





 本文介绍了在SQL Server中使用不同方法从其他表更新表数据的技术。包括使用JOIN方法、MERGE语句和子查询方法进行更新操作,以及如何通过索引优化性能。
本文介绍了在SQL Server中使用不同方法从其他表更新表数据的技术。包括使用JOIN方法、MERGE语句和子查询方法进行更新操作,以及如何通过索引优化性能。
In this article, we will learn different methods that are used to update the data in a table with the data of other tables. The “UPDATE from SELECT” query structure is the main technique for performing these updates.
在本文中,我们将学习用于与其他表的数据更新表中数据的不同方法。 “ 从SELECT更新 ”查询结构是执行这些更新的主要技术。
An UPDATE query is used to change an existing row or rows in the database. UPDATE queries can change all tables rows, or we can limit the update statement affects for the certain rows with the help of the WHERE clause. Mostly, we use constant values to change the data, such as the following structures.
UPDATE查询用于更改数据库中现有的一个或多个行。 UPDATE查询可以更改所有表行,或者可以借助WHERE子句来限制update语句对某些行的影响。 通常,我们使用常量值来更改数据,例如以下结构。
The full update statement is used to change the whole table data with the same value.
完整更新 语句用于更改具有相同值的整个表数据。
UPDATE table
SET col1 = constant_value1 , col2 = constant_value2 , colN = constant_valueN
The conditional update statement is used to change the data that satisfies the WHERE condition.
的 有条件的更新 语句用于更改满足WHERE条件的数据。
UPDATE table
SET col1 = constant_value1 , col2 = constant_value2 , colN = constant_valueN
WHERE col = val
However, for different scenarios, this constant value usage type cannot be enough for us, and we need to use other tables’ data in order to update our table. This type of update statements is a bit complicated than the usual structures. In the following sections, we will learn how to write this type of update query with different methods, but at first, we have to prepare our sample data. So let’s do this.
但是,对于不同的情况,此常量值的使用类型对我们来说还不够,因此我们需要使用其他表的数据来更新我们的表。 这种类型的更新语句比通常的结构有些复杂。 在以下各节中,我们将学习如何使用不同的方法编写这种类型的更新查询,但是首先,我们必须准备示例数据。 因此,让我们这样做。
准备样本数据 (Preparing the sample data)
With the help of the following query, we will create Persons and AddressList tables and populate them with some synthetic data. These two tables have a relationship through the PersonId column, meaning that, in these two tables, the PersonId column value represents the same person.
借助以下查询,我们将创建Persons和AddressList表,并使用一些合成数据填充它们。 这两个表通过PersonId列具有关系,这意味着在这两个表中, PersonId列值表示同一个人。
CREATE TABLE dbo.Persons
( PersonId INT
PRIMARY KEY IDENTITY(1, 1) NOT NULL,
PersonName VARCHAR(100) NULL,
PersonLastName VARCHAR(100) NULL,
PersonPostCode VARCHAR(100) NULL,
PersonCityName VARCHAR(100) NULL)
GO
CREATE TABLE AddressList(
[AddressId] [int] PRIMARY KEY IDENTITY(1,1) NOT NULL,
[PersonId] [int] NULL,
[PostCode] [varchar](100) NULL,
[City] [varchar](100) NULL)
GO
INSERT INTO Persons
(PersonName, PersonLastName )
VALUES
(N'Salvador', N'Williams'),
(N'Lawrence', N'Brown'),
( N'Gilbert', N'Jones'),
( N'Ernest', N'Smith'),
( N'Jorge', N'Johnson')
GO
INSERT INTO AddressList
(PersonId, PostCode, City)
VALUES
(1, N'07145', N'Philadelphia'),
(2, N'68443', N'New York'),
(3, N'50675', N'Phoenix'),
(4, N'96573', N'Chicago')
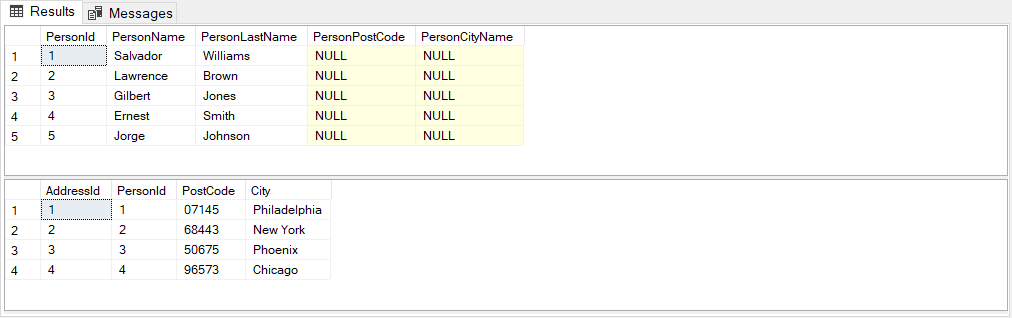
SELECT * FROM Persons
SELECT * FROM AddressList
从SELECT更新:Join方法 (UPDATE from SELECT: Join Method)
In this method, the table to be updated will be joined with the reference (secondary) table that contains new row values. So that, we can access the matched data of the reference table based on the specified join type. Lastly, the columns to be updated can be matched with referenced columns and the update process changes these column values.
