





sql server 优化
In this blog post, we will look at one more Nested Loops (NL) Join Post Optimization Rewrite. This time we will talk about parallel NL and Few Outer Rows Optimization.
在此博客文章中,我们将再看一遍嵌套循环(NL)Join Post Optimization Rewrite。 这次我们将讨论并行NL和很少的外排优化。
For the demonstration purposes, I will use the enlarged version of AdventureWorks2014. In the sample query, I will also use the trace flag (TF) 8649 – this TF forces parallel plan when possible and is very convenient here, as we need one for the demo. There are also a few other undocumented TFs: TF 3604 – direct diagnostic output to console, TF 8607 – get a physical operator tree, before Post Optimization Rewrite, TF 7352 – get a tree after Post Optimization Rewrite phase.
出于演示目的,我将使用AdventureWorks2014的放大版本。 在示例查询中,我还将使用跟踪标记(TF)8649-该TF在可能的情况下强制执行并行计划,并且在这里非常方便,因为我们需要一个演示程序。 还有其他一些未记录的TF:TF 3604 –直接将诊断输出输出到控制台,TF 8607 –在优化后重写之前获得物理操作员树,TF 7352 –在优化后重写阶段之后获得树。
The sample query is asking for some data based on the period’s table.
示例查询正在根据期间表查询一些数据。
use AdventureWorks2014;
go
-- create and fill sample periods
if object_id('tempdb..#Periods') is not null drop table #Periods;
create table #Periods(DateStart datetime, DateEnd datetime);
insert #Periods values ('20110101','20110201'),('20120101','20120201'),('20130101','20130201'),('20140101','20140201');
go
-- get all the orders in the periods
set showplan_xml on;
go
select
soh.SalesOrderID,
soh.Comment
from
Sales.SalesOrderHeaderEnlarged soh
join #Periods p on soh.OrderDate >= p.DateStart and soh.OrderDate < p.DateEnd
option (
querytraceon 8649 -- Demand parallel plan
,querytraceon 3604 -- Output to console
,querytraceon 8607 -- Before Post Optimization Rewrite
,querytraceon 7352 -- After Post Optimization Rewrite
);
go
set showplan_xml off;
On the following picture, I combined two kinds of operator’s tree produced before the Post Optimization Rewrite and after with the Query Plan, colored and shortened output a little bit for better illustration.
在下面的图片中,我将在Post Optimization Rewrite之前和之后的Query Plan中结合了两种运算符树,并对输出进行了彩色和缩短,以更好地说明。
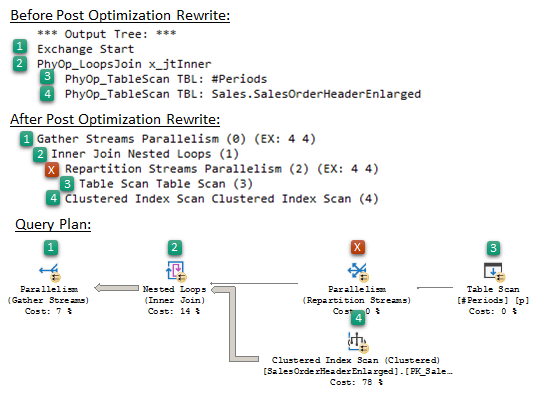
You may notice the node [X], missing in the first tree, that is a result of the cost-based optimization but presenting in the second tree and the query plan. That is the optimization introduced for the Parallel NL Join during the Post Optimization Rewrite and called Few Outer Rows Optimization.
您可能会注意到第一棵树中缺少的节点[X],这是基于成本的优化的结果,但出现在第二棵树和查询计划中。 这是在后期优化重写期间为并行NL连接引入的优化,称为“很少的外行优化”。
Without this optimization, the plan would be the following.
如果没有这种优化,则计划如下。
Why do we need this extra [Parallelism (Repartition Streams)] operator?
为什么我们需要这个额外的[Parallelism(Repartition Streams)]运算符?
