





In this blog post, we are going to view some interesting model variation, that I’ve found while exploring the new CE.
在这篇博客中,我们将查看一些有趣的模型变体,这些变体是我在探索新的CE时发现的。
A model variation is a new concept in the cardinality estimation framework 2014, that allows easily turn on and off some model assumptions and cardinality estimation algorithms. Model variations are based on a mechanism of pluggable heuristics and may be used in special cases. I think they are left for Microsoft support to be able to address some client’s CE issues pointwise.
模型变化是基数估计框架2014中的新概念,它允许轻松打开和关闭一些模型假设和基数估计算法。 模型变化基于可插入启发式机制,并且可能在特殊情况下使用。 我认为他们需要微软的支持,以便能够解决一些客户的CE问题。
Today we are going to view some interesting model variation, that creates filtered statistics on-the-fly. I should give a disclaimer here.
今天,我们将看到一些有趣的模型变化,这些变化会动态创建过滤的统计信息。 我应该在此声明免责声明。
Warning: All the information below is presented for purely educational and curiosity purposes. This is completely undocumented and unsupported and should not ever be used in production systems unless Microsoft support will recommend you. More to the point, the usage of this model variation may affect the overall server performance in a negative way. This should be used for experiments and in the test environment only.
警告:以下所有信息仅出于教育和好奇的目的而提供。 这是完全没有文档证明和支持的,除非Microsoft支持会建议您,否则在生产系统中永远不要使用此方法。 更重要的是,使用此模型变体可能会对服务器的整体性能产生负面影响。 仅应将其用于实验和测试环境中。
Now, when I frightened everyone, let’s consider an example, in the AdventureWorks2012 database under compatibility level of SQL Server 2014.
现在,当我吓到所有人时,我们来看一个示例,该示例位于SQL Server 2014兼容级别下的AdventureWorks2012数据库中。
alter database AdventureWorks2012 set compatibility_level = 120;
go
select
count_big(*)
from
Sales.Customer c
join Person.Person p on c.PersonID = p.BusinessEntityID
where
c.TerritoryID = 3
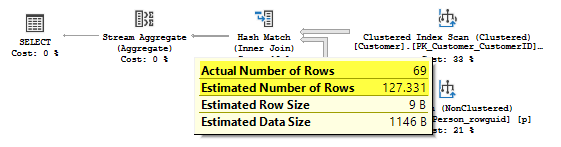
The join estimate is 127.331 rows, the actual number of rows is 69. This difference appears because the filter by TerritoryID column leverages the histogram of the join column PersonID in the estimation process, which is done in the bottom-up way, as we remember from the earlier posts.
联接估计为127.331行,实际行数为69。之所以出现此差异,是因为TerritoryID列的过滤器在估计过程中利用了联接列PersonID的直方图,这是我们自下而上的方式,我们记得从之前的帖子中。
Now, let’s manually create filtered statistics, re-run the query and then drop filtered statistics.
现在,让我们手动创建过滤的统计信息,重新运行查询,然后删除过滤的统计信息。
create statistics s_PersonID_TerritoryID_Equals3 on Sales.Customer(PersonID) where TerritoryID = 3;
go
dbcc freeproccache;
go
select
count_big(*)
from
Sales.Customer c
join Person.Person p on c.PersonID = p.BusinessEntityID
where
c.TerritoryID = 3
go
drop statistics Sales.Customer.s_PersonID_TerritoryID_Equals3;
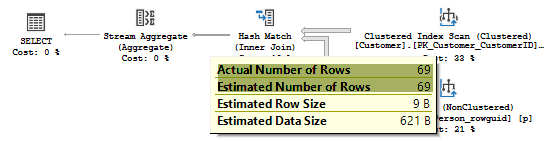
The estimate now is 69 rows, which equals the actual number of rows.
现在估计为69行,等于实际的行数。
Interesting, that SQL Server 2014 Cardinality Estimation Framework has an ability to do this operation on the fly, when it is considered to be beneficial and the model variation is forced to be used.
有趣的是,当SQL Server 2014基数估计框架被认为是有益的并且必须使用模型变体时,它具有即时执行此操作的能力。
To force this model variation we will use the undocumented TF 9483, we will also use TF 2363 to view diagnostic output, and use Profiler (or you may use xEvents) to watch the events: Performance: Auto Stats, Showplan XML Statistics Profile and SP:StmtCompleted.
为了强制这种模型变化,我们将使用未记录的TF 9483,我们还将使用TF 2363来查看诊断输出,并使用Profiler(或者您可以使用xEvents)观察事件:性能:自动统计,Showplan XML Statistics概要和SP :StmtCompleted。
Let’s run our query once again with all that stuff enabled.
让我们在启用所有这些功能的情况下再次运行查询。
select
count_big(*)
from
Sales.Customer c
join Person.Person p on c.PersonID = p.BusinessEntityID
where
c.TerritoryID = 3
option(
recompile,
querytraceon 3604,
querytraceon 2363,
querytraceon 9483
)
First, let’s look at the profile output, we’ll see a very interesting picture there:
首先,让我们看一下配置文件输出,我们将在其中看到一个非常有趣的图片:

Two filtered statistics on the fly were created, before the query plan was built, one of them is in the PersonID column, that we used in the Join.
在构建查询计划之前,已创建了两个即时过滤的统计信息,其中一个是在Join中使用的PersonID列中。
Now, if we look at the TF 2363 diagnostic output, among the other information, we’ll see:
现在,如果我们查看TF 2363诊断输出以及其他信息,我们将看到:
Now, if we look at the join estimates, we’ll see that this statistic was used to estimate the join like the one we created manually on the previous step, and the estimate is 69 rows, which is equal to the actual number of rows.
现在,如果我们查看联接估计,我们将看到该统计信息像我们在上一步中手动创建的联接那样用于估计联接,估计为69行,等于实际的行数。
If you try to find the created statistics in the sys.stats DMW – you will not find it there. It is created on the fly, during the query optimization and is not persisted in the sys.stats, that is why we didn’t see the Auto Stats event in the Profiler.
如果尝试在sys.stats DMW中查找创建的统计信息–您将不会在其中找到它。 它是在查询优化期间动态创建的,并且未持久保存在sys.stats中 ,这就是为什么我们在Profiler中没有看到Auto Stats事件的原因。
I think it is a very curious model variation, though it is quite resource intensive, to build the statistics each time you optimize a query, maybe there are certain scenarios and special cases where it will be beneficial and Microsoft decided to implement it as a model variation.
我认为这是一个非常奇怪的模型变体,尽管它非常耗费资源,但是每次优化查询时都要建立统计信息,也许在某些情况下和特殊情况下这将是有益的,Microsoft决定将其实现为模型变异。
That’s all for today. Next, we will talk about some other changes in the new Cardinality Estimation Framework.
今天就这些。 接下来,我们将讨论新的基数估计框架中的其他一些更改。
目录 (Table of Contents)
参考资料 (References)
- Statistics 统计
- Case of using filtered statistics 使用过滤统计信息的情况
- CREATE STATISTICS (Transact-SQL) 创建统计信息(Transact-SQL)
翻译自: https://www.sqlshack.com/filtered-stats-and-ce-model-variation/















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