在此方法中,要更新的表将与包含新行值的参考(辅助)表结合在一起。 这样,我们就可以基于指定的联接类型访问参考表的匹配数据。 最后,要更新的列可以与引用的列匹配,并且更新过程会更改这些列的值。
In the following example, we will update the PersonCityName and PersonPostCode columns data with the City and PostCode columns data of the AdressList table.
在下面的例子中,我们将更新与AdressList表的城市和邮编列数据PersonCityName和PersonPostCode列中的数据。
UPDATE Per
SET
Per.PersonCityName=Addr.City,
Per.PersonPostCode=Addr.PostCode
FROM Persons Per
INNER JOIN
AddressList Addr
ON Per.PersonId = Addr.PersonId
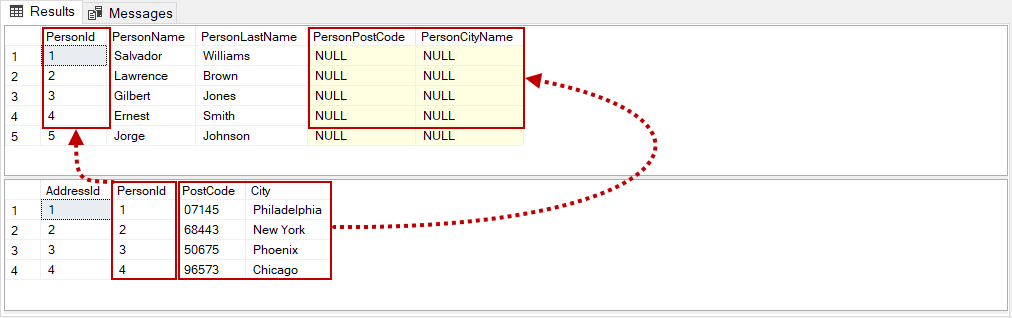
After the execution of the update from a select query the output of the Persons table will be as shown below;
从选择查询执行更新后,“ 人员”表的输出将如下所示;
SELECT * FROM Persons
Let’s try to understand the above code:
让我们尝试理解上面的代码:
We typed the table name, which will be updated after the UPDATE statement. After the SET keyword, we specified the column names to be updated, and also, we matched them with the referenced table columns. After the FROM clause, we retyped the table name, which will be updated. After the INNER JOIN clause, we specified the referenced table and joined it to the table to be updated. In addition to this, we can specify a WHERE clause and filter any columns of the referenced or updated table. We can also rewrite the query by using aliases for tables.
