






 patroni 集群安装Miro. Our service is a high-load one: it is used by 4 million users worldwide, daily active users - 168,000. Our servers are hosted by Amazon and located in a single Ireland region. We hav...
patroni 集群安装Miro. Our service is a high-load one: it is used by 4 million users worldwide, daily active users - 168,000. Our servers are hosted by Amazon and located in a single Ireland region. We hav...
patroni 集群安装
Miro. Our service is a high-load one: it is used by 4 million users worldwide, daily active users - 168,000. Our servers are hosted by Amazon and located in a single Ireland region. We have more than 200 active servers, with almost 70 of them being database servers. Miro的DevOps团队负责人。 我们的服务是一项高负载的服务:全世界有400万用户在使用,每日活跃用户-168,000。 我们的服务器由亚马逊托管,位于单个爱尔兰地区。 我们有200多个活动服务器,其中将近70个是数据库服务器。The service's backend is a monolith stateful Java application that maintains a persistent WebSocket connection for each client. When several users collaborate using the same whiteboard, they see changes on the whiteboard in real-time. That's because we write every change to a database, resulting in ~20,000 requests per second to the databases. During peak hours, the data is written to Redis at ~80,000–100,000 RPS.
服务的后端是一个整体的有状态Java应用程序,它为每个客户端维护一个持久的WebSocket连接。 当多个用户使用同一白板进行协作时,他们会实时查看白板上的更改。 那是因为我们将所有更改都写入数据库,导致每秒向数据库发出约20,000个请求。 在高峰时段,数据以大约80,000–100,000 RPS的速度写入Redis。
I am going to speak about why it is important to us to maintain PostgreSQL high availability, what methods we've applied to solve the problem, and what results we've achieved so far.
我要讲的是为什么保持PostgreSQL高可用性对我们很重要,我们已经采用了什么方法来解决该问题,以及到目前为止我们取得了什么结果。
为什么我们从Redis切换到PostgreSQL (Why We Switched From Redis to PostgreSQL)
In the beginning, our service worked with the Redis key-value database that stores all data in the server's RAM.
最初,我们的服务与Redis键值数据库一起使用,该数据库将所有数据存储在服务器的RAM中。
Pros of using Redis:
使用Redis的优点:
- It responds quickly, as all data is stored in RAM. 由于所有数据都存储在RAM中,因此响应速度很快。
- Redis instances are convenient to back up and replicate. Redis实例方便备份和复制。
Cons of using Redis for us:
为我们使用Redis的缺点:
- Redis lacks true transactions. We tried to imitate them in the application; unfortunately, this approach didn't work very well and required writing very complex code. Redis缺乏真实的交易。 我们试图在应用程序中模仿它们; 不幸的是,这种方法不能很好地工作,并且需要编写非常复杂的代码。
- The amount of data you can put in Redis is limited by the server's memory amount. The RAM consumption will increase as data volume grows, resulting in hitting the limitations of a chosen instance. To change the instance type in AWS, it is required to stop the whole service. 可以放入Redis的数据量受服务器的内存量限制。 RAM消耗将随着数据量的增长而增加,从而达到所选实例的限制。 要在AWS中更改实例类型,需要停止整个服务。
- For us, it is necessary to always keep latency low due to a large number of requests. We consider a 0.17–0.20ms latency optimal. With 0.30–0.40ms latency, it will take a lot of time for backend application to respond, resulting in degraded service. Unfortunately, this happened to us in September 2018, when one of the Redis instances had a latency twice as high compared to a baseline. To mitigate this issue, we stopped the service in the middle of the day and replaced the problem Redis instance. 对于我们来说,由于大量的请求,有必要始终保持较低的延迟。 我们认为最佳时延为0.17–0.20ms。 在0.30–0.40ms的延迟下,后端应用程序需要大量时间才能响应,从而导致服务质量下降。 不幸的是,这发生在2018年9月,当时Redis实例之一的延迟是基线的两倍。 为了缓解此问题,我们在一天中停止了服务,并替换了有问题的Redis实例。
- It is easy to render the data inconsistent, even if the errors in the source code are minor, and then spend a lot of time writing code that will fix this inconsistency. 即使源代码中的错误很小,也很容易使数据不一致,然后花费大量时间编写可解决此不一致问题的代码。
We considered these cons and understood that we had to switch to something that is handier, has true transactions, and is less influenced by latency. We conducted research, analyzed a variety of options, and then chose PostgreSQL.
我们考虑了这些缺点,并了解到我们必须切换到更方便,具有真实事务且受延迟影响较小的事物。 我们进行了研究,分析了各种选择,然后选择了PostgreSQL。
As of now, we have been moving to this new database for 2 years and have migrated only a half portion of data so far - that's why we are working with Redis and PostgreSQL in parallel.
