





ssis 计划任务
In this article, we will give a brief introduction of Hadoop and how it is integrated with SQL Server. Then, we will illustrate how to connect to the Hadoop cluster on-premises using the SSIS Hadoop connection manager and the related tasks.
在本文中,我们将简要介绍Hadoop及其与SQL Server的集成。 然后,我们将说明如何使用SSIS Hadoop连接管理器和相关任务连接到本地Hadoop集群。
介绍 (Introduction)
As defined in their official website, the Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. This framework is composed of five main components:
根据其官方网站上的定义,Apache Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。 该框架由五个主要组件组成:
- The Hadoop Distributed File System (HDFS): A file system used to store files in a distributed manner Hadoop分布式文件系统(HDFS) :一种用于以分布式方式存储文件的文件系统
- The Map-Reduce programming model: It allows processing massive data sets with a parallel and distributed algorithms on a cluster Map-Reduce编程模型:它允许在集群上使用并行和分布式算法处理海量数据集
- Hadoop YARN: It is responsible for managing cluster computing resources Hadoop YARN:负责管理集群计算资源
- Hadoop Common: A set of shared libraries between all Hadoop components Hadoop Common:所有Hadoop组件之间的一组共享库
- Hadoop Ozone: An object-store Hadoop Ozone:对象存储
Currently, Hadoop is the most known framework for building data lakes and data hubs.
当前,Hadoop是用于构建数据湖和数据中心的最著名的框架。
Since Hadoop is open-source, many software packages are developed to be installed on the top of it, such as Apache Hive and Apache Pig.
由于Hadoop是开源的,因此开发了许多要安装在其顶部的软件包,例如Apache Hive和Apache Pig。
Apache Hive is a data warehousing software that allows defining external table on the top of HDFS files and directories to query them using a SQL-like language called HiveQL.
Apache Hive是一种数据仓库软件,允许在HDFS文件和目录的顶部定义外部表,以使用类似于SQL的语言称为HiveQL来查询它们。
Since writing Map Reduce scripts using Java is a bit complicated, Apache Pig was developed to execute Map Reduce jobs using a language called Pig Latin, which is more straightforward.
由于使用Java编写Map Reduce脚本有点复杂,因此开发了Apache Pig以使用称为Pig Latin的语言执行Map Reduce作业,该语言更简单。
A few years ago, and due to the data explosion, relational database management systems started to adopt Big Data technologies in order to survive. The main goal was to create a bridge between the relational world and the new data technologies.
几年前,由于数据爆炸,关系数据库管理系统开始采用大数据技术以生存。 主要目标是在关系世界和新数据技术之间架起一座桥梁。
Regarding Microsoft SQL Server, since 2016, they added a bunch of features that make this management system adaptable by large enterprises:
关于Microsoft SQL Server,自2016年以来,他们添加了许多功能,使该管理系统适用于大型企业:
- Polybase: A technology that enables SQL Server to query external sources such as Hadoop and MongoDB Polybase :一种使SQL Server能够查询外部资源(如Hadoop和MongoDB)的技术
- JSON support JSON支持
-
- SSIS Hadoop connection manager SSIS Hadoop连接管理器
- Hadoop File System Task Hadoop文件系统任务
- Hadoop Hive Task Hadoop Hive任务
- Hadoop Pig Task Hadoop Pig任务
- HDFS File Source HDFS文件源
- HDFS File Destination HDFS文件目标
Note that, the Hadoop cluster hosted on the cloud (Azure) was supported since SQL Server 2012; HDInsight and other Microsoft Azure feature components were added to SSIS.
请注意,自SQL Server 2012起,就支持在云上托管的Hadoop群集(Azure);因此, HDInsight和其他Microsoft Azure功能组件已添加到SSIS 。
In this article, we will illustrate the SSIS Hadoop connection manager and the Hadoop File System Task hoping that the other tasks and components be explained in the future.
在本文中,我们将说明SSIS Hadoop连接管理器和Hadoop文件系统任务,希望以后再解释其他任务和组件。
To run this experiment, we installed Hadoop 3.2.1 single node on a machine where SQL Server 2017 and Integration Services are also installed.
