





清理搜狗输入法
介绍 (Introduction)
In any application, we will likely have some need to control input data, either altering, filtering or otherwise changing text to fit our application’s needs.
在任何应用程序中,我们可能都需要控制输入数据,包括更改,过滤或以其他方式更改文本以满足我们的应用程序需求。
Sometimes these needs arise from a desire to remove characters or text that are logically not compatible with an application. For example, a name, phone number, or ID number might need to be validated for correctness, or updated to remove or alert on invalid characters.
有时,这些需求是由于希望删除逻辑上与应用程序不兼容的字符或文本而产生的。 例如,可能需要验证名称,电话号码或ID号的正确性,或者更新名称,电话号码或ID号以删除或警告无效字符。
Security is also a concern in that we need to verify any freeform text to ensure that is properly delimited to ensure we cannot be the victim of SQL injection, regex hacking, or any other undesired string manipulation by the end user.
安全性也是一个问题,因为我们需要验证任何自由格式的文本以确保正确定界以确保我们不会成为SQL注入,正则表达式黑客或最终用户进行任何其他不希望的字符串操作的受害者。
输入修改:我们为什么要关心? (Input Modification: Why Do We Care?)
Most applications we build will perform some level of input validation, whether it be to remove unwanted characters, check for SQL injection attempts, or parse inputs into a specific format. Despite this, we still should consider any text input from uncontrolled sources and what we may or may not want to be stored from it. The following are worthwhile to check:
我们构建的大多数应用程序都将执行某种级别的输入验证,无论是删除不需要的字符,检查SQL注入尝试还是将输入解析为特定格式。 尽管如此,我们仍然应该考虑来自不受控制的来源的任何文本输入,以及我们可能会或可能不想从中存储的内容。 以下内容值得检查:
- Is NULL allowed? If not, ensure that stored procedure parameters don’t provide a default and that a specific logic path is taken when a NULL is explicitly provided for a field that should always be populated with a meaningful value. 是否允许使用NULL? 如果不是,请确保存储过程参数不提供默认值,并且当为始终应填充有意义值的字段显式提供NULL时,采用特定的逻辑路径。
- Is a blank or empty string allowed? If not, check for it and act similarly to the NULL scenario above. 是否允许使用空白或空字符串? 如果不是,请检查它,然后采取与上述NULL情形类似的操作。
- Are there any special symbols, formatting characters, extended ASCII, or Unicode characters that we want to disallow from our input? 我们是否要从输入中禁止使用特殊符号,格式字符,扩展ASCII或Unicode字符?
- Do we want to perform validation against how our input is delimited, in order to prevent SQL injection attacks? 我们是否要针对输入的分隔方式执行验证,以防止SQL注入攻击?
- Do we wish to control regex and string manipulation character combinations, in order to prevent the user from accessing data they shouldn’t normally be able to view? 我们是否希望控制正则表达式和字符串操作字符的组合,以防止用户访问通常不应该查看的数据?
- Is the target data intended to fit a specific format, such as credit card number, ID number, phone number, or other specific data type that should only allow certain characters, a specific length, or follow other important rules? 目标数据是否打算适合特定格式,例如信用卡号,ID号,电话号码或其他只能允许某些字符,特定长度或遵循其他重要规则的特定数据类型?
If the answer to all of these questions is always “No”, then we are free to move on and not worry about input cleansing. It would be both unusual and worrisome though, if in an application, we had no reason to validate any aspect of inputs for any security or data integrity purpose. Given this almost constant need, we can begin tackling each of these problems one-by-one. In doing so, we’ll discuss a variety of different solutions that will allow for methodical, simple, efficient, and/or customizable ways of validating, cleansing, and modifying input data.
如果所有这些问题的答案始终都是“否”,那么我们可以继续前进,而不必担心输入清理。 但是,如果在应用程序中,我们没有理由出于任何安全性或数据完整性目的来验证输入的任何方面,那将是异常且令人担忧的。 鉴于这种几乎恒定的需求,我们可以开始一个一个地解决这些问题。 为此,我们将讨论各种不同的解决方案,这些解决方案将允许采用有条理,简单,有效和/或可自定义的方式来验证,清除和修改输入数据。
NULL和空输入字符串 (NULL and Empty Input Strings)
This first example is simple, and a fun way to move into the topic of input validation. The most common unwanted input for a parameter is going to be a NULL or empty string. Consider the following (very simple) stored procedure:
第一个示例很简单,并且是进入输入验证主题的有趣方式。 参数最常见的不需要输入将是NULL或空字符串。 考虑以下(非常简单)的存储过程:
CREATE PROCEDURE dbo.Null_Test
@Int_Parameter INT
AS
BEGIN
SELECT @Int_Parameter;
END
A single parameter is passed in, and it is not given a default value. If we execute it, the value is returned. The following TSQL returns the input value, 17:
传递了单个参数,并且未给其提供默认值。 如果执行它,则返回值。 以下TSQL返回输入值17:
EXEC dbo.Null_Test @Int_Parameter = 17;
Supplying no parameter yields an error:
不提供参数会产生错误:
EXEC dbo.Null_Test;
Msg 201, Level 16, State 4, Procedure Null_Test, Line 0 [Batch Start Line 26]
消息201,级别16,状态4,过程Null_Test,第0行[批处理开始第26行]
Procedure or function ‘Null_Test’ expects parameter ‘@Int_Parameter’, which was not supplied.
