





 本文介绍了如何使用递归实现JavaScript中的Array.map、Array.filter和Array.reduce方法。通过示例代码和逐步解析,解释了递归在处理数组操作中的工作原理,帮助理解这些方法的内部机制。
本文介绍了如何使用递归实现JavaScript中的Array.map、Array.filter和Array.reduce方法。通过示例代码和逐步解析,解释了递归在处理数组操作中的工作原理,帮助理解这些方法的内部机制。
ls 递归 过滤
Array.map (Array.map)
We all probably know Array.map. It transforms an array of elements according to a given function.
我们可能都知道Array.map 。 它根据给定的函数转换元素数组。
double = (x) => x * 2;
map(double, [1, 2, 3]);
// [2, 4, 6]I’ve always seen it implemented along these lines:
我一直看到它是按照以下方式实现的:
map = (fn, arr) => {
const mappedArr = [];
for (let i = 0; i < arr.length; i++) {
let mapped = fn(arr[i]);
mappedArr.push(mapped);
}
return mappedArr;
};This video exposed me to an alternative Array.map implementation. It’s from a 2014 JSConf — way before I jumped on the functional programming bandwagon.
该视频向我展示了Array.map的替代实现。 它来自2014年的JSConf —在我跳入函数式编程潮流之前。
Edit: David Cizek and Stephen Blackstone kindly pointed out edge-cases and suboptimal performance regarding this map implementation. I wouldn’t advise anyone use this in a real app. My intention’s that we appreciate and learn from this thought-provoking, recursive approach. ?
编辑: David Cizek和Stephen Blackstone指出了这种map实现的边缘情况和次优性能。 我不建议任何人在真实应用中使用它。 我的意图是,我们感谢这种发人深省的递归方法并从中学习。 ?
The original example’s in CoffeeScript, here’s a JavaScript equivalent.
原始示例在CoffeeScript中,这是等效JavaScript。
map = (fn, [head, ...tail]) =>
head === undefined ? [] : [fn(head), ...map(fn, tail)];You might use David Cizek’s safer implementation instead.
您可以改用David Cizek的更安全的实现。
map = (_fn_, [_head_, ..._tail_]) _=>_ (
head === undefined && tail.length < 1
? []
: [fn(head), ...map(fn, tail)]
);Using ES6's destructuring assignment, we store the array’s first element into the variable head. Then we store all the other array elements into tail.
使用ES6的解构分配 ,我们将数组的第一个元素存储到变量head 。 然后我们将所有其他数组元素存储到tail 。
If head is undefined, that means we have an empty array, so just return an empty array. We’ve mapped nothing.
如果head是undefined ,则意味着我们有一个空数组,因此只需返回一个空数组。 我们没有映射任何东西。
map(double, []);
// []If head is not undefined we return a new array with fn(head) as the first element. We’ve now mapped the array’s first element. Alongside it is map(fn, tail) which calls map again, this time with one less element.
如果undefined head 则返回一个以fn(head)作为第一个元素的新数组。 现在,我们已经映射了数组的第一个元素。 旁边是再次调用map map(fn, tail) ,这次元素少了一个。
Since map returns an array, we use ES6’s spread syntax to concatenate it with [head].
由于map返回一个数组,因此我们使用ES6的spread语法将其与[head]连接起来。
Let’s step through this in the debugger. Paste this into your browser’s JavaScript console.
让我们在调试器中逐步解决。 将此粘贴到浏览器JavaScript控制台中。
map = (fn, [head, ...tail]) => {
if (head === undefined) {
return [];
}
debugger;
return [fn(head), ...map(fn, tail)];
};Now let’s map(double, [1, 2, 3]).
现在我们来map(double, [1, 2, 3]) 。
We see our local variables:
我们看到我们的局部变量:
head: 1
tail: [2, 3]
fn: doubleWe know fn(head) is 2. That becomes the new array’s first element. Then we call map again with fn and the rest of the array’s elements: tail.
我们知道fn(head)是2 。 这成为新数组的第一个元素。 然后,我们再次使用fn和数组的其余元素调用map : tail 。
So before the initial map call even returns, we’ll keep calling map until the array’s been emptied out. Once the array’s empty, head will be undefined, allowing our base case to run and finish the whole process.
