





学习sql注入:猜测数据库
Deleting and updating data is very common, but if performed without taking care, which could lead to inconsistent data or data loss. Today, we’ll talk about SQL best practices when performing deletes and updates. We’re not talking about regular/expected changes, but rather about manual changes which will be required from time to time. So, let’s start.
删除和更新数据非常普遍,但是如果不加小心地执行,则可能导致数据不一致或数据丢失。 今天,我们将讨论执行删除和更新时SQL最佳实践。 我们不是在讨论常规/预期的更改,而是在不时进行手动更改。 所以,让我们开始吧。
资料模型 (Data Model)
We’ll use the same data model we’re using in this series.
我们将使用与本系列相同的数据模型。

Still, we’ll focus only on one table and that is the customer table. We’ll create table backup and update a few rows in this table.
尽管如此,我们将仅关注一个表,即customer表。 我们将创建表备份并更新该表中的几行。
也许最重要SQL最佳实践–创建备份 (Maybe the most important SQL Best Practice – Create Backups)
Creating a backup is not only SQL best practice but also a good habit, and, in my opinion, you should backup table(s) (even the whole database) when you’re performing a large number of data changes. This will allow you two things. First, you’ll be able to compare old and new data and draw a conclusion if everything went as planned. And second – in case something went wrong, you can easily revert everything. If you need a simple way to back up a table, except options on the GUI (which are specific to different tools), you have a very simple SQL command at your disposal.
创建备份不仅是SQL的最佳做法,而且是一个好习惯,而且我认为,当您执行大量数据更改时,应该备份表(甚至是整个数据库)。 这将使您有两件事。 首先,如果一切按计划进行,您将能够比较新旧数据并得出结论。 其次-万一出了问题,您可以轻松地还原所有内容。 如果除了GUI上的选项(特定于其他工具)之外,还需要一种简单的方法来备份表,则可以使用非常简单SQL命令。
-- backup table using SELECT ... INTO ...
SELECT *
INTO customer_backup
FROM customer;
Please notice here that the keys were not backed up and therefore if you’ll need to recreate the original customer table from the customer_backup table, you’ll need to do one of the following (this is not only SQL best practice but required to keep the referential integrity):
请注意,此处没有备份密钥,因此,如果您需要从customer_backup表重新创建原始客户表,则需要执行以下操作之一(这不仅是SQL最佳实践,而且还需要保留参照完整性):
Completely delete the customer table (using the command DROP TABLE customer;), and re-create it from the customer_backup table (the same way we’ve created backup). The problem here is that you won’t be able to drop the table if it’s referenced in other tables. In our case, the call table has attribute call.customer_id related to customer.id. The system won’t allow you to perform the DROP statement because this way, you would impact the referential integrity of the database
完全删除客户表(使用命令DROP TABLE customer;),然后从customer_backup表中重新创建它(与创建备份的方式相同)。 这里的问题是,如果在其他表中引用了该表,则将无法删除该表。 在我们的例子中,调用表具有与customer.id相关的属性call.customer_id 。 系统不允许您执行DROP语句,因为这样会影响数据库的参照完整性
Delete all records from the customer table and insert all records from the customer_backup table. This approach again won’t work if you have records referenced from other tables (as we do have)
删除从客户表中的所有记录,并从customer_backup表中插入的所有记录。 如果您有从其他表引用的记录(如我们所知),则该方法将再次不起作用

To perform any of the previous two actions, you should first drop constraints, then perform the desired action, and recreate constraints. Before doing that, we should determine all the constraints related to the customer table. I’ll use the query below to do that. You can check more regarding the INFORMATION SCHEMA database in the Learn SQL: The INFORMATION_SCHEMA Database article.