过程或函数“ Null_Test”需要未提供的参数“ @Int_Parameter”。
Despite not providing a default value, it is possible to pass NULL in as the parameter value. Having no default means that a value must be passed in, but it can be anything, even NULL. If NULL is not valid and we want to avoid it from being entered, you can manage it like this:
尽管未提供默认值,也可以将NULL作为参数值传入。 没有默认值意味着必须传递一个值,但是它可以是任何值,甚至是NULL。 如果NULL无效,并且我们希望避免输入NULL,则可以按以下方式进行管理:
ALTER PROCEDURE dbo.Null_Test
@Int_Parameter INT
AS
BEGIN
IF @Int_Parameter IS NULL
BEGIN
SELECT 'NULL is not valid for @Int_Parameter';
RETURN;
END
SELECT @Int_Parameter;
END
Now when you try to execute the stored procedure with NULL, the results are as follows:
现在,当您尝试使用NULL执行存储过程时,结果如下:
EXEC dbo.Null_Test @Int_Parameter = NULL;
NULL is not valid for @Int_Parameter
The SELECT statement can be replaced with a RAISERROR, TRY…CATCH…THROW, logging, or any other TSQL you can think of, including assigning a specific value, if needed. RETURN ensures that stored procedure execution ends immediately. While not obvious, RAISERROR does not immediately halt stored procedure execution for all severity levels. If you want a stored procedure to end at a given point, then RETURN will manage that for you.
SELECT语句可以替换为RAISERROR,TRY…CATCH…THROW,日志记录或您可以想到的任何其他TSQL,包括在需要时分配特定值。 RETURN确保存储过程的执行立即结束。 尽管不明显,但是RAISERROR不会立即停止所有严重性级别的存储过程的执行。 如果您希望存储过程在给定点结束,那么RETURN将为您管理该过程。
We can perform very similar logic for empty strings, specific invalid values, or other any other undesirable input conditions that your business demands of you. Simply change the IS NOT NULL check to include additional checks as needed.
对于空字符串,特定的无效值或您的业务需要的其他任何不希望有的输入条件,我们可以执行非常相似的逻辑。 只需更改IS NOT NULL检查,以根据需要包含其他检查。
删除/替换不需要的字符 (Removing/Replacing Unwanted Characters)
There are a multitude of ways to alter an input string in order to remove, replace, or otherwise detect unwanted characters or string patterns. For very simple use-cases, simple solutions will suffice, but for more complex examples, the quick & dirty solutions can become cumbersome, inefficient, or error-prone.
为了删除,替换或以其他方式检测不需要的字符或字符串模式,有多种方法可以更改输入字符串。 对于非常简单的用例,简单的解决方案就足够了,但是对于更复杂的示例,快速而肮脏的解决方案可能变得笨拙,低效或容易出错。
In general, it’s important for applications to manage as much input-cleansing as possible. We can confirm and validate text in the database (or explicitly not care and leave it be), but it’s important to have a full understanding or what is consuming our data and the format that is expected.
通常,对应用程序管理尽可能多的输入清理非常重要。 我们可以确认和验证数据库中的文本(或明确地不在乎并将其保留),但是重要的是要有充分的了解,或者什么正在消耗我们的数据以及预期的格式。
基本的字符串操作 (Basic String Manipulation)
The following is a very basic attempt at removing unwanted characters from an input parameter:
以下是从输入参数中删除不需要的字符的非常基本的尝试:
CREATE PROCEDURE dbo.My_Stored_Procedure
@String_Parameter VARCHAR(289)
AS
BEGIN
SELECT @String_Parameter = REPLACE(REPLACE(REPLACE(@String_Parameter, '@', ''), '#', ''), '%', '');
SELECT @String_Parameter;
END
This stored procedure accepts a single string input, which is run through a series of REPLACE operations in order to remove a handful of unwanted characters (replacing them with empty strings). This process is effective when a small number of targeted characters is defined, but gets messy quickly if there is a large number of characters to strip out of the string. In addition, not all characters are easy to copy and paste into a command. In general, it’s always advisable to use the ASCII or UNICODE numeric identifier for characters as these are static and will not be affected by fonts, keyboard input, or any other variances in text input, escape characters, or other potential interferences:
此存储过程接受单个字符串输入,该字符串输入通过一系列REPLACE操作运行,以删除少数不需要的字符(将它们替换为空字符串)。 当定义了少量目标字符时,此过程有效,但如果要从字符串中去除大量字符,该过程将很快变得混乱。 此外,并非所有字符都易于复制和粘贴到命令中。 通常,始终建议对字符使用ASCII或UNICODE数字标识符,因为这些字符是静态的,并且不受字体,键盘输入或文本输入中任何其他变化,转义字符或其他潜在干扰的影响:
ALTER PROCEDURE dbo.My_Stored_Procedure
@String_Parameter VARCHAR(289)
AS
BEGIN
SELECT @String_Parameter = REPLACE(REPLACE(REPLACE(@String_Parameter, CHAR(64), ''), CHAR(35), ''), CHAR(37), '');
SELECT @String_Parameter;
END
The only difference is to replace the apostrophe-delimited characters with the CHAR representation of each character’s ASCII value. Here is an example execution using either method:
唯一的区别是用每个字符的ASCII值的CHAR表示形式替换以撇号分隔的字符。 这是使用这两种方法的示例执行:
EXEC dbo.My_Stored_Procedure 'Test String!@#$%';
Test String!$
测试字符串!