为了运行此实验,我们在还安装了SQL Server 2017和Integration Services的计算机上安装了Hadoop 3.2.1单节点。
If you are looking to install Hadoop on Windows, I published a step-by-step guide to install Hadoop 3.2.1 single node on Windows 10 operating system on the “Towards Data Science” website.
如果要在Windows上安装Hadoop,我在“迈向数据科学”网站上发布了逐步指南,以在Windows 10操作系统上安装Hadoop 3.2.1单节点 。
SSIS Hadoop连接管理器
(SSIS Hadoop Connection Manager
)
To add an SSIS Hadoop connection manager, you should first right-click within the connection managers tab and click on “New Connection…”.
要添加SSIS Hadoop连接管理器,您首先应该在连接管理器选项卡中右键单击,然后单击“新建连接…”。
Figure 1 – Adding a new connection manager
图1 –添加新的连接管理器
Next, you should select Hadoop from the connection managers list:
接下来,您应该从连接管理器列表中选择Hadoop:
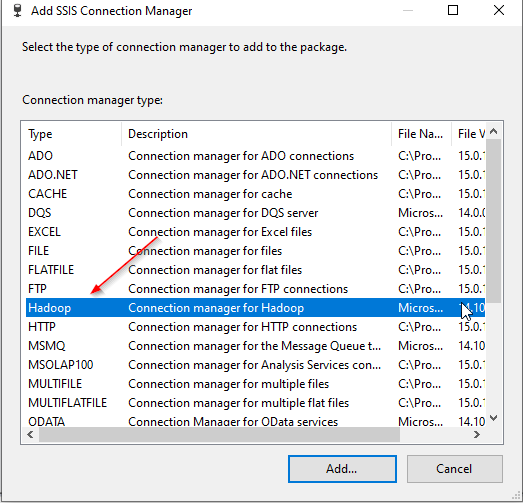
Figure 2 – Selecting SSIS Hadoop connection manager
图2 –选择SSIS Hadoop连接管理器
As shown in the figure below, the SSIS Hadoop connection manager editor contains two tab pages:
如下图所示,SSIS Hadoop连接管理器编辑器包含两个选项卡页面:
- WebHCat: This page is used to configure a connection that invokes a Hive or Pig job on Hadoop WebHCat:此页面用于配置在Hadoop上调用Hive或Pig作业的连接
- WebHDFS: This page is used to copy data from or to HDFS WebHDFS:此页面用于从HDFS复制数据或向HDFS复制数据
Figure 3 – SSIS Hadoop Connection manager editor
图3 – SSIS Hadoop连接管理器编辑器
In this article, we will use this connection manager to copy data to HDFS. Then, we will only use a WebHDFS connection. Note that the Hadoop cluster web interface can be accessed on the following URL: http://localhost:9870/
在本文中,我们将使用此连接管理器将数据复制到HDFS。 然后,我们将仅使用WebHDFS连接。 请注意,可以在以下URL上访问Hadoop集群Web界面:http:// localhost:9870 /
To configure the WebHDFS connection, we need to specify the following parameters:
要配置WebHDFS连接,我们需要指定以下参数:
- Enable WebHDFS Connection: We must check this option when you will use this connection manager for HDFS related tasks, as mention above
- 启用WebHDFS连接 : 如上所述,当您将此连接管理器用于HDFS相关任务时,必须选中此选项。
- WebHDFS Server: We should specify the server that hosts the Hadoop HDFS web service WebHDFS服务器:我们应该指定托管Hadoop HDFS Web服务的服务器
- WebHDFS Port: We should specify the port used by the Hadoop HDFS web service WebHDFS端口:我们应指定Hadoop HDFS Web服务使用的端口
- Authentication: We should specify the method for accessing the Hadoop web service. There are two methods available: 身份验证 :我们应该指定访问Hadoop Web服务的方法。 有两种方法可用:
- Kerberos 的Kerberos
- Basic 基本的
- WebHDFS User: We should specify the user name used to establish the connection WebHDFS用户 :我们应该指定用于建立连接的用户名
- Password (only available for Kerberos authentication) 密码 (仅适用于Kerberos身份验证)
- Domain (only available for Kerberos authentication) 域 (仅适用于Kerberos身份验证)
- HTTPS: This option must be selected if we need to establish a secure connection with the WebHDFS server HTTPS :如果我们需要与WebHDFS服务器建立安全连接,则必须选择此选项
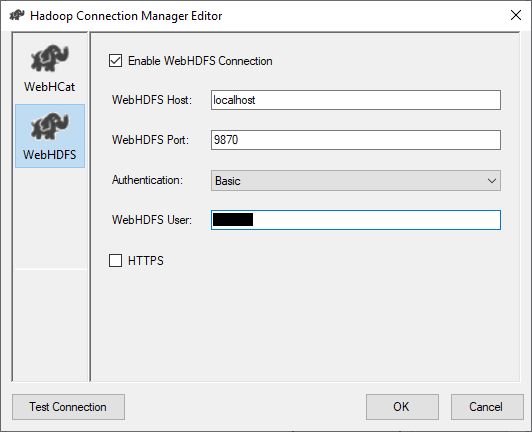
Figure 4 – Configuring WebHDFS connection
图4 –配置WebHDFS连接
After finishing the configuration, we click on the “Test Connection” button to check if the connection is configured correctly.