要执行前两个动作中的任何一个,您应该首先删除约束,然后执行所需的动作,然后重新创建约束。 在此之前,我们应该确定与客户表相关的所有约束。 我将使用下面的查询来做到这一点。 您可以在“ 学习SQL:INFORMATION_SCHEMA数据库”一文中查看有关INFORMATION SCHEMA数据库的更多信息 。
-- primary key & foreign key used in this table (relation to another table)
SELECT
tc.CONSTRAINT_TYPE,
tc.CONSTRAINT_NAME,
tc.TABLE_NAME
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS tc
WHERE tc.TABLE_CATALOG = 'our_first_database'
AND tc.TABLE_NAME = 'customer'
UNION
-- another table referencing this table
SELECT
CONCAT('referenced in table: ', tc1.TABLE_NAME) AS CONSTRAINT_TYPE,
tc1.CONSTRAINT_NAME,
tc2.TABLE_NAME
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS rc
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS tc1 ON rc.CONSTRAINT_NAME = tc1.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS tc2 ON rc.UNIQUE_CONSTRAINT_NAME = tc2.CONSTRAINT_NAME
WHERE rc.CONSTRAINT_CATALOG = 'our_first_database'
AND tc2.TABLE_NAME = 'customer';
You can see the query result in the picture below.
您可以在下图中看到查询结果。
As you can see, we’ve identified 3 keys related to the customer table: customer_pk – primary key of the table, customer_city – relation between tables customer and city (city.id is referenced), and call_customer – relation between tables call and customer (customer.id is referenced).
如您所见,我们确定了与客户表相关的3个键: customer_pk –表的主键, customer_city –表customer和city之间的关系(已引用city.id),以及call_customer –表call和customer之间的关系(引用了customer.id)。
One useful SQL Server procedure is sp_help. We can use it to get details about the table. For the customer table, the result returned would be like in the picture below.
sp_help是一种有用SQL Server过程。 我们可以使用它来获取有关表的详细信息。 对于客户表,返回的结果如下图所示。
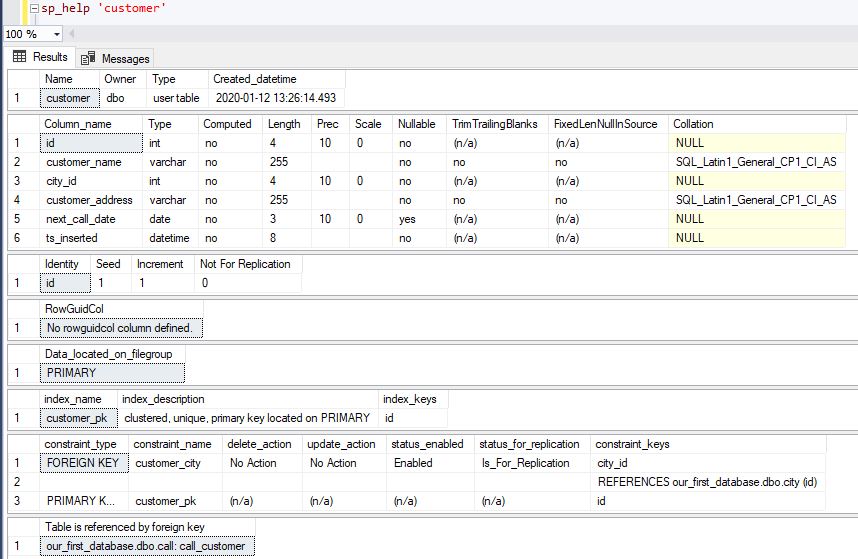
Since we have their names, we can easily drop all 3 constraints and recreate them later. To drop them, we can use the following statements:
由于有了它们的名称,因此我们可以轻松删除所有3个约束并在以后重新创建它们。 要删除它们,我们可以使用以下语句:
-- drop constraints
DROP CONSTRAINT customer_pk;
DROP CONSTRAINT customer_city;
DROP CONSTRAINT call_customer;
But, before we drop them, we should “store” create commands, so we can use them after we recreate the customer table from the backup. We can do it by right-clicking on each constraint and export them to a new query window.