Note that the “@”, “#”, and “%” were all removed, and all other characters left as-is. Using SUBSTRING, REPLACE, or other string-manipulation functions on specific characters will become both messy and difficult to maintain/troubleshoot as our character lists get more complex. Consider the following example, which attempts to remove every non-alphanumeric character I could find on my keyboard:
请注意,“ @”,“#”和“%”均已删除,所有其他字符保持原样。 在特定字符上使用SUBSTRING,REPLACE或其他字符串操作功能将变得混乱,并且由于我们的字符列表变得更加复杂,因此难以维护/排除故障。 考虑以下示例,该示例尝试删除我在键盘上可以找到的每个非字母数字字符:
ALTER PROCEDURE dbo.My_Stored_Procedure
@String_Parameter VARCHAR(289)
AS
BEGIN
SELECT @String_Parameter = REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(@String_Parameter, '@', ''), '#', ''), '%', ''), '!', ''), '$', ''), '^', ''), '&', ''), '*', ''), '(', ''), ')', ''), '_', ''), '-', ''), '=', ''), '+', ''), '[', ''), ']', ''), '{', ''), '}', ''), '\', ''), '|', ''), ';', ''), ':', ''), '''', ''), '"', ''), ',', ''), '<', ''), '.', ''), '>', ''), '/', ''), '?', ''), '`', ''), '~', ''), ' ', '');
SELECT @String_Parameter;
END
Yes, this works, and no, it’s not a great idea 🙂 Aside from being exceedingly messy, I omitted many special characters that are not shown explicitly on my keyboard, such as tab, newline, accents, printer feed characters, and more. In addition, if we were working with UNICODE input, there would be a very long list of foreign characters that are definitely not represented on my keyboard.
是的,这可行,不是,这不是一个好主意🙂除了过于混乱之外,我还省略了许多键盘上未明确显示的特殊字符,例如制表符,换行符,重音符号,打印机提要字符等。 另外,如果我们使用UNICODE输入,则一长串的外国字符肯定不会在我的键盘上显示。
For small, controlled input scenarios in which we are familiar with the data and know exactly what we want to manipulate, this is a quick & easy way to get results, but be cautious when applications get bigger and more complex. Also, if a script is to be used with UNICODE input and/or internationalized inputs, then the list of potentially undesired characters may make the silly-looking stored procedure above even sillier.
对于我们熟悉数据并确切知道我们要操纵什么的小型受控输入场景,这是获取结果的快速简便方法,但是在应用程序变得越来越大和越来越复杂时要格外小心。 同样,如果脚本要与UNICODE输入和/或国际化输入一起使用,则潜在不需要的字符列表可能会使上面看起来很傻的存储过程更加愚蠢。
正则表达式和TSQL (RegEx & TSQL)
In lieu of not wanting to implement an endless string of character replacements, we can consider solutions that evaluate a string in its entirety. RegEx is a simple way to choose a string pattern, evaluate a string, and return a cleansed version:
代替不希望实现无穷无尽的字符串替换,我们可以考虑对字符串进行整体评估的解决方案。 RegEx是选择字符串模式,评估字符串并返回净化版本的简单方法:
CREATE FUNCTION dbo.Remove_Non_Alphanumeric
(@String_Parameter VARCHAR(289))
RETURNS VARCHAR(289)
AS
BEGIN
DECLARE @Alphanumeric_Characters VARCHAR(289) = '%[^A-Z^a-z^0-9]%';
WHILE PATINDEX(@Alphanumeric_Characters, @String_Parameter) > 0
BEGIN
SELECT @String_Parameter = STUFF(@String_Parameter, PATINDEX(@Alphanumeric_Characters, @String_Parameter), 1, '');
END
RETURN @String_Parameter;
END
In this function, we define a set of characters that we want to keep, composed of all capital letters, lowercase letters, and numbers. We then iterate through each invalid character, replacing it with an empty string, until no more exist. We can test this with our previous input string:
在此函数中,我们定义了要保留的一组字符,由所有大写字母,小写字母和数字组成。 然后,我们遍历每个无效字符,将其替换为空字符串,直到不再存在。 我们可以使用之前的输入字符串进行测试:
SELECT dbo.Remove_Non_Alphanumeric('Test String!@#$%');
TestString
测试字符串
The output has the space, as well as five trailing characters removed. For good measure, we can test this function against a more complex string:
输出中有空格,并删除了五个尾随字符。 为了更好地衡量,我们可以针对更复杂的字符串测试此函数:
SELECT dbo.Remove_Non_Alphanumeric('Te s((t @#*&)@#S{]''>t r
ing!@#$%');
Despite being a mess, the results are the same as before:
尽管一团糟,但结果与以前相同:
TestString
测试字符串
This is a great method for string-cleansing when our output is intended to be straight-forward. Saving only alpha-numeric characters is easy, and the RegEx to do so is not difficult to read or understand. It’s certainly simpler than having dozens of REPLACE strung together. This approach is iterative, but it’s executed over a scalar variable, meaning that performance won’t be bad. If the function were used as part of a WHERE clause, JOIN, or other table access logic, the results could be table scans. It’s always recommended to transform input first, before applying to any direct table access.
