





 SSAS多维数据集的分区策略能带来显著的性能提升,包括并行处理提高吞吐量,减少处理时间,以及通过分区消除降低查询响应时间。手动设置分区切片有助于优化查询体验。通过对包含较旧数据的分区存储在低成本磁盘上,可以节省成本。
SSAS多维数据集的分区策略能带来显著的性能提升,包括并行处理提高吞吐量,减少处理时间,以及通过分区消除降低查询响应时间。手动设置分区切片有助于优化查询体验。通过对包含较旧数据的分区存储在低成本磁盘上,可以节省成本。
ssas 分区 设置
介绍 (Introduction)
In the article How to partition an SSAS Cube in Analysis Services Multidimensional, we explained how you can partition your measure groups in an SSAS cube. In this article, we’ll look at the expected benefits of the partition strategy. Time to reap the benefits of our hard work.
在“ 如何在Analysis Services多维中对SSAS多维数据集进行分区”一文中 ,我们说明了如何在SSAS多维数据集中对度量值组进行分区。 在本文中,我们将研究分区策略的预期收益。 是时候从我们的辛勤工作中受益。
分区福利 (Partition Benefits)
The first benefit becomes clear after we’ve deployed the cube, during processing:
在处理过程中部署多维数据集后,第一个好处显而易见:
All the partitions can be read and processed in parallel, which maximizes throughput (especially if you saved them on separate disks) and can reduce processing time of your measure group. The amount of processing reduced depends on the number of processors SSAS has available.
所有分区都可以并行读取和处理,这可以最大程度地提高吞吐量(尤其是如果将它们保存在单独的磁盘上),并且可以减少度量值组的处理时间。 减少的处理量取决于SSAS可用的处理器数量。
There are other benefits related to processing:
处理还有其他好处:
- Full Process on them. For example, if you partition on the time dimension and you only add new rows (you don’t update older rows), you only need to do a Full Process on your latest partition. All the other partitions need a 完全处理 。 例如,如果您在时间维度上进行分区,而仅添加新行(不更新较旧的行),则只需在最新分区上执行“完整过程”。 所有其他分区都需要一个Process Index to keep the indexes and aggregates up to date with the latest changes in the dimensions. This can also significantly reduce processing time, because you don’t need to read data from disk for all the older partitions. Keep in mind if you do a Full Process on a dimension, partitions from associated measure groups will be unprocessed. For this set-up to work, the dimensions must all be processed with Process Index来保持索引并随着维度的最新变化而更新聚合。 这也可以大大减少处理时间,因为您不需要从磁盘读取所有较旧分区的数据。 请记住,如果您在维度上执行“完全处理”,则关联度量值组中的分区将不会被处理。 为了使此设置生效,必须使用Process Update. Process Update处理所有尺寸。
- You can choose to store older partitions – which are less accessed – using ROLAP and your most recent, frequently accessed partitions using MOLAP. In that case, you only need to process your most recent partitions. There is a performance hit for older partitions, but since they are read less often this might be acceptable. 您可以选择使用ROLAP存储较旧的分区(访问较少的分区),以及使用MOLAP存储最近的,经常访问的分区。 在这种情况下,您只需要处理最新的分区。 较旧的分区会降低性能,但是由于读取频率较低,因此这是可以接受的。
You can also store your older partitions on cheaper, less faster disks and your most recent partitions on more expensive faster disks (such as SSDs). Processing won’t benefit from this, but it might save you costs on expensive disks if you have a very large cube.
您还可以将较旧的分区存储在较便宜,速度较慢的磁盘上,而将最新的分区存储在较昂贵的较快磁盘(例如SSD)上。 处理将不会从中受益,但是如果您拥有很大的多维数据集,则可以节省昂贵磁盘上的成本。
One of the most important benefits however is not related to processing time, but to query performance. When you have defined partitioning and your MDX query only select data from a certain partition, all the other partitions won’t be read. This can significantly reduce your query response time. This is called partition elimination. Let’s look at an example.
