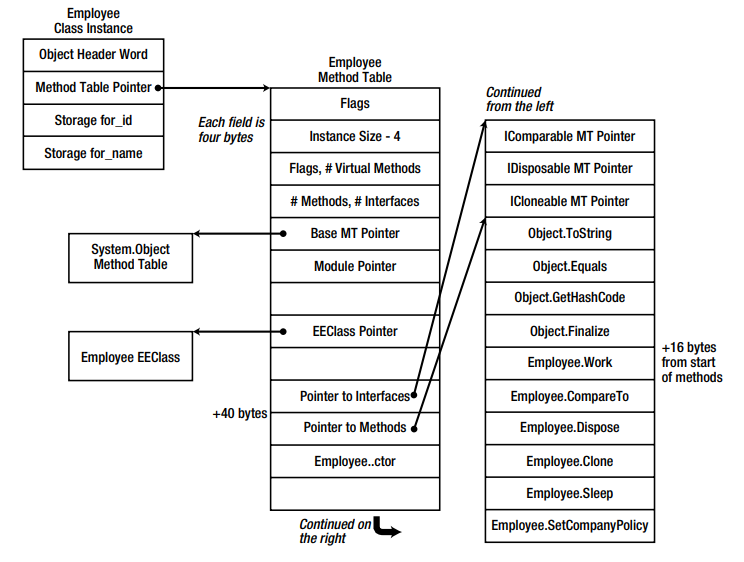
The picture is very cool, everything is shown and everything is clear. To sum up, the virtual method is not called directly by address, but by the offset in the method table. In the hierarchy, the same virtual methods will be located at the same offset in the method table. That is, on the base class we call the method by offset, not knowing which type of method table will be used, but knowing that this offset will be the most relevant method for the type of runtime.
图片非常酷,所有内容均已显示且所有内容均清晰可见。 总而言之,虚拟方法不是直接由地址调用,而是由方法表中的偏移量调用。 在层次结构中,相同的虚拟方法将位于方法表中的相同偏移处。 也就是说,在基类上,我们通过偏移量调用方法,而不知道将使用哪种类型的方法表,但是知道此偏移量将是与运行时类型最相关的方法。
Also it is worth remembering that the object reference points just to the method table pointer.
同样值得记住的是,对象引用仅指向方法表指针。
期待已久的例子 (Long-awaited example)
Let's start with classes that will help us in our goal. Using StructLayout (I really tried without it, but it didn't work out), I wrote simple mappers — pointers to managed types and back. Getting a pointer from a managed link is pretty easy, but the inverse transformation caused me difficulties and, without thinking twice, I applied my favorite attribute. To keep the code in one key, made in 2 directions in one way.
让我们从有助于我们实现目标的课程开始。 使用StructLayout(我确实尝试过不带它,但没有解决),我编写了简单的映射器-指向托管类型和返回类型的指针。 从托管链接获取指针非常容易,但是逆变换给我带来了麻烦,并且我三思而后行地应用了我最喜欢的属性。 为了将代码保持在一个键中,以一种方式在两个方向上进行编码。
映射器的代码 (Code of the mappers)
// Provides the signatures we need
public class PointerCasterFacade
{
public virtual unsafe T GetManagedReferenceByPointer<T>(int* pointer) => default(T);
public virtual unsafe int* GetPointerByManagedReference<T>(T managedReference) => (int*)0;
}
// Provides the logic we need
public class PointerCasterUnderground
{
public virtual T GetManagedReferenceByPointer<T>(T reference) => reference;
public virtual unsafe int* GetPointerByManagedReference<T>(int* pointer) => pointer;
}
[StructLayout(LayoutKind.Explicit)]
public class PointerCaster
{
public PointerCaster()
{
pointerCaster= new PointerCasterUnderground();
}
[FieldOffset(0)]
private PointerCasterUnderground pointerCaster;
[FieldOffset(0)]
public PointerCasterFacade Caster;
}First, we write a method that takes a pointer to some memory (not necessarily on the stack, by the way) and configures the type.
首先,我们编写一个方法,该方法采用指向某个内存的指针(顺便说一句,不一定要在堆栈上)并配置类型。
For the simplicity of finding the address of the method table, I create a type on the heap. I am sure that the table of methods can be found in other ways, but I did not set myself the goal of optimizing this code, it was more interesting for me to make it understandable. Further, using the previously described converters, we obtain a pointer to the type created.
为了简化方法表地址的查找,我在堆上创建一个类型。 我确信可以通过其他方式找到方法表,但是我没有设定优化该代码的目标,对我来说,使其变得可理解更有趣。 此外,使用前面描述的转换器,我们获得指向所创建类型的指针。
This pointer points exactly to the method table. Therefore, it is sufficient to simply obtain the contents from the memory it points to. This will be the address of the method table.