外排很少优化 (Few Outer Rows Optimization)
When the Parallel Scan process begins, threads demand rows dynamically, as soon, as they need them. The Parallel Scan thread asks the so-called parallel page supplier to give it a bunch of pages for processing. Then Parallel Scan gets rows from those pages and working with them in a corresponding parallel plan branch. After it has done the processing, it sends the results to the parallel exchange buffers and demands the next portion of the pages.
并行扫描过程开始时,线程会在需要时立即动态地请求行。 并行扫描线程要求所谓的并行页面供应商提供一堆页面进行处理。 然后,并行扫描从这些页面获取行,并在相应的并行计划分支中使用它们。 完成处理后,它将结果发送到并行交换缓冲区,并要求页面的下一部分。
It may look like this.
它可能看起来像这样。
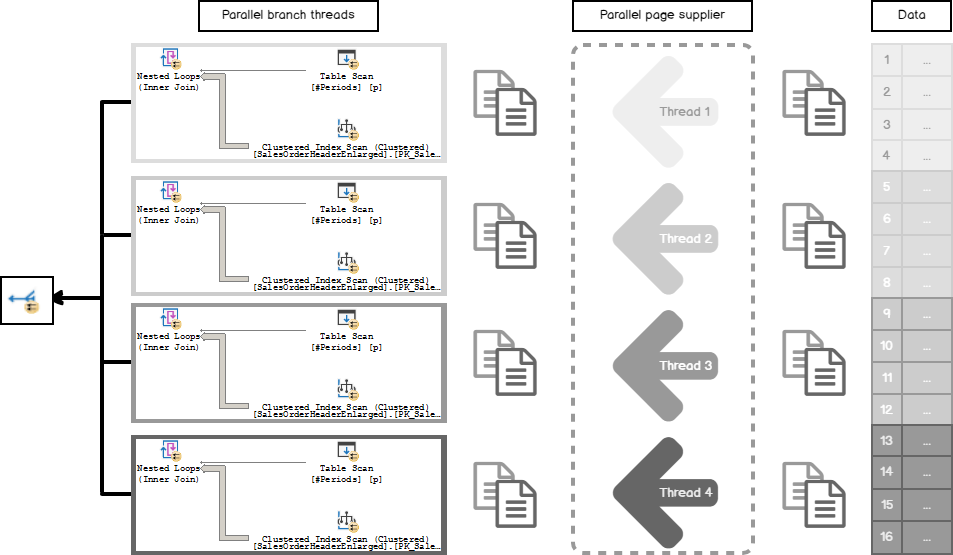
Each thread is given the demanded amount of pages to work with and processing them inside the parallel plan branch, then passing to the Gather Streams Exchange operator that combines results together. Each thread is doing its part of the work.
每个线程都获得了所需的页面数量,以在并行计划分支中进行处理并在并行计划分支中对其进行处理,然后传递给将结果组合在一起的Gather Streams Exchange运算符。 每个线程都在做其工作的一部分。
What if there are very few rows on the outer side of the NL and they fit only a few pages (let’s say a small table like the one we have in our example)? Then the thread that comes first will grab all of them leaving all other threads idle and doing all the work by itself.