完成配置后,我们单击“测试连接”按钮以检查连接是否正确配置。
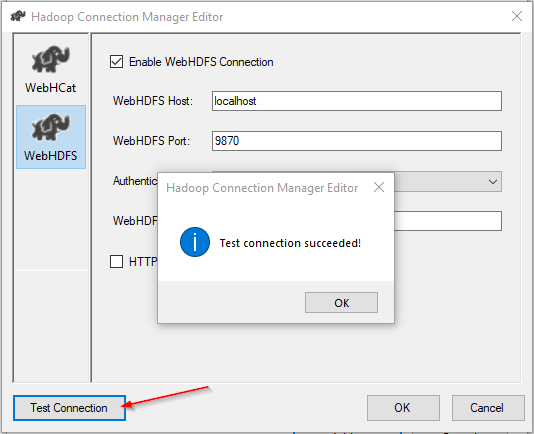
Figure 5 – Testing connection
图5 –测试连接
Since we have configured a WebHDFS connection, we will test it using the SSIS Hadoop File System Task.
由于已经配置了WebHDFS连接,因此我们将使用SSIS Hadoop文件系统任务对其进行测试。
- Note: 注意 : Configuring WebHCat connection is very similar, we will explain in a separate article where we will be talking about Executing Hive and Pig Tasks in SSIS配置WebHCat连接非常相似,我们将在另一篇文章中进行解释,我们将在其中讨论在SSIS中执行Hive和Pig任务
SSIS Hadoop文件系统任务 (SSIS Hadoop File System Task)
Figure 6 – Hadoop File System Task
图6 – Hadoop文件系统任务
IF we open the SSIS Hadoop file system task editor, we can see that the properties are classified into four categories:
如果我们打开SSIS Hadoop文件系统任务编辑器,我们可以看到属性分为四类:
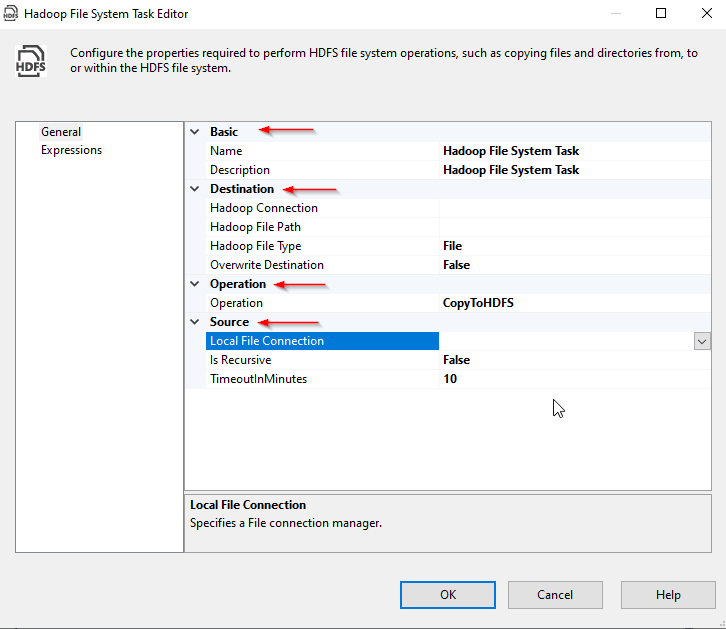
Figure 7 – Hadoop File System Task editor
图7 – Hadoop文件系统任务编辑器
- Basic: Contains the task name and description properties 基本:包含任务名称和描述属性
- Source: The source (file/directory) configuration 源:源(文件/目录)配置
- Destination: The destination (file/directory) configuration 目标:目标(文件/目录)配置
-
- Copy data from HDFS to the local file system (CopyFromHDFS) 将数据从HDFS复制到本地文件系统(CopyFromHDFS)
- Copy data from the local file system to HDFS (CopyToHDFS) 将数据从本地文件系统复制到HDFS(CopyToHDFS)