但是,最重要的好处之一与处理时间无关,而与查询性能有关。 当您定义了分区并且MDX查询仅从某个分区中选择数据时,将不会读取所有其他分区。 这样可以大大减少查询响应时间。 这称为分区消除 。 让我们来看一个例子。
First, we start up profiler so we can monitor the queries sent to the cube, but also find out which partitions are being read from disk. Create a new trace.
首先,我们启动探查器,以便我们可以监视发送到多维数据集的查询,还可以确定正在从磁盘读取哪些分区。 创建一个新的跟踪。
Connect to your SSAS instance.
连接到您的SSAS实例。
In the Events Selection tab, only keep the events from the sections Progress Reports, Queries Events and Query Subcube selected.
在“事件选择”选项卡中,仅保留“ 进度报告” ,“ 查询事件”和“ 查询子多维数据集 ”部分中的事件。
Click Run to start the trace. In Management Studio, we are going to browse the cube to generate some MDX queries.
单击运行以开始跟踪。 在Management Studio中,我们将浏览多维数据集以生成一些MDX查询。
Let’s drag in the Calendar Hierarchy and the Total Excluding Tax measure.
让我们拖入“日历层次结构”和“总税额”度量。
When we take a look at the trace, we can see all the partitions were read:
当我们查看跟踪时,我们可以看到所有分区均已读取:
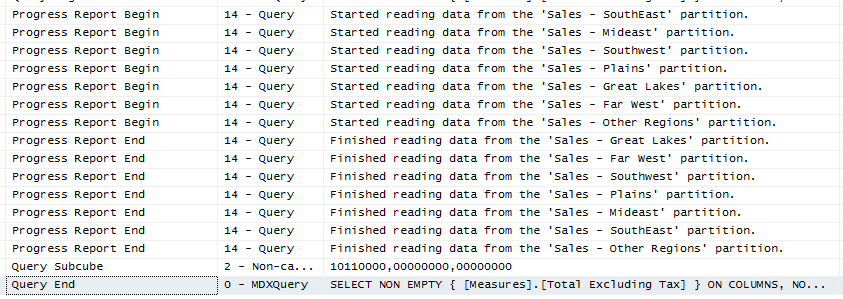
Even though there’s no partition elimination for this particular query, it can already benefit from the parallel execution on the different partitions.
即使没有针对该特定查询的分区消除,它也已经可以从对不同分区的并行执行中受益。
Let’s create a filter using the Sales Territory attribute.
让我们使用Sales Territory属性创建一个过滤器。
When we look at the Profiler trace, we can now see only one single partition was read:
当我们查看Profiler跟踪时,现在可以看到仅读取了一个分区:

If we would have a very large cube with data evenly distributed over all our 7 partitions, the cost of reading data would be 1/7th of the original query!
如果我们有均匀的分布在我们的7个分区的数据非常大的立方体,读取数据的成本是1/7 个原始查询!
分区片 (Partition Slices)
But how does SSAS know which partitions to eliminate? This is done using the partition slice, a property of the partition.
但是SSAS如何知道要消除的分区? 这是通过使用partition slice ( 分区的属性)完成的。
You can set this property manually. For the Far West partition, this would be [City].[Sales Territory].&[Far West]. You can drag and drop the appropriate member to the expression editor:
您可以手动设置此属性。 对于远西分区,这将是[City]。[Sales Territory]。&[Far West]。 您可以将适当的成员拖放到表达式编辑器中:
Now SSAS knows the partition only includes data for this particular Sales Territory. For MOLAP storage, SSAS automatically detects which data is loaded into a partition and it will set the slice accordingly (internally, you won’t see a change in the slice property). However, this is not 100% waterproof. For optimal configuration, it’s recommended to set the slices manually.
现在,SSAS知道分区仅包含此特定销售地区的数据。 对于MOLAP存储,SSAS自动检测哪些数据已加载到分区中,并且它将相应地设置片(在内部,您不会在slice属性中看到更改)。 但是,这不是100%防水的。 为了获得最佳配置,建议手动设置切片。
It might be possible for example that SSAS can’t detect which slice to set for the “Others” partition, since it consists of multiple members. In that case, SSAS might set the slice to a higher level of the hierarchy – the ALL member in this case – instead of using OR to join the members together in one slice. This means the partition might be scanned for queries, while the data wasn’t needed after all.