当我们的输出要简单明了时,这是清理字符串的好方法。 仅保存字母数字字符很容易,而RegEx这样做并不难于阅读或理解。 当然,这比将数十个REPLACE串在一起要简单得多。 这种方法是迭代的,但是它是在标量变量上执行的,这意味着性能不会很差。 如果该函数用作WHERE子句,JOIN或其他表访问逻辑的一部分,则结果可能是表扫描。 始终建议先转换输入,然后再应用到任何直接表访问。
Where RegEx begins to fail is when we have more complex string manipulation needs. Let’s say we are accepting phone number inputs and also want to retain a variety of special characters, such as parenthesis, dashes, and pound signs, but also wanted to remove whitespaces, quotes, apostrophes, and other problematic characters for a given system. The function above can be rewritten for this custom case as follows:
RegEx开始失败的地方是当我们有更复杂的字符串操作需求时。 假设我们正在接受电话号码输入,并且还希望保留各种特殊字符,例如括号,破折号和井号,但是还希望删除给定系统的空格,引号,撇号和其他有问题的字符。 可以针对这种自定义情况重写上面的函数,如下所示:
CREATE FUNCTION dbo.Remove_Non_Alphanumeric
(@String_Parameter VARCHAR(289))
RETURNS VARCHAR(289)
AS
BEGIN
DECLARE @Characters_to_Retain VARCHAR(289) = '%^[a-zA-Z0-9 ()-]%';
WHILE PATINDEX(@Characters_to_Retain, @String_Parameter) > 0
BEGIN
SELECT @String_Parameter = STUFF(@String_Parameter, PATINDEX(@Characters_to_Retain, @String_Parameter), 1, '');
END
RETURN @String_Parameter;
END
This function explicitly keeps alphanumeric characters, parenthesis, space, and the dash and returns the output we’d expect:
此函数显式保留字母数字字符,括号,空格和破折号,并返回我们期望的输出:
SELECT dbo.Remove_Non_Alphanumeric('1234567890');
SELECT dbo.Remove_Non_Alphanumeric('(123) 456-7890');
SELECT dbo.Remove_Non_Alphanumeric('123 456 7890');
SELECT dbo.Remove_Non_Alphanumeric('123-456-7890');
SELECT dbo.Remove_Non_Alphanumeric('(123) 456-7890 x123');
1234567890
(123) 456-7890
123 456 7890
123-456-7890
(123) 456-7890 x123
1234567890
(123)456-7890
123 456 7890
123-456-7890
(123)456-7890 x123
This is effective when we know exactly what characters to keep and can easily list them out. If our needs are more customized, then this can become difficult to code in an easy-to-read function or stored procedure. As we work towards a more scalable solution, we’ll look at another alternative first.
当我们确切知道要保留哪些字符并可以轻松将其列出时,此方法非常有效。 如果我们的需求更加个性化,那么使用易于阅读的功能或存储过程进行编码可能会变得困难。 在努力寻求更具扩展性的解决方案时,我们将首先考虑另一种替代方案。
CREATE FUNCTION dbo.Remove_Non_Alphanumeric
(@String_Parameter VARCHAR(289))
RETURNS VARCHAR(289)
AS
BEGIN
DECLARE @Rebuilt_String VARCHAR(MAX) = '';
DECLARE @Current_Character VARCHAR(1);
DECLARE @Character_Position INT = 1;
WHILE @Character_Position <= LEN(@String_Parameter)
BEGIN
SET @Current_Character = SUBSTRING(@String_Parameter, @Character_Position, 1);
IF ASCII(@Current_Character) BETWEEN 48 AND 57 OR ASCII(@Current_Character) BETWEEN 65 AND 90 OR ASCII(@Current_Character) BETWEEN 97 AND 122
BEGIN
SELECT @Rebuilt_String = @Rebuilt_String + @Current_Character;
END
SELECT @Character_Position = @Character_Position + 1;
END
RETURN @Rebuilt_String;
END
This function iterates through the input string one character at a time. If the current character matches our criteria, then it is added to the output string. Invalid characters are skipped, and @Rebuilt_String will end up containing only what remains. The example above explicitly calls out numbers, capital letters, and lowercase letters, so any test input we enter will be stripped of all other characters:
此函数一次遍历输入字符串一个字符。 如果当前字符符合我们的条件,则将其添加到输出字符串。 无效的字符将被跳过, @ Rebuilt_String将最终仅包含剩余字符。 上面的示例显式调用了数字,大写字母和小写字母,因此我们输入的所有测试输入都将去除所有其他字符:
SELECT dbo.Remove_Non_Alphanumeric('Test String!@#$%');
TestString
测试字符串
SELECT dbo.Remove_Non_Alphanumeric('@#^%!@%!*@}{":?><;''[]/.,');
The second example returns an empty string as every character provided is filtered out by our input criteria. The benefit of an approach like this is that we are matching characters based on their ASCII code, rather than typed out literals. This is generally more reliable and allows us to explicitly call out characters that may not exist on our keyboards. If you’re working in a Unicode character set, you may substitute NVARCHAR for all VARCHAR parameters/variables and the UNICODE function for the ASCII function. The results of these changes will allow filtering to occur over the entire Unicode character set, instead of only the ASCII character set, which would be useful in applications in which we are accepting inputs in double-byte languages (such as Japanese or Chinese) or wish to process Unicode characters.