- Copy data within HDFS (CopyWithinHDFS) 在HDFS中复制数据(CopyWithinHDFS)
Figure 8 – Supported operations
图8 –支持的操作
The third operation (CopyWithinHDFS) only requires a Hadoop connection while the other requires an additional local file connection.
第三个操作(CopyWithinHDFS)仅需要Hadoop连接,而其他操作则需要附加的本地文件连接。
- Note:注意: The source and destination properties are dependants on the operation type源和目标属性取决于操作类型
We will not explain each property since they are all mentioned in the official documentation. Instead, we will run an example of CopyToHDFS operation.
我们不会解释每个属性,因为它们在正式文档中都已提及。 相反,我们将运行一个CopyToHDFS操作的示例。
将数据复制到HDFS (Copy data to HDFS)
In this section, we will copy a file into the Hadoop cluster. First, we need to add a File Connection Manager and configure it to read from an existing file, as shown in the screenshots below:
在本节中,我们将文件复制到Hadoop集群中。 首先,我们需要添加一个文件连接管理器并将其配置为从现有文件中读取,如以下屏幕截图所示:
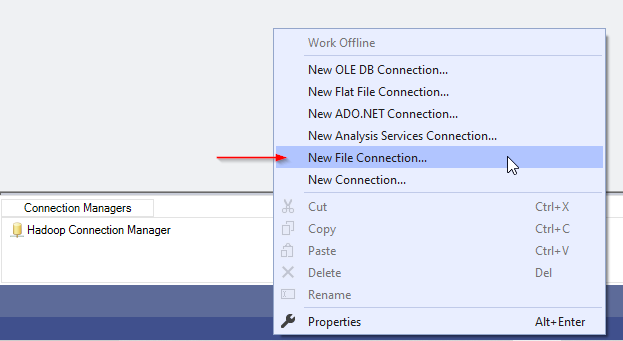
Figure 9 – Adding a File Connection Manager
图9 –添加文件连接管理器
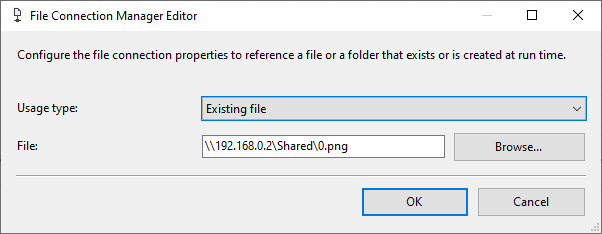
Figure 10 – Configuring File Connection to an existing file
图10 –配置与现有文件的文件连接
Then we configured the Hadoop file system task as the following:
然后,我们将Hadoop文件系统任务配置如下:
- Operation: CopyToHDFS 操作:CopyToHDFS
-
- Hadoop Connection: We selected the Hadoop connection manager Hadoop连接:我们选择了Hadoop连接管理器