因此,在初始map调用返回之前,我们将继续调用map直到清空数组为止。 一旦数组为空, head将是undefined ,从而允许我们的基本案例运行并完成整个过程。
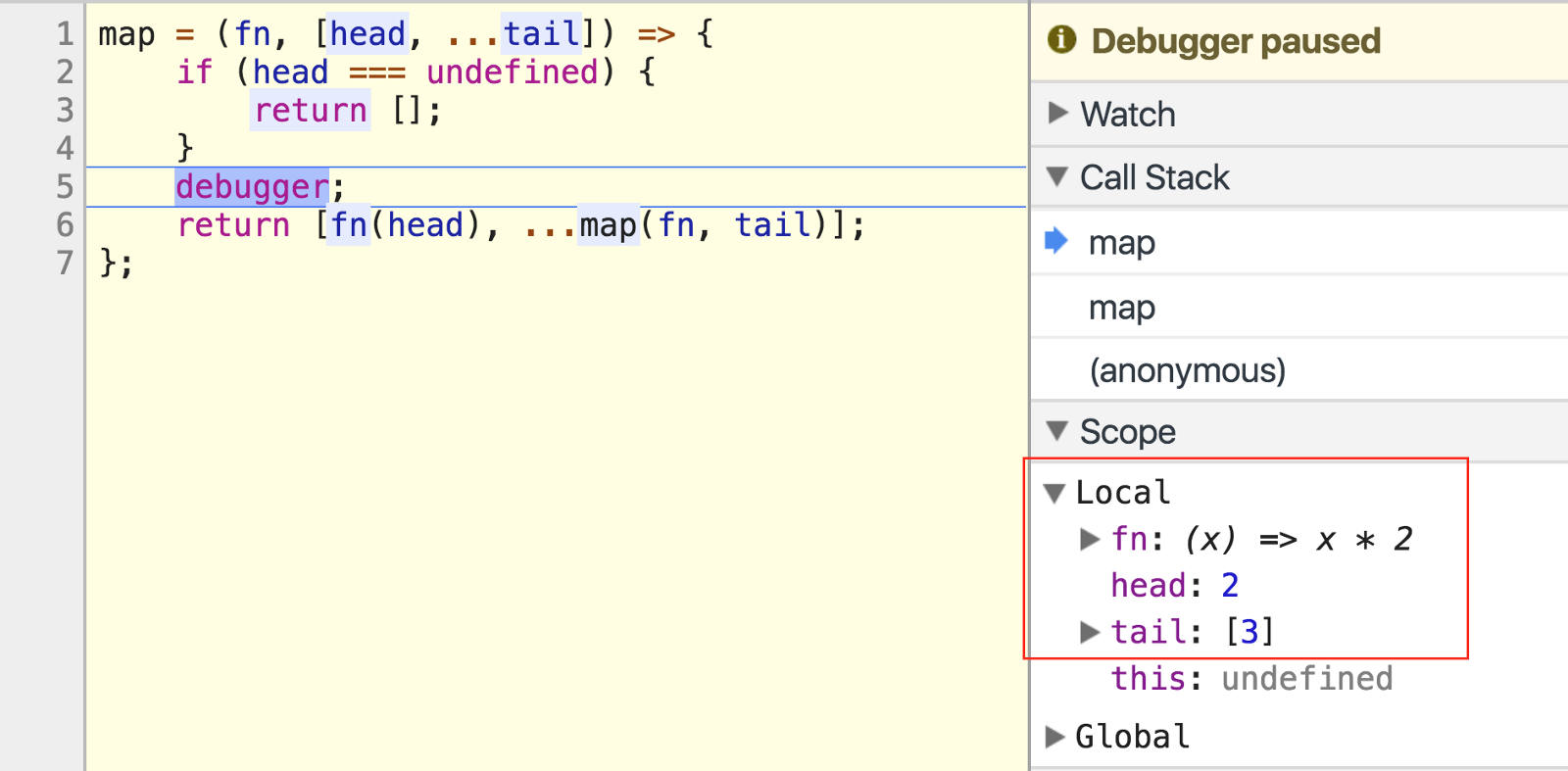
On the next run, head is 2 and tail is [3].
在下一次运行中, head为2 , tail为[3] 。
Since tail isn’t empty yet, hit the next breakpoint to call map again.