第二个示例返回一个空字符串,因为提供的每个字符都被我们的输入条件过滤掉了。 这样的方法的好处是,我们根据字符的ASCII代码而不是键入文字来匹配字符。 这通常更可靠,并且允许我们显式调出键盘上可能不存在的字符。 如果您使用的是Unicode字符集,则可以将NVARCHAR替换为所有VARCHAR参数/变量,将UNICODE函数替换为ASCII函数。 这些更改的结果将允许在整个Unicode字符集上进行过滤,而不是仅对ASCII字符集进行过滤,这在我们接受双字节语言(例如日语或中文)或希望处理Unicode字符。
Dim_Ascii解决方案 (The Dim_Ascii Solution)
The solutions presented so far are great for simple use-cases in which our needs are consistent and unlikely to change or need to be customized over time. In larger applications in which we may have a variety of string cleansing needs, it is advantageous to not maintain all of this string logic within functions or stored procedures – especially if we have many different types of string fields that each carry their own rules.
到目前为止,提出的解决方案非常适合简单的用例,在这些用例中,我们的需求是一致的,不可能随时间变化或需要自定义。 在较大的应用程序中,我们可能需要各种各样的字符串清洗功能,因此最好不要在函数或存储过程中维护所有这些字符串逻辑-特别是如果我们有许多不同类型的字符串字段,每个字段都有各自的规则时,则尤其如此。
An elegant solution, and one that scales very well over time, is to create a dimension table for our character set (ASCII or Unicode) and populate it with the rules for our application needs. For example, let’s take the Production.Document table within the Adventureworks demo database. This table contains a variety of text fields:
一个优雅的解决方案(随时间推移扩展性非常好)是为我们的字符集(ASCII或Unicode)创建一个尺寸表,并使用满足我们应用程序需求的规则填充它。 例如,让我们使用Adventureworks演示数据库中的Production.Document表。 该表包含各种文本字段:
Let’s say we wanted to load new data into this table, and each column had unique rules to follow in terms of what characters are allowed or not:
假设我们想将新数据加载到该表中,并且每一列在允许或禁止使用哪些字符方面都有唯一的规则:
Title: Any alphanumeric, as well as any of !@#$%&*()-_+={}”:;.,?/\~
FileName: Any alphanumeric, as well as underscores and dashes.
FileExtension: Any alphanumeric and a period.
DocumentSummary: Any non-system characters.
标题 :任何字母数字,以及任何!@#$%&*()-_ + = {}”:;。,?/ \〜
FileName :任何字母数字以及下划线和破折号。
FileExtension :任何字母数字和一个句点。
DocumentSummary :任何非系统字符。
Each column has unique rules, and hard-coding those rules into different functions or stored procedures would be difficult to keep track of, document, and maintain. As more tables, columns, and strings are managed, we’d encounter greater chances of mistakes happening due to utilizing the wrong function, method, or code.
每列都有唯一的规则,并且很难将这些规则硬编码到不同的功能或存储过程中,从而难以跟踪,记录和维护。 当管理更多的表,列和字符串时,由于使用错误的函数,方法或代码,我们将出现更多发生错误的机会。
To facilitate easier storage and understanding of our string-cleansing needs, we will create a table called Dim_Ascii:
为了方便存储和理解我们的字符串清洗需求,我们将创建一个名为Dim_Ascii的表:
CREATE TABLE dbo.dim_ascii
( Ascii_ID SMALLINT NOT NULL CONSTRAINT PK_dim_ascii PRIMARY KEY CLUSTERED,
Ascii_Character VARCHAR(1) NOT NULL,
Is_Valid_In_Production_Document_Title BIT NOT NULL,
Is_Valid_In_Production_Document_FileName BIT NOT NULL,
Is_Valid_In_Production_Document_FileExtension BIT NOT NULL,
Is_Valid_In_Production_Document_DocumentSummary BIT NOT NULL );
CREATE NONCLUSTERED INDEX IX_dim_ascii_Ascii_Character ON dbo.dim_ascii(Ascii_Character);
In this table, we store the numeric ASCII ID, its corresponding character representation, and a separate bit column for each string cleansing use-case. Even if we devise many different string manipulation needs, the only change to this table that is required is the addition of another bit column. This ensures that this table, even if it becomes wide, will still require little storage and will perform well.