该指针恰好指向方法表。 因此,从它所指向的存储器中简单地获取内容就足够了。 这将是方法表的地址。
And since the pointer passed to us is a kind of object reference, we must also write the address of the method table exactly where it points.
并且由于传递给我们的指针是一种对象引用,因此我们还必须将方法表的地址确切地写到它指向的位置。
Actually, that's all. Suddenly, right? Now our type is ready. Pinocchio, who allocated memory to us, will take care of initializing the fields himself.
实际上,仅此而已。 突然吧 现在我们的类型准备好了。 分配给我们内存的Pinocchio将亲自初始化这些字段。
It remains only to use our ultra-mega caster to convert the pointer into a managed link.
仍然仅需使用我们的超大型脚轮将指针转换为托管链接。
public class StackInitializer
{
public static unsafe T InitializeOnStack<T>(int* pointer) where T : new()
{
T r = new T();
var caster = new PointerCaster().Caster;
int* ptr = caster.GetPointerByManagedReference(r);
pointer[0] = ptr[0];
T reference = caster.GetManagedReferenceByPointer<T>(pointer);
return reference;
}
}Now we have a link on the stack that points to the same stack, where according to all the laws of reference types (well, almost) lies an object constructed from black earth and sticks. Polymorphism is available.
现在,我们在堆栈上有一个指向同一堆栈的链接,根据所有引用类型的定律(差不多),该对象位于一个由黑土和木棍构成的对象中。 多态是可用的。
It should be understood that if you pass this link outside the method, then after returning from it, we will get something unclear. About calls of virtual methods and speech can not be, the exception will occur. Normal methods are called directly, the code will just have addresses for real methods, so they will work. And in place of the fields will be… and no one knows what will be there.
应该理解的是,如果将此链接传递给方法之外,则在返回该链接之后,我们将获得一些不清楚的地方。 关于虚拟方法和语音的调用不能进行,会发生异常。 普通方法被直接调用,代码中仅包含真实方法的地址,因此它们可以工作。 而且将取代田地……而没人知道那里会有什么。
Since it is impossible to use a separate method for initialization on the stack (since the stack frame will be overwritten after returning from the method), the method that wants to apply the type on the stack must allocate memory. Strictly speaking, there are some ways to do it. But the most suitable for us is
由于不可能在堆栈上使用单独的方法进行初始化(因为从该方法返回后堆栈帧将被覆盖),因此要在堆栈上应用类型的方法必须分配内存。 严格来说,有一些方法可以做到这一点。 但是最适合我们的是
栈分配 (stackalloc)
. Just the perfect keyword for our purposes. Unfortunately, it brings the
。 只是我们目的的完美关键字。 不幸的是,它带来了
代码中 unsafe in the code. Before that, there was an idea to use Span for these purposes and to do without unsafe code. In the unsafe code there is nothing bad, but like everywhere, it is not a silver bullet and has its own areas of application. 不安全 。 在此之前,有一个想法将Span用于这些目的,并且没有不安全的代码。 在不安全的代码中,没有什么不好,但是像其他地方一样,它不是灵丹妙药,它有自己的应用领域。Then, after receiving the pointer to the memory on the current stack, we pass this pointer to the method that makes up the type in parts. That's all who listened — well done.
然后,在收到指向当前堆栈上的内存的指针之后,我们将此指针传递给组成类型的方法。 这就是所有听过的人-做得好。
unsafe class Program
{
public static void Main()
{
int* pointer = stackalloc int[2];
var a = StackInitializer.InitializeOnStack<StackReferenceType>(pointer);
a.StubMethod();
Console.WriteLine(a.Field);
Console.WriteLine(a);
Console.Read();
}
}You should not use it in real projects, the method allocating memory on the stack uses new T (), which in turn uses reflection to create a type on the heap! So this method will be slower than the usual creation of the type of times well, in 40-50. Moreover it is not cross platform.
您不应该在实际项目中使用它,在堆栈上分配内存的方法使用new T(),后者又使用反射在堆上创建类型! 因此,此方法将比通常创建的时间类型慢40-50。 而且它不是跨平台的。
Here you can find whole project. 在这里您可以找到整个项目。Source: in the theoretical guide, examples from the book Sasha Goldstein — Pro .NET Performace were used
资料来源:在理论指南中,使用了Sasha Goldstein-Pro .NET Performace一书中的示例
c# 值类型引用类型堆栈
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