例如,SSAS可能无法检测要为“其他”分区设置的切片,因为它由多个成员组成。 在这种情况下,SSAS可以将切片设置为更高的层次结构(在这种情况下为ALL成员),而不是使用OR将成员合并到一个切片中。 这意味着可以扫描分区以查询查询,而根本不需要数据。
Let’s illustrate with another example: if you have a slice on Q1 and Q2 of 2016, SSAS might create the slice on the lowest common member: the year. If you query the first quarter, a whole year of data might be read.
让我们用另一个示例进行说明:如果您在2016年第一季度和第二季度有一个切片,则SSAS可能会在最低的普通成员上创建切片:年份。 如果查询第一季度,则可能会读取整整一年的数据。
For the “Others” partition, we can set the slice using a set expression:
对于“其他”分区,我们可以使用set表达式设置切片:
We can verify it works when we set the filter to Rocky Mountain and External:
当我们将过滤器设置为落基山和外部时,我们可以验证它是否有效:

There are several reasons why partition elimination might not always work as you’d expect. Many-to-many relationships might for example prevent that partitions are eliminated if the partitions are defined on the intermediate dimension. Chris Webb explains this in the blog post Many-to-Many Relationships and Partition Slices.
有几个原因导致分区消除可能无法始终如您所愿地工作。 如果在中间维度上定义了分区,则多对多关系可能会阻止删除分区。 Chris Webb在博客文章“ 多对多关系和分区切片”中对此进行了解释。
Another issue might arise if you use an attribute that has multiple columns as its key attribute. Suppose you have a YearMonth attribute, where the key columns are defined by a Year attribute and a Month attribute. The order in which you specify the key columns might have an impact on how internally the data is structured. If you specify the month first and then the year, the data might be structured as follows:
如果您使用具有多个列的属性作为键属性,则可能会出现另一个问题。 假设您具有YearMonth属性,其中的键列由Year属性和Month属性定义。 指定键列的顺序可能会影响数据的内部结构。 如果首先指定月份,然后指定年份,则数据的结构可能如下:
Month 1 Year 1, Month 1 Year 2, Month 1 Year 3, Month 2 Year 1, Month 2 Year 2 …
第1个月的第1年,第1个月的第2年,第1个月的第3年,第2个月的第1年,第2个月的第2年……
In reality, we would slice first on Year and then on Month. You can find more information on this type of behavior in the Reference Links section.
实际上,我们将首先在Year上进行切片,然后在Month上进行切片。 您可以在“参考链接”部分中找到有关此类行为的更多信息。
结论 (Conclusion)
There are many clear-cut benefits of partitioning measure groups:
划分度量值组有许多明显的好处:
- Faster processing times due to parallel processing of the partitions 由于分区的并行处理,处理时间更快
- You can also process select partitions containing only recent data, further reducing processing time. 您还可以处理仅包含最新数据的选定分区,从而进一步减少了处理时间。
- You can reduce costs by placing partitions with older data on slower and cheaper disks. You could also store the old partitions using the ROLAP storage mode. 您可以通过将具有较旧数据的分区放置在速度较慢且价格较低的磁盘上来降低成本。 您也可以使用ROLAP存储模式存储旧分区。
- Due to partition elimination, query response time can significantly be reduced if only a small subset of the partitions need to be read. Set the partition slice manually for an optimal experience. 由于消除了分区,如果只需要读取分区的一小部分,则可以显着减少查询响应时间。 手动设置分区片以获得最佳体验。
The previous article in this series:
本系列的上一篇文章:
- How to partition an SSAS Cube in Analysis Services Multidimensional如何在Analysis Services多维中对SSAS多维数据集进行分区
The next article in this series:
本系列的下一篇文章:
- How to optimize the dimension security performance using partitioning in SSAS Multidimensional如何在SSAS多维中使用分区来优化维度安全性能
翻译自: https://www.sqlshack.com/benefits-of-partitioning-an-ssas-multidimensional-cube/
ssas 分区 设置















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