在此表中,我们存储数字ASCII ID,其对应的字符表示形式以及每个字符串清洗用例的单独的位列。 即使我们设计了许多不同的字符串操作需求,对该表的唯一更改就是添加了另一个bit列。 这样可以确保该表即使变宽了,仍将需要很少的存储空间并且运行良好。
Now let’s populate it with an initial set of characters:
现在让我们用一组初始字符填充它:
DECLARE @Ascii_Count SMALLINT = 1;
WHILE @Ascii_Count <= 255
BEGIN
INSERT INTO dbo.dim_ascii
(Ascii_ID, Ascii_Character, Is_Valid_In_Production_Document_Title, Is_Valid_In_Production_Document_FileName, Is_Valid_In_Production_Document_FileExtension, Is_Valid_In_Production_Document_DocumentSummary)
SELECT
@Ascii_Count,
CHAR(@Ascii_Count),
0,
0,
0,
0;
SELECT @Ascii_Count = @Ascii_Count + 1;
END
This will loop through every value in the extended ASCII character set and insert its numeric and character equivalent. Not all of these characters will be viewable in a meaningful fashion in our TSQL editor, which is why maintaining and using the ASCII codes is very important! Running a SELECT against the table shows us our progress so far:
这将遍历扩展ASCII字符集中的每个值,并插入其数字和等效字符。 在我们的TSQL编辑器中,并非所有这些字符都能以有意义的方式显示,这就是为什么维护和使用ASCII代码非常重要的原因! 对表运行SELECT可以显示到目前为止我们的进度:
The next step is to turn our business rules into sets of ones and zeroes for Dim_Ascii:
下一步是将我们的业务规则转换为Dim_Ascii的一和零集 :
UPDATE dim_ascii
SET Is_Valid_In_Production_Document_Title = 1
FROM dbo.dim_ascii
WHERE Ascii_ID BETWEEN 32 AND 126;
UPDATE dim_ascii
SET Is_Valid_In_Production_Document_FileName = 1
FROM dbo.dim_ascii
WHERE Ascii_ID BETWEEN 48 AND 57
OR Ascii_ID BETWEEN 65 AND 90
OR Ascii_ID BETWEEN 97 AND 122
OR Ascii_ID IN (45, 95);
UPDATE dim_ascii
SET Is_Valid_In_Production_Document_FileExtension = 1
FROM dbo.dim_ascii
WHERE Ascii_ID BETWEEN 48 AND 57
OR Ascii_ID BETWEEN 65 AND 90
OR Ascii_ID BETWEEN 97 AND 122
OR Ascii_ID = 46;
UPDATE dim_ascii
SET Is_Valid_In_Production_Document_DocumentSummary = 1
FROM dbo.dim_ascii
WHERE Ascii_ID BETWEEN 9 AND 13
OR Ascii_ID BETWEEN 32 AND 126;
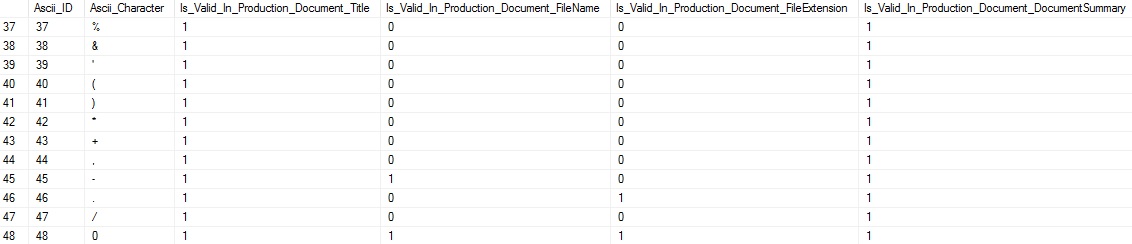
For each of the scenarios introduced, we update the appropriate Dim_Ascii column to indicate when characters are valid for it. The results look like this:
对于介绍的每种情况,我们都会更新相应的Dim_Ascii列以指示何时该字符有效。 结果如下:
We can see that, depending on the rules for each column, different ASCII characters are allowed (or not allowed). This table can be updated whenever business needs change, new use-cases arise, or wish to customize any existing data further. Now that this table is complete, we can move on to using this metadata in order to effectively populate the Production.Document table.