但是,在删除它们之前,我们应该“存储”创建命令,以便在从备份重新创建客户表之后可以使用它们。 我们可以通过右键单击每个约束并将其导出到新的查询窗口来实现。
-- customer PK
ALTER TABLE [dbo].[customer] ADD CONSTRAINT [customer_pk] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
-- FK: customer.city_id = city_id
ALTER TABLE [dbo].[customer] WITH CHECK ADD CONSTRAINT [customer_city] FOREIGN KEY([city_id])
REFERENCES [dbo].[city] ([id])
GO
ALTER TABLE [dbo].[customer] CHECK CONSTRAINT [customer_city]
GO
-- FK: call.customer_id = customer.id
ALTER TABLE [dbo].[call] WITH CHECK ADD CONSTRAINT [call_customer] FOREIGN KEY([customer_id])
REFERENCES [dbo].[customer] ([id])
GO
ALTER TABLE [dbo].[call] CHECK CONSTRAINT [call_customer]
GO
准备报表 (Preparing statements)
If you’re performing changes on just a few rows, that is something where you can “take a risk”, copy old data to Excel, change them manually and visually confirm if everything went OK. In that case, there is no point in applying SQL best practices mentioned in this article.
如果仅在几行上执行更改,则可以“冒险”,将旧数据复制到Excel,手动更改它们,并直观地确认一切正常。 在这种情况下,没有必要应用本文中提到SQL最佳实践。
Still, from time to time, you’ll get a bunch of data that should be either updated with new values, either deleted from the system. These could be hundreds of rows, but also millions. Of course, in such cases, inspecting changes visually is not the solution, and such cases are good candidates to apply SQL best practices mentioned today.
不过,您仍然会不时地获得一堆数据,这些数据应该用新值更新,或者从系统中删除。 这些可能是几百行,但也有几百万行。 当然,在这种情况下,目视检查更改不是解决方案,并且这些情况是应用今天提到SQL最佳实践的很好的选择。
One thing that you should do before performing mass updates or deletes is to run a select statement using conditions provided. In the ideal situation, you would have provided PK (primary key) or UNIQUE/AK (alternate key) values. This will list all the cases that shall be impacted and also give you a feeling of what shall happen.
在执行批量更新或删除之前,您应该做的一件事是使用提供的条件运行select语句 。 在理想情况下,您应该提供PK(主键)或UNIQUE / AK(备用键)值。 这将列出所有将受到影响的情况,并使您对将要发生的情况有一种感觉。
When you’re sure these are truly the cases that should be updated/deleted, you’re ready to prepare statements to perform the desired operation. You can do it in 2 ways:
当您确定确实是应该更新/删除的情况时,就可以准备执行所需操作的语句了。 您可以通过2种方式来做到这一点:
Every single update/delete is performed by the UNIQUE value and is limited to exactly one row (using TOP(1) in SQL Server or LIMIT 1 in MySQL). This is pretty safe because you’ll be sure that each command impacts exactly one row. Also, for updates, this is sometimes the only option, because you can expect that you’ll have different values you want to set for different rows
每个单独的更新/删除操作均由UNIQUE值执行,并且仅限于一行(使用SQL Server中的TOP(1)或MySQL中的LIMIT 1)。 这是非常安全的,因为您可以确保每个命令仅影响一行。 此外,对于更新而言,有时这是唯一的选择,因为您可以期望为不同的行设置不同的值
UPDATE TOP(1) customer SET next_call_date = '2020/08/01' WHERE id = 1; UPDATE TOP(1) customer SET next_call_date = '2020/08/01' WHERE id = 2;
You could run one statement with all ids listed in it. This will work faster because you have only 1 statement. You have somehow less “control” here, but still, this is completely OK option to go with, especially in cases when you’re working with a really large number of rows. This will work well for deletes and should be considered SQL best practice. For updates, this method shall work only in case you’re updating all rows using the same values
您可以运行一个列出了所有ID的语句。 这将更快地工作,因为您只有1条语句。 您这里的“控制”方式有所减少,但是,这是完全可以接受的选项,尤其是当您要处理大量行时。 这对于删除将非常有效,应被视为SQL最佳实践。 对于更新,仅当您使用相同的值更新所有行时,此方法才有效
UPDATE customer SET next_call_date = '2020/08/01' WHERE id in (1, 2);
使用交易 (Use Transactions)
Transactions as concepts are extremely important in the database, but for the sake of this article, we’ll just tell that they allow us to perform all statements inside the transaction or none. If any statement fails for any reason, there will be no changes applied. This is not only SQL best practice (you should always use transactions when a whole batch of commands must run successfully), but also sounds very useful in cases we have a large batch of update/delete statements. Let’s take a look at the code that will do the trick.