如果NL的外侧上的行很少,并且仅容纳几页,那该怎么办?(比如说像我们示例中的那张小表)? 然后,第一个出现的线程将抓住所有线程,而使所有其他线程保持空闲状态,并独自完成所有工作。
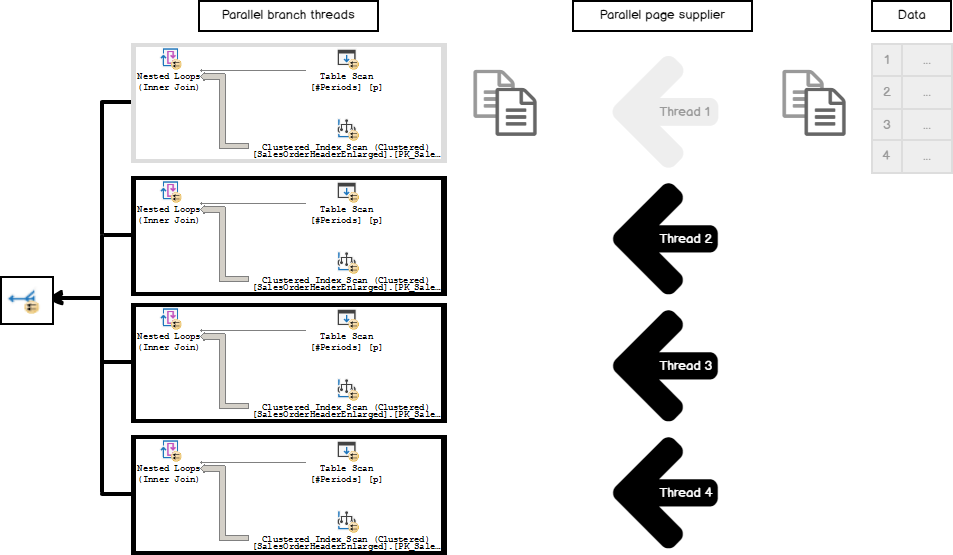
In that case, we will execute a parallel plan in one thread and that is not effective. This is an extreme case, nevertheless, in a real-life query, that kind of imbalance may significantly reduce the productivity of the query execution, but probably not at so high degree.
在这种情况下,我们将在一个线程中执行并行计划,但这是无效的。 但是,在极端情况下,这是一个极端情况,这种不平衡可能会显着降低查询执行的效率,但程度可能不那么高。
To prevent this situation, SQL Server introduces the Repartition Streams operator between the scan and the branch of work. It has a partitioning type Round Robin, which means that it sends each subsequent packet of rows to the next subsequent consumer thread, redistributing the rows in that manner.
为避免这种情况,SQL Server在扫描和工作分支之间引入了Repartition Streams操作符。 它具有分区类型Round Robin,这意味着它将每个后续行数据包发送到下一个后续使用者线程,从而以这种方式重新分配行。
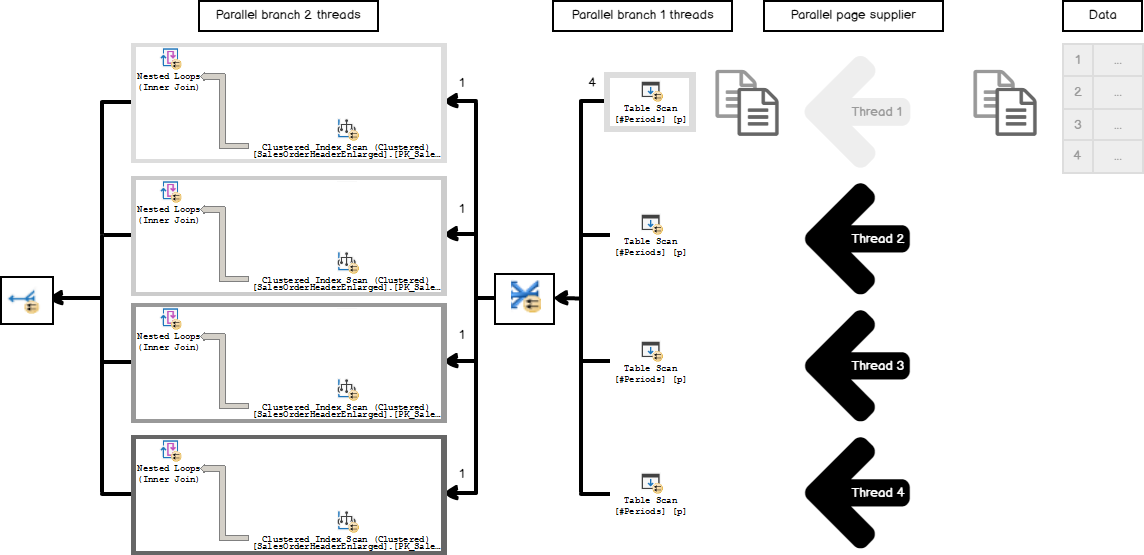
After that redistributing, the entire join related work is balanced between 4 threads.