我们输入了表名,该表名将在UPDATE语句后更新 。 在SET关键字之后,我们指定了要更新的列名,并且还将它们与引用的表列匹配。 在FROM子句之后,我们重新键入了表名,它将被更新。 在INNER JOIN子句之后,我们指定了被引用的表并将其联接到要更新的表。 除此之外,我们可以指定WHERE子句并过滤引用或更新的表的任何列。 我们还可以通过使用表别名来重写查询。
UPDATE Per
SET
Per.PersonCityName=Addr.City,
Per.PersonPostCode=Addr.PostCode
FROM Persons Per
INNER JOIN
AddressList Addr
ON Per.PersonId = Addr.PersonId
性能提示: (Performance Tip:)
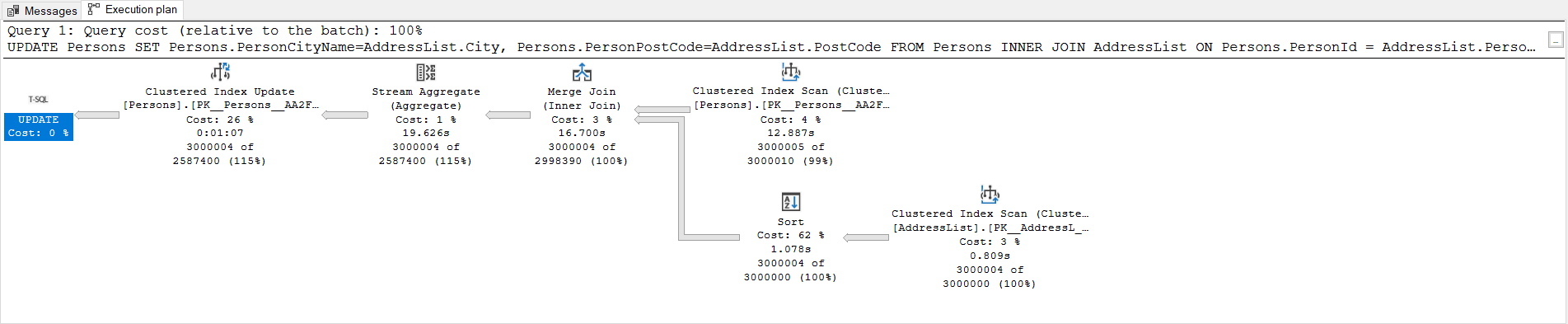
Indexes are very helpful database objects to improve query performance in SQL Server. Particularly, if we are working on the performance of the update query, we should take into account of this probability. The following execution plan illustrates an execution plan of the previous query. The only difference is that this query updated the 3.000.000 rows of the Persons table. This query was completed within 68 seconds.
索引对于提高SQL Server中的查询性能非常有用。 特别是,如果我们正在努力执行更新查询的性能,则应考虑这种可能性。 以下执行计划说明了先前查询的执行计划。 唯一的区别是此查询更新了Persons表的3.000.000行。 该查询在68秒内完成。
We added a non-clustered index on Persons table before to update and the added index involves the PersonCityName and PersonPostCode columns as the index key.
我们在更新之前在Persons表上添加了非聚集索引,并且添加的索引涉及PersonCityName和PersonPostCode列作为索引键。
The following execution plan is demonstrating an execution plan of the same query, but this query was completed within 130 seconds because of the added index, unlike the first one.
以下执行计划说明了同一查询的执行计划,但是由于添加了索引,因此该查询在130秒内完成,这与第一个查询不同。
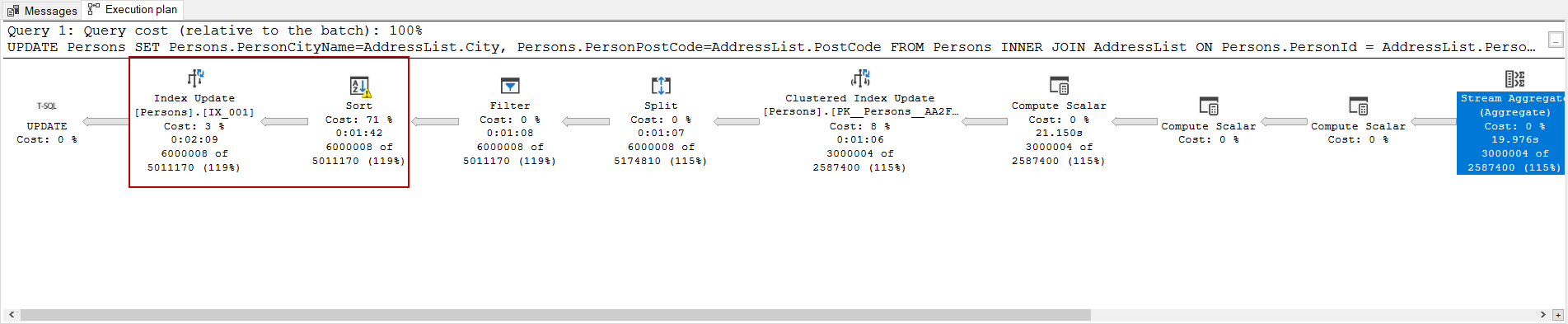
The Index Update and Sort operators consume 74% cost of the execution plan. We have seen this obvious performance difference between the same query because of index usage on the updated columns. As a result, if the updated columns are being used by the indexes, like this, for example, the query performance might be affected negatively. In particular, we should consider this problem if we will update a large number of rows. To overcome this issue, we can disable or remove the index before executing the update query.