- Hadoop File Path: /0.png (the file path should start with a slash “/”) Hadoop文件路径:/0.png(文件路径应以斜杠“ /”开头)
- Hadoop File Type: File Hadoop文件类型:文件
- Overwrite Destination: False 覆盖目标:False
-
- Local File Connection: We selected the File connection manager 本地文件连接:我们选择了文件连接管理器
- Is Recursive: False (This should be set to true when the source is a folder and we need to copy all subfolders) 是递归的:False(当源是文件夹并且我们需要复制所有子文件夹时,应将其设置为true)
- TimeoutInMinutes: 10 超时分钟:10
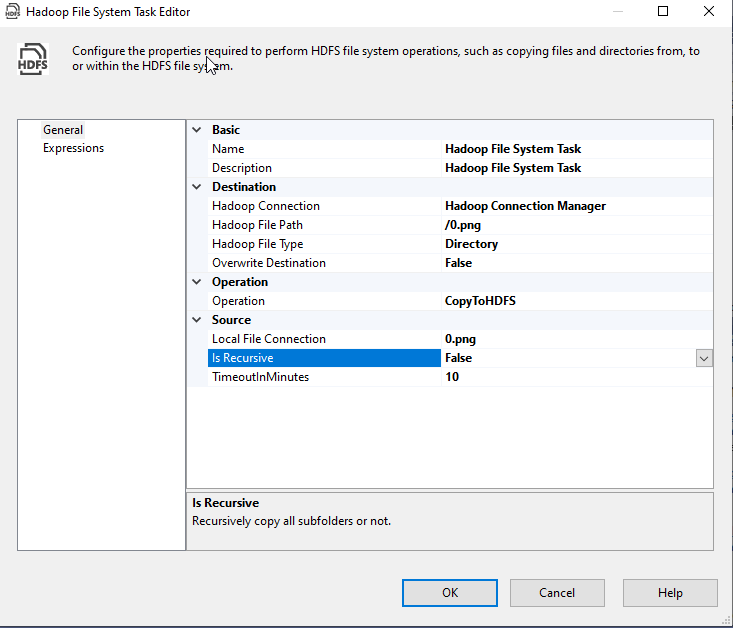
Figure 11 – Configuring CopyToHDFS operation
图11 –配置CopyToHDFS操作
After executing the package, we will go to the Hadoop web interface to check if the file is transferred successfully.
执行完软件包后,我们将转到Hadoop Web界面检查文件是否成功传输。
As mentioned in the previous section, the web interface can be accessed from the following URL: http://localhost:9870/ (as configured in the Hadoop installation article).
如上一节所述,可以从以下URL访问Web界面: http:// localhost:9870 / (在Hadoop安装文章中进行配置)。
In the web interface, in the top bar, Go to Utilities > Browse the File System.
在Web界面的顶部栏中,转到“实用程序”>“浏览文件系统”。
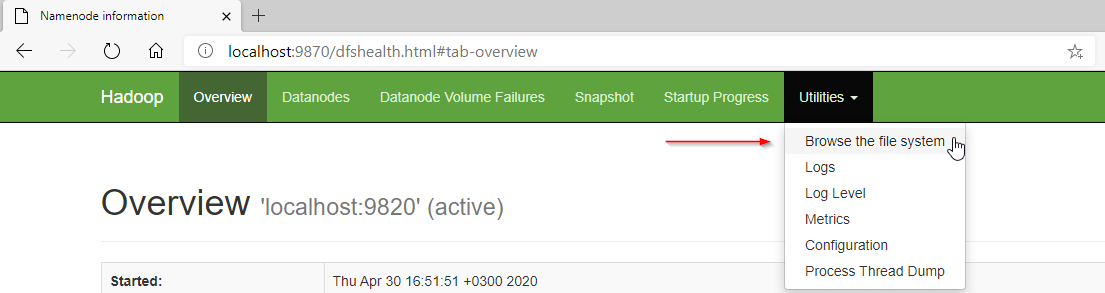
Figure 12 – Browsing the Hadoop file system from the web interface
图12 –从Web界面浏览Hadoop文件系统
Then we can see that 0.png is stored within HDFS main directory.