作为概念的事务在数据库中非常重要,但是出于本文的目的,我们只是告诉他们它们允许我们执行事务内的所有语句,也可以不执行任何语句。 如果任何语句由于任何原因而失败,将不会应用任何更改。 这不仅是SQL最佳实践(当必须成功运行整批命令时,您应该始终使用事务),而且在我们有大量更新/删除语句的情况下听起来也很有用。 让我们看一下将完成技巧的代码。
BEGIN TRANSACTION;
UPDATE TOP(1) customer SET next_call_date = '2020/08/01' WHERE id = 1;
UPDATE TOP(1) customer SET next_call_date = '2020/08/01' WHERE id = 2;
COMMIT TRANSACTION;
最终SQL最佳实践–检查发生了什么 (Final SQL Best Practice – Check what happened)
In case you’ve created a backup, you should compare old and new tables.
如果创建了备份,则应比较旧表和新表。
If you’ve deleted data, you’ll simply search for rows that are present in the old table, and we don’t have them in the new table, using LEFT JOIN. The total number should match what we’ve expected based on the input data and select a statement with the same conditions (if we’ve run it before).
如果您删除了数据,则只需使用LEFT JOIN搜索旧表中存在的行,而在新表中就不会包含这些行。 总数应与基于输入数据的期望值相符,并选择具有相同条件的语句(如果之前已运行过)。
SELECT cb.*
FROM customer_backup cb
LEFT JOIN customer c ON cb.id = c.id
WHERE c.id IS NULL;
Since we performed only updates and there were no deletions, the returned result is empty (all customers who are in the old table are also in the new table).
由于我们仅执行更新而没有删除,因此返回的结果为空(旧表中的所有客户也都在新表中)。
In case we’ve performed updates, you can compare old and new rows by joining them using INNER JOIN. Rows that have differences in any of the attributes are the ones that were impacted with update statements. Of course, you’ll need to compare all attributes that were affected by updates in any of the statements. E.g., if you know you’ve changed only the next_call_date, you can check using only that attribute. But if other attributes were also mentioned in any of the statements, you should incorporate all of them in your check. The example below will check all attributes for differences.
如果我们执行了更新,则可以使用INNER JOIN将新行与旧行进行比较。 在任何属性中具有差异的行都是受update语句影响的行。 当然,您需要比较任何语句中受更新影响的所有属性。 例如,如果您知道仅更改了next_call_date ,则可以仅使用该属性进行检查。 但是,如果在任何语句中还提到了其他属性,则应将所有这些属性合并到检查中。 下面的示例将检查所有属性是否存在差异。
SELECT *
FROM customer_backup cb
INNER JOIN customer c ON cb.id = c.id
WHERE c.customer_address <> cb.customer_address
OR c.customer_name <> cb.customer_name
OR c.next_call_date <> cb.next_call_date
OR c.ts_inserted <> cb.ts_inserted;

As expected, we have 2 rows in the final result, and these are exactly 2 ones we’ve updated using previous statements.
不出所料,最终结果中有2行,而这正是我们使用先前语句更新过的2行。
执行更新和删除时SQL最佳实践 (SQL Best Practices when performing Updates and Deletes)
One of the most important things while working with databases is not to lose or “damage” your data. To avoid that, you should stick to SQL best practices. Before you decide to perform mass deletes/updates of data in your database, it would be good that you back up all tables where changes are expected. After changes are performed, you should compare the old and the new table. If everything went OK, you can delete the backup tables. If there were errors, you should revert things (replace the “live” table with the one previously backed up) and try again (with corrected code).
使用数据库时,最重要的事情之一是不会丢失或“损坏”数据。 为了避免这种情况,您应该遵循SQL最佳实践。 在决定对数据库中的数据进行批量删除/更新之前,最好备份所有可能发生更改的表。 执行更改后,您应该比较旧表和新表。 如果一切正常,则可以删除备份表。 如果出现错误,则应还原内容(将“活动”表替换为先前备份的表),然后重试(使用更正的代码)。
目录 (Table of contents)
翻译自: https://www.sqlshack.com/learn-sql-sql-best-practices-for-deleting-and-updating-data/
学习sql注入:猜测数据库















 1405
1405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