索引更新和排序运算符消耗执行计划的74%的成本。 我们已经看到,由于更新列的索引使用情况,同一查询之间存在明显的性能差异。 结果,例如,如果索引正在使用更新的列,则这样会对查询性能产生负面影响。 特别是,如果我们将更新大量行,则应考虑此问题。 为了解决这个问题,我们可以在执行更新查询之前禁用或删除索引。
On the other hand, a warning sign is seen on the Sort operator, and it indicates something does not go well for this operator. When we hover the mouse over this operator, we can see the warning details.
另一方面,在“ 排序” 运算符上看到一个警告标志,它表示此运算符无法正常运行。 当我们将鼠标悬停在该运算符上时,我们可以看到警告详细信息。
During the execution of the query, the query optimizer calculates a required memory consumption for the query based on the estimated row numbers and row size. However, this consumption estimation can be wrong for a variety of reasons, and if the query requires more memory than the estimation, it uses the tempdb data. This mechanism is called a tempdb spill and causes performance loss. The reason for this: the memory always faster than the tempdb database because the tempdb database uses the disk resources.
在执行查询期间,查询优化器会根据估算的行号和行大小为查询计算所需的内存消耗。 但是,由于多种原因,此消耗量估计可能是错误的,并且如果查询所需的内存比估计量更多,则它将使用tempdb数据。 这种机制称为tempdb溢出,会导致性能损失。 这样做的原因:内存总是比tempdb数据库快,因为tempdb数据库使用磁盘资源。
You can see this SQL Server 2017: SQL Sort, Spill, Memory and Adaptive Memory Grant Feedback fantastic article for more details about the tempdb spill issue.
您可以查看以下SQL Server 2017:SQL排序,溢出,内存和自适应内存授予反馈,该文章很棒,以了解有关tempdb溢出问题的更多信息。
从SELECT更新:MERGE语句
(UPDATE from SELECT: The MERGE statement
)
The MERGE statement is used to manipulate (INSERT, UPDATE, DELETE) a target table by referencing a source table for the matched and unmatched rows. The MERGE statement can be very useful for synchronizing the table from any source table.
MERGE语句用于通过引用匹配和不匹配行的源表来操作(INSERT,UPDATE,DELETE)目标表。 MERGE语句对于同步任何源表中的表非常有用。
Now, if we go back to our position, the MERGE statement can be used as an alternative method for updating data in a table with those in another table. In this method, the reference table can be thought of as a source table and the target table will be the table to be updated. The following query can be an example of this usage method.
现在,如果我们回到原来的位置,则可以将MERGE语句用作另一种方法来更新一个表中的数据。 在这种方法中,可以将参考表视为源表,而将目标表视为要更新的表。 以下查询可以是此使用方法的示例。
MERGE Persons AS Per
USING(SELECT * FROM AddressList) AS Addr
ON Addr.PersonID=Per.PersonID
WHEN MATCHED THEN
UPDATE SET
Per.PersonPostCode=Addr.PostCode ,
Per.PersonCityName = Addr.City;
SELECT * FROM Persons
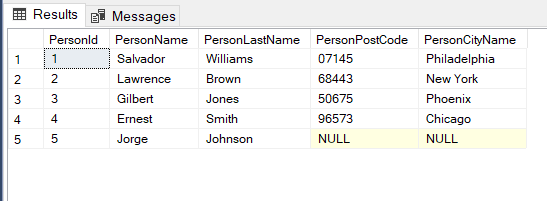
Now let’s tackle the previous update from a select query line by line.
现在,让我们逐行处理选择查询中的先前更新。
MERGE Persons AS Per
We have typed the Persons table after the MERGE statement because it is our target table, which we want to update, and we gave Per alias to it in order to use the rest of the query.
我们在MERGE语句后键入了Persons表,因为它是我们要更新的目标表,并且为它赋予Per别名以使用其余的查询。
USING(SELECT * FROM AddressList) AS Addr
After the USING statement, we have specified the source table.
在USING语句之后,我们指定了源表。
ON Addr.PersonID=Per.PersonID
With the help of this syntax, the join condition is defined between the target and source table.