重新分配之后,整个与连接有关的工作在4个线程之间平衡。
TF 2329 (TF 2329)
Now let’s compare the plans and time with that optimization and without it. To disable Few Outer Rows optimizations we will use the TF 2329. I have 4 cores on my machine, so there will be 4 threads per branch, you may have different results.
现在,让我们比较优化后和没有优化时的计划和时间。 要禁用少量外部行优化,我们将使用TF2329。我的计算机上有4个内核,因此每个分支有4个线程,您可能会有不同的结果。
set statistics time, xml on;
declare @SalesOrderID int, @Comment nvarchar(256);
select
@SalesOrderID = soh.SalesOrderID,
@Comment = soh.Comment
from
Sales.SalesOrderHeaderEnlarged soh
join #Periods p on soh.OrderDate >= p.DateStart and soh.OrderDate < p.DateEnd
option(querytraceon 8649);
select
@SalesOrderID = soh.SalesOrderID,
@Comment = soh.Comment
from
Sales.SalesOrderHeaderEnlarged soh
join #Periods p on soh.OrderDate >= p.DateStart and soh.OrderDate < p.DateEnd
option(querytraceon 8649, querytraceon 2329);
set statistics time, xml off;
The first plan is:
第一个计划是:
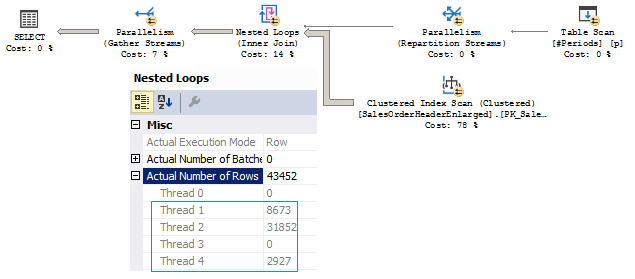
We may see that parallel page supplier passed all the four rows to one thread, however, Parallelism (Repartition Streams) operator redistributed rows between the threads and almost each of the threads did its piece of work scanning and joining the inner side of NL. That is much quite even work distribution (your results may vary depending on the SQL Server and Hardware configuration and workload).
我们可能会看到并行页面供应商将所有四行都传递给了一个线程,但是,并行(分区流)运算符在线程之间重新分配了行,并且几乎每个线程都完成了工作并扫描并连接了NL的内侧。 这甚至可以分配工作(您的结果可能会因SQL Server和硬件配置以及工作负载而异)。
The second plan:
第二个计划:
All the rows came to the Thread 3 this time, but it has no Parallelism (Repartition Streams), so all the work was done by a single thread. In fact, we have a serial execution of the parallel plan.
这次所有行都进入线程3,但是它没有并行性(分区流),因此所有工作都是由单个线程完成的。 实际上,我们已经并行执行了并行计划。
Now let’s look at the execution time.
现在让我们看一下执行时间。
The CPU time in the first case is slightly bigger: 1109 ms vs 952 ms – because real parallel work was done, however, the elapsed time is almost 2-3 time less than in the second query: 373 ms vs 992 ms. Of course, the 2-3 time speedup is an extreme case, but It is (or even more) still possible.
在第一种情况下,CPU时间略长:1109 ms与952 ms –因为完成了真正的并行工作,但是,经过的时间比第二种查询少了2-3倍:373 ms与992 ms。 当然,2-3次加速是一个极端的情况,但它仍然(甚至更多)是可能的。
Few Outer Rows Optimization is designed mostly for Data Warehouse workloads; however, it might happen anywhere if this pattern is recognized.
很少有外部行优化主要用于数据仓库工作负载; 但是,如果识别出此模式,它可能会发生在任何地方。
Previous article in this series:
本系列的上一篇文章:
sql server 优化















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