截至目前,我们已经迁移到该新数据库已有两年了,到目前为止,仅迁移了一半的数据-这就是为什么我们同时使用Redis和PostgreSQL。
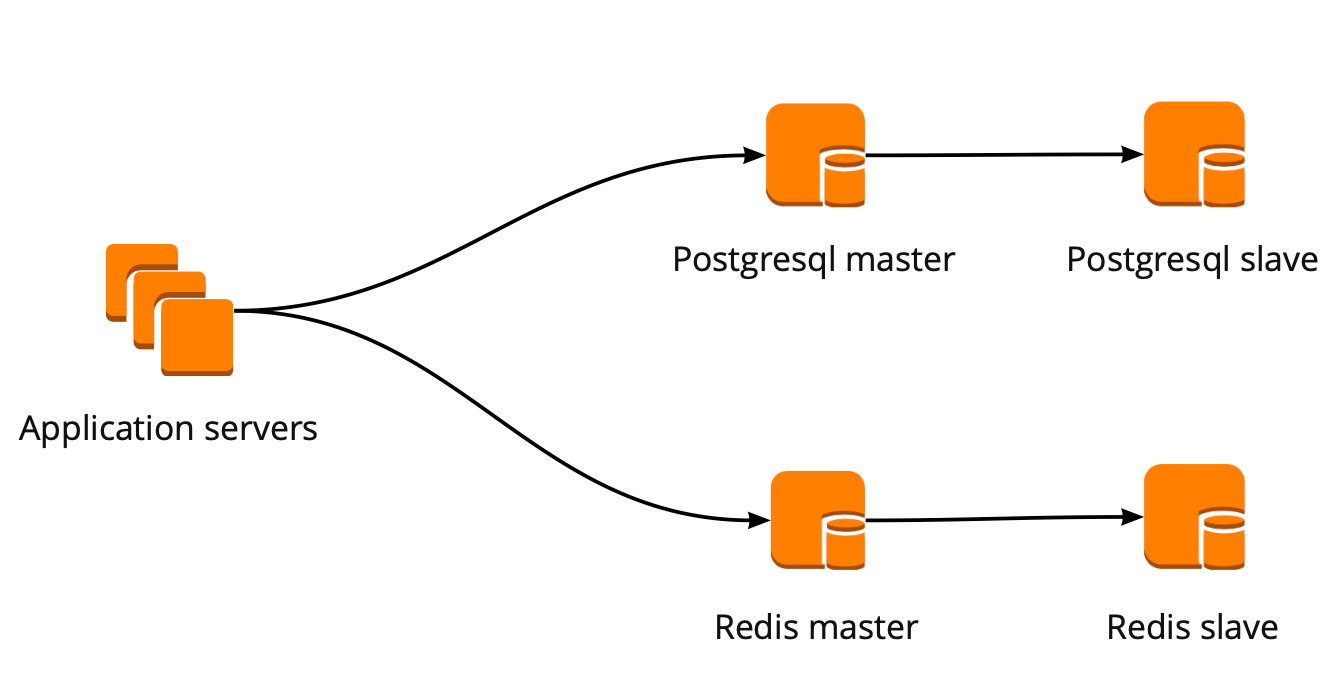
At the very beginning of this migration, our application interacted with the database in a direct way, querying both Redis and PostgreSQL masters. The PostgreSQL cluster comprised the master and the slave with async replication. The scheme of interaction was as follows:
在迁移的开始,我们的应用程序就直接与数据库交互,同时查询Redis和PostgreSQL主数据库。 PostgreSQL集群由具有异步复制功能的主服务器和从服务器组成。 交互方案如下:
实施PgBouncer (Implementing PgBouncer)
While we were migrating from one database to another, our product evolved: the number of users increased as did the number of servers that worked with PostgreSQL, and then the number of connections available became insufficient. PostgreSQL forks a separate process for each connection, consuming the computational resources. The number of connections can be increased only to a certain level; otherwise, there is a chance that the database operation will become nonoptimal. In this case, the ideal solution was to choose a connection manager and place it in front of the database.
当我们从一个数据库迁移到另一个数据库时,我们的产品不断发展:用户数量增加了,而与PostgreSQL合作的服务器数量也增加了,然后可用的连接数量变得不足。 PostgreSQL为每个连接创建一个单独的进程,从而消耗了计算资源。 连接数只能增加到一定水平。 否则,数据库操作可能会变得不理想。 在这种情况下,理想的解决方案是选择一个连接管理器并将其放置在数据库的前面。
We had two candidates for the connection manager: Pgpool and PgBouncer. The former does not support transactions when working with the database, so PgBouncer became our tool of choice.
对于连接管理器,我们有两个候选人:Pgpool和PgBouncer。 前者在使用数据库时不支持事务,因此PgBouncer成为我们的首选工具。
We came up with the following workflow: our application interacts with the single PgBouncer, PostgreSQL master instances are placed behind the PgBouncer, and a single slave with async replication enabled is placed behind each master instance.
我们提出了以下工作流程:我们的应用程序与单个PgBouncer交互,PostgreSQL主实例放置在PgBouncer的后面,单个启用了异步复制的从属放置在每个主实例的后面。
Then we began to shard the PostgreSQL database on an application level because we couldn't store all data in a single PostgreSQL database and we were concerned with the database speed. The scheme described above is quite convenient if you need to achieve the same goals: it is sufficient to update the PgBouncer configuration when adding a new PostgreSQL shard to make the application work with this shard immediately.
然后,我们开始在应用程序级别分片PostgreSQL数据库,因为我们无法将所有数据存储在单个PostgreSQL数据库中,并且我们担心数据库的速度。 如果您需要实现相同的目标,上述方案非常方便:在添加新的PostgreSQL分片时,更新PgBouncer配置就足够了,以使应用程序立即与此分片一起使用。
PgBouncer高可用性 (PgBouncer High Availability)
This scheme worked until our single PgBouncer instance died. We are hosted in AWS, where all instances run on hardware that dies periodically. If a piece of hardware dies, the instance is moved to a new piece of hardware and then runs. PgBouncer was moved too, but it became unavailable. Our service was down for 25 minutes as a result of this crash. Amazon suggests creating redundancy of critical services on the user side to fight such situations - something we hadn't implemented at that point.
该方案一直有效,直到我们的单个PgBouncer实例死亡。 我们托管在AWS中,其中所有实例都在定期失效的硬件上运行。 如果某个硬件死亡,则将该实例移至新的硬件,然后运行。 PgBouncer也已移动,但无法使用。 由于此崩溃,我们的服务中断了25分钟。 亚马逊建议在用户端创建关键服务的冗余以应对这种情况-当时我们尚未实现。
After this incident, we took PgBouncer and PostgreSQL cluster reliabi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