借助此语法,可以在目标表和源表之间定义连接条件。
WHEN MATCHED THEN
UPDATE SET Per.PersonPostCode=Addr.PostCode;
In this last line of the query, we chose the manipulation method for the matched rows. Individually for this query, we have selected the UPDATE method for the matched rows of the target table. Finally, we added the semicolon (;) sign because the MERGE statements must end with the semicolon signs.
在查询的最后一行,我们为匹配的行选择了操作方法。 对于该查询,我们单独为目标表的匹配行选择了UPDATE方法。 最后,我们添加了分号(;),因为MERGE语句必须以分号结尾。
从SELECT更新:子查询方法 (UPDATE from SELECT: Subquery Method)
A subquery is an interior query that can be used inside of the DML (SELECT, INSERT, UPDATE and DELETE) statements. The major characteristic of the subquery is, they can only be executed with the external query.
子查询是一种内部查询,可以在DML(SELECT,INSERT,UPDATE和DELETE)语句中使用。 子查询的主要特征是,它们只能与外部查询一起执行。
The subquery method is the very basic and easy method to update existing data from other tables’ data. The noticeable difference in this method is, it might be a convenient way to update one column for the tables that have a small number of the rows. Now we will execute the following query and then will analyze it.
子查询方法是从其他表的数据更新现有数据的非常基本且简便的方法。 此方法的显着差异是,它可能是一种方便的方法,用于为行数较少的表更新一列。 现在,我们将执行以下查询,然后对其进行分析。
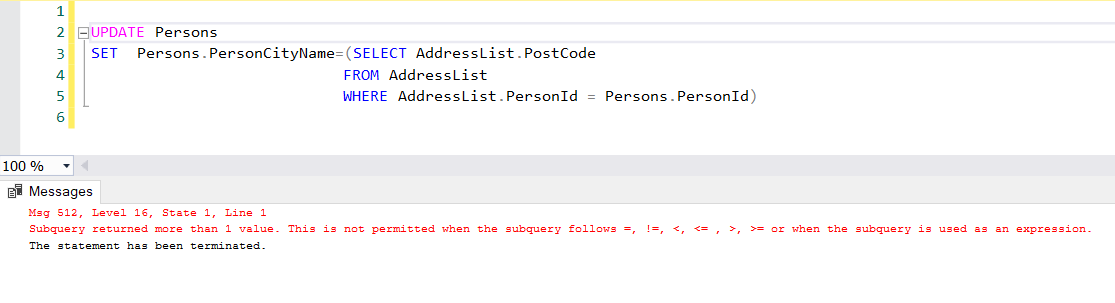
UPDATE Persons
SET Persons.PersonCityName=(SELECT AddressList.PostCode
FROM AddressList
WHERE AddressList.PersonId = Persons.PersonId)
After the execution of the update from a select statement the output of the table will be as below;
从select语句执行更新后,表的输出将如下所示;
SELECT * FROM Persons
As we can see, the PersonCityName column data of the Persons table have been updated with the City column data of the AddressList table for the matched records for the PersonId column. Regarding this method, we should underline the following significant points.
正如我们所看到的, 个人表的PersonCityName列数据已更新与匹配的记录,将personId列AddressList中表的City列数据。 关于这种方法,我们应该强调以下几点。
- If the subquery could not find any matched row, the updated value will be changed to NULL 如果子查询找不到任何匹配的行,则更新后的值将更改为NULL
If the subquery finds more than one matched row, the update query will return an error, as shown below:
如果子查询找到多个匹配行,则更新查询将返回错误,如下所示:
- Many times the subquery update method may not offer satisfying performance 很多时候,子查询更新方法可能无法提供令人满意的性能
结论 (Conclusion)
In this article, we learned to update the data in a table with the data where they are contained in other tables. The query structure, “UPDATE from SELECT” can be used to perform this type of data update scenario. Also, we can use alternative MERGE statement and subquery methods.
在本文中,我们学习了使用其他表中包含的数据来更新表中的数据。 查询结构“ SELECT的UPDATE ”可用于执行这种类型的数据更新方案。 同样,我们可以使用替代的MERGE语句和子查询方法。
翻译自: https://www.sqlshack.com/how-to-update-from-a-select-statement-in-sql-server/

















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