我们可以看到,根据每一列的规则,允许(或不允许)不同的ASCII字符。 每当业务需求发生变化,出现新的用例或希望进一步定制任何现有数据时,都可以更新此表。 现在该表已完成,我们可以继续使用此元数据以有效填充Production.Document表。
CREATE FUNCTION dbo.Remove_Non_Alphanumeric
(@String_Parameter VARCHAR(MAX),
@String_Filter_Column VARCHAR(50))
RETURNS VARCHAR(MAX)
AS
BEGIN
DECLARE @Input_String_Characters TABLE
( Character_Position INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
Character_Ascii_Value SMALLINT NOT NULL );
IF @String_Parameter IS NULL OR @String_Filter_Column IS NULL
BEGIN
RETURN NULL;
END
IF NOT EXISTS (SELECT * FROM sys.tables INNER JOIN sys.columns ON columns.object_id = tables.object_id INNER JOIN sys.types ON types.user_type_id = columns.user_type_id WHERE tables.name = 'Dim_Ascii' AND columns.name = @String_Filter_Column AND types.name = 'bit')
BEGIN
RETURN NULL;
END
DECLARE @Input_String_Length INT = LEN(@String_Parameter);
DECLARE @Character_Counter INT = 1;
WHILE @Character_Counter <= @Input_String_Length
BEGIN
INSERT INTO @Input_String_Characters
(Character_Ascii_Value)
SELECT
ASCII(SUBSTRING(@String_Parameter, @Character_Counter, 1));
SELECT @Character_Counter = @Character_Counter + 1;
END
IF @String_Filter_Column = 'Is_Valid_In_Production_Document_Title'
BEGIN
UPDATE Input_String_Characters
SET Character_Ascii_Value = -1
FROM @Input_String_Characters Input_String_Characters
INNER JOIN dbo.dim_ascii
ON dim_ascii.Ascii_ID = Input_String_Characters.Character_Ascii_Value
WHERE dim_ascii.Is_Valid_In_Production_Document_Title = 0;
END
ELSE IF @String_Filter_Column = 'Is_Valid_In_Production_Document_FileName'
BEGIN
UPDATE Input_String_Characters
SET Character_Ascii_Value = -1
FROM @Input_String_Characters Input_String_Characters
INNER JOIN dbo.dim_ascii
ON dim_ascii.Ascii_ID = Input_String_Characters.Character_Ascii_Value
WHERE dim_ascii.Is_Valid_In_Production_Document_FileName = 0;
END
ELSE IF @String_Filter_Column = 'Is_Valid_In_Production_Document_FileExtension'
BEGIN
UPDATE Input_String_Characters
SET Character_Ascii_Value = -1
FROM @Input_String_Characters Input_String_Characters
INNER JOIN dbo.dim_ascii
ON dim_ascii.Ascii_ID = Input_String_Characters.Character_Ascii_Value
WHERE dim_ascii.Is_Valid_In_Production_Document_FileExtension = 0;
END
ELSE IF @String_Filter_Column = 'Is_Valid_In_Production_Document_DocumentSummary'
BEGIN
UPDATE Input_String_Characters
SET Character_Ascii_Value = -1
FROM @Input_String_Characters Input_String_Characters
INNER JOIN dbo.dim_ascii
ON dim_ascii.Ascii_ID = Input_String_Characters.Character_Ascii_Value
WHERE dim_ascii.Is_Valid_In_Production_Document_DocumentSummary = 0;
END
DELETE
FROM @Input_String_Characters
WHERE Character_Ascii_Value = -1;
DECLARE @Output_String VARCHAR(MAX) = '';
SELECT
@Output_String = @Output_String + CHAR(Character_Ascii_Value)
FROM @Input_String_Characters Input_String_Characters;
RETURN @Output_String;
END
This function accepts a string input and column name to apply rules from and returns the cleansed string based on those rules. The process is as follows:
此函数接受字符串输入和列名以从中应用规则,并根据这些规则返回已清除的字符串。 流程如下:
- Create a table variable to store the characters from the input string. 创建一个表变量来存储输入字符串中的字符。
- Populate the table variable with each character. 用每个字符填充表变量。
- Dim_Ascii, setting all values for disallowed characters to -1. Dim_Ascii ,将禁止字符的所有值设置为-1。
- Delete all rows from the table variable that contain -1 as their ASCII value. 从表变量中删除所有包含-1作为ASCII值的行。
- Recreate the output string from the table variable and return it from the function. 从表变量重新创建输出字符串,然后从函数返回它。
You may look at this TSQL and scratch your head thinking, “Why does a simple operation take so many steps?” The answer is that SQL Server functions cannot contain any TSQL constructs. Since they can be run in-line with table access requests, we cannot use side-effecting functions, such as multi-table deletes, dynamic SQL, SELECT, or others constructs that might prove useful here.
您可能会看一下此TSQL并开始思考:“为什么一个简单的操作要花那么多步骤?” 答案是SQL Server函数不能包含任何TSQL构造。 由于它们可以与表访问请求一起运行,因此我们不能使用副作用功能,例如多表删除,动态SQL,SELECT或其他可能在这里证明有用的构造。
Dynamic SQL would have made this an elegant solution in which we could build the exact DELETE statement and join to Dim_Ascii one time, based on whatever table input was provided. In a stored procedure, we’d have more options, but the benefit of a function is its ability to be used easily within other operations. For inserting any amount of data in bulk, this is quite beneficial!
Dynamic SQL将使它成为一个优雅的解决方案,在该解决方案中,我们可以基于提供的任何表输入来构建确切的DELETE语句并连接到Dim_Ascii 。 在存储过程中,我们会有更多选择,但是函数的好处是可以轻松在其他操作中使用它。 对于批量插入任意数量的数据,这是非常有益的!