然后我们可以看到0.png存储在HDFS主目录中。
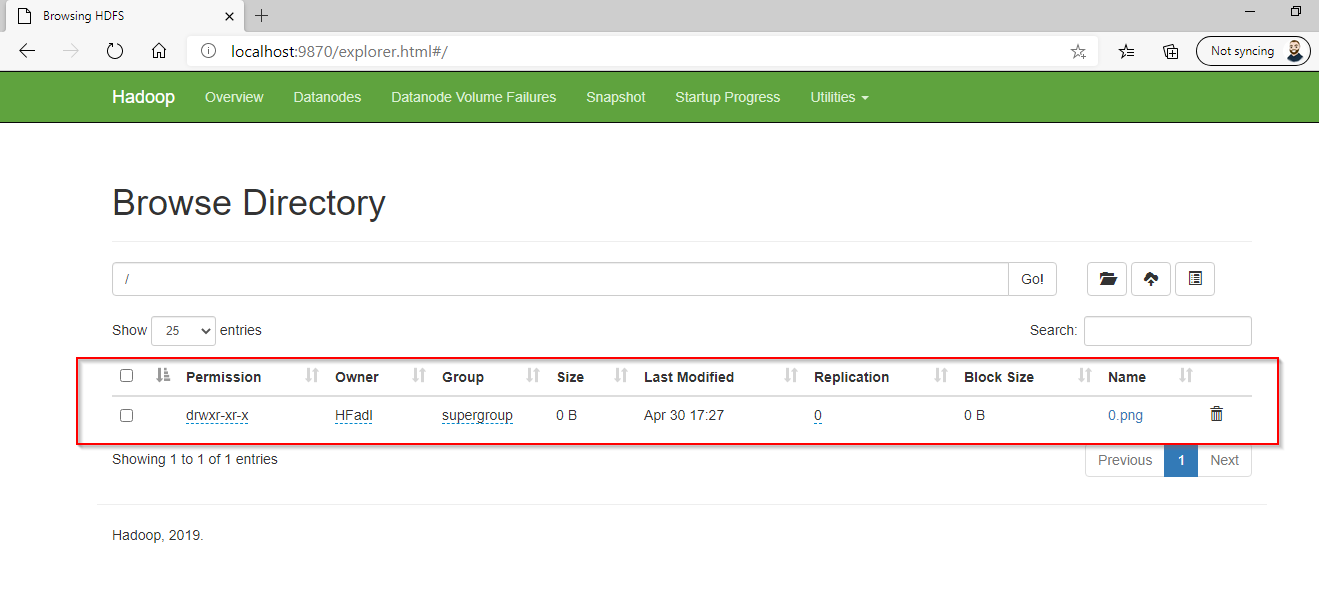
Figure 13 – File is located within HDFS main directory
图13 –文件位于HDFS主目录中
结论 (Conclusion)
In this article, we gave a brief overview of Hadoop and why relational data management systems adopted it. Then, we illustrated what the tasks and components added to SQL Server Integration Services (SSIS) are. We explained in detail how to use the SSIS Hadoop connection manager and Hadoop file system task. Finally, we ran an example of copying data from a local system file into the Hadoop cluster and how to browse the Hadoop file system from the web interface. We didn’t add examples of copying data within HDFS or into a local file since it is very similar.
在本文中,我们简要概述了Hadoop以及为什么关系数据管理系统采用Hadoop。 然后,我们说明了添加到SQL Server Integration Services(SSIS)中的任务和组件。 我们详细解释了如何使用SSIS Hadoop连接管理器和Hadoop文件系统任务。 最后,我们运行了一个示例,该示例将数据从本地系统文件复制到Hadoop集群中,以及如何从Web界面浏览Hadoop文件系统。 我们没有添加将数据复制到HDFS或本地文件中的示例,因为它们非常相似。
目录 (Table of contents)
| SSIS Hadoop Connection Manager and related tasks |
| Importing and Exporting data using SSIS Hadoop components |
| Connecting to Apache Hive and Apache Pig using SSIS Hadoop components |
| SSIS Hadoop连接管理器和相关任务 |
| 使用SSIS Hadoop组件导入和导出数据 |
| 使用SSIS Hadoop组件连接到Apache Hive和Apache Pig |
翻译自: https://www.sqlshack.com/ssis-hadoop-connection-manager-and-related-tasks/
ssis 计划任务















 1192
1192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