Let’s test out the function for a given input for each string cleansing need:
让我们针对每种字符串清洗需求测试给定输入的功能:
SELECT dbo.Remove_Non_Alphanumeric('Test-String number 1!@#$%', 'Is_Valid_In_Production_Document_Title');
Title allows any alphanumeric, as well as most symbols. As a result, the output looks the same as the input:
标题允许使用任何字母数字以及大多数符号。 结果,输出看起来与输入相同:
Test-String number 1!@#$%
测试字符串编号1!@#$%
SELECT dbo.Remove_Non_Alphanumeric('Test-String number 2!@#$%', 'Is_Valid_In_Production_Document_FileName');
Filename is more restrictive and only allows alphanumeric characters, as well as dashes and underscores. The result shows all non-alphanumeric charactes removed, except for the lone dash:
文件名的限制更严格,仅允许使用字母数字字符以及破折号和下划线。 结果显示除去了所有非字母数字字符,唯一的破折号除外:
Test-Stringnumber2
测试字符串数2
SELECT dbo.Remove_Non_Alphanumeric('Test-String number 3!@#$%', 'Is_Valid_In_Production_Document_FileExtension');
FileExtension allows only alphanumeric characters and periods. As a result, the output will look like this:
FileExtension仅允许使用字母数字字符和句点。 结果,输出将如下所示:
TestStringnumber3
TestStringnumber3
SELECT dbo.Remove_Non_Alphanumeric('Test-String number 4!@#$%', 'Is_Valid_In_Production_Document_DocumentSummary');
Lastly, DocumentSummary allows any characters outside of the system ASCII value range and is unchanged by the application of our function:
最后, DocumentSummary允许系统ASCII值范围之外的任何字符,并且通过应用我们的函数可以保持不变:
Test-String number 4!@#$%
测试字符串编号4!@#$%
From here, we could load data into that table, or update existing rows in bulk, using the function we created above:
从这里,我们可以使用上面创建的函数将数据加载到该表中,或批量更新现有行:
UPDATE Document
SET Title = dbo.Remove_Non_Alphanumeric(Document.Title, 'Is_Valid_In_Production_Document_Title'),
FileName = dbo.Remove_Non_Alphanumeric(Document.FileName, 'Is_Valid_In_Production_Document_FileName'),
FileExtension = dbo.Remove_Non_Alphanumeric(Document.FileExtension, 'Is_Valid_In_Production_Document_FileExtension'),
DocumentSummary = dbo.Remove_Non_Alphanumeric(Document.DocumentSummary, 'Is_Valid_In_Production_Document_DocumentSummary')
FROM Production.Document;
定制与结论 (Customization & Conclusion)
This process is made for customization. The TSQL provided is more about ideas to expand on than completed solutions, although any of these functions can be used as-is successfully. If your process allows for its use in a stored procedure instead of a function, then the ability to use dynamic SQL is opened up, allowing for a simplified custom script that automatically matches BIT column names to input parameters and filters accordingly. This would remove the need for any explicitly called out column names within our code, making it even more portable and maintainable.
进行此过程是为了进行定制。 尽管可以成功使用所有这些功能,但提供的TSQL并不是完整的解决方案,更多的是关于扩展想法的。 如果您的过程允许在存储过程中使用它而不是在函数中使用,那么将打开使用动态SQL的功能,从而允许使用简化的自定义脚本,该脚本自动将BIT列名与输入参数进行匹配并相应地进行过滤。 这将消除对我们代码中任何显式调用的列名的需求,从而使其更加可移植和可维护。
The use of a dimension table to store information about how and what we do to clean up string inputs allows for all of this logic to be stored in a single place. This removes the need for many disparate stored procedures, TSQL blocks, or other business logic being spread throughout our schema. For simple/singular needs, though, a function using RegEx or ASCII ranges can accomplish what we want with relatively minimal effort.
使用维表存储有关清理字符串输入的方式和方法的信息,可以将所有这些逻辑存储在一个位置。 这消除了在我们的架构中散布许多不同的存储过程,TSQL块或其他业务逻辑的需求。 但是,对于简单/单一的需求,使用RegEx或ASCII范围的函数可以用相对较少的精力完成我们想要的。
For any inputs that originate from outside of your control, i.e. the internet, always check that string inputs are valid and if you are using any dynamic SQL, ensure they are properly delimited to prevent any SQL injection, string search manipulation, or other bad behavior by your users.
对于来自控件外部(例如互联网)的任何输入,请始终检查字符串输入是否有效,并且如果您使用的是任何动态SQL,请确保对它们进行正确定界以防止任何SQL注入,字符串搜索操作或其他不良行为由您的用户。
Lastly, if possible, have the application and SQL Server objects validate and cleanse strings. Layering string cleansing greatly reduces the chance of bad inputs making it into the database and helps keep your data in an acceptable form. If rules are very specific and difficult to follow, also consider check constraints to control what can be stored in a table. If a given column doesn’t allow certain characters, then the need to cleanse exists more for error prevention than data integrity.
最后,如果可能,让应用程序和SQL Server对象验证并清除字符串。 分层的字符串清除大大减少了将错误的数据输入数据库的可能性,并有助于使数据保持可接受的格式。 如果规则非常具体且难以遵循,则还应考虑检查约束以控制可以存储在表中的内容。 如果给定的列不允许某些字符,那么为了防止错误,需要清理的不仅仅是数据完整性。
翻译自: https://www.sqlshack.com/sanitizing-inputs-avoiding-security-usability-disasters/
清理搜狗输入法















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