由于tail尚未为空,请点击下一个断点以再次调用map 。
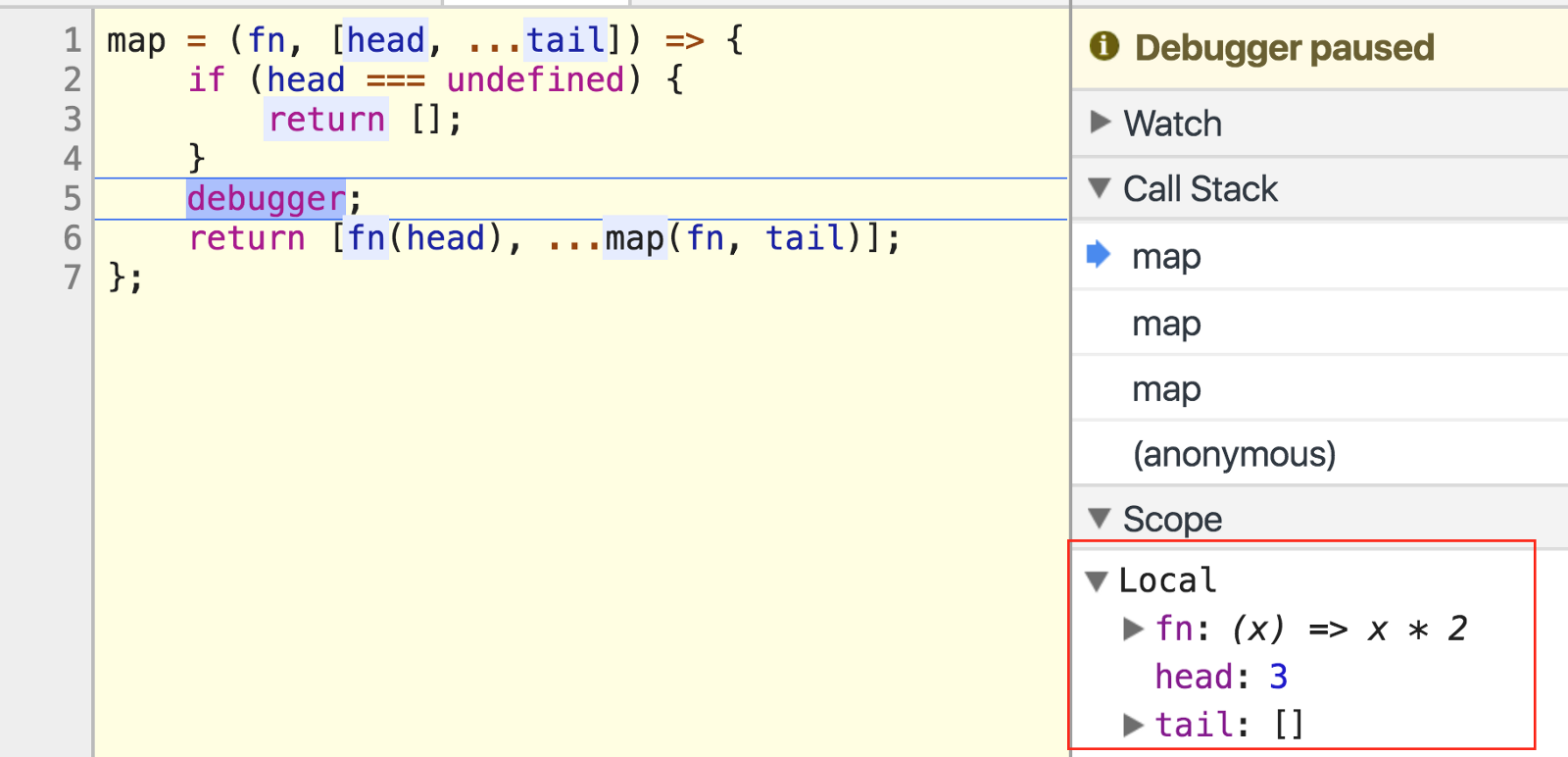
head is 3, and tail is an empty array. The next time this function runs, it’ll bail on line 3 and finally return the mapped array.
head是3 , tail是一个空数组。 下次该函数运行时,它将在第3行上保释,并最终返回映射的数组。
And here’s our end result:
这是我们的最终结果:
数组过滤器 (Array.filter)
Array.filter returns a new array based on the elements that satisfy a given predicate function.
Array.filter基于满足给定谓词功能的元素返回一个新数组。
isEven = (x) => x % 2 === 0;
filter(isEven, [1, 2, 3]);
// [2]Consider this recursive solution:
考虑以下递归解决方案:
filter = (pred, [head, ...tail]) =>
head === undefined
? []
: pred(head)
? [head, ...filter(pred, tail)]
: [...filter(pred, tail)];If map made sense, this'll be easy.
如果map有意义,这将很容易。
We’re still capturing the array’s first element in a variable called head, and the rest in a separate array called tail.
我们仍然在名为head的变量中捕获数组的第一个元素,而在另一个名为tail的单独数组中捕获其余元素。
And with the same base case, if head is undefined, return an empty array and finish iterating.
在相同的基本情况下,如果head undefined ,则返回一个空数组并完成迭代。
But we have another conditional statement: only put head in the new array if pred(head) is true, because filter works by testing each element against a predicate function. Only when the predicate returns true, do we add that element to the new array.
但是,我们还有另一条条件语句:仅当pred(head)为true ,才将head放置在新数组中,因为filter通过针对谓词函数测试每个元素来工作。 仅当谓词返回true ,我们才将该元素添加到新数组中。
If pred(head) doesn’t return true, just call filter(pred, tail) without head.
如果pred(head)没有返回true ,则不使用head调用filter(pred, tail) 。
Let’s quickly expand and step through this in the Chrome console.
让我们在Chrome控制台中快速展开并逐步完成此操作。
filter = (pred, [head, ...tail]) => {
if (head === undefined) return [];
if (pred(head)) {
debugger;
return [head, ...filter(pred, tail)];
}
debugger;
return [...filter(pred, tail)];
};And look for numbers ≤ 10:
并寻找≤10的数字:
filter(x => x <= 10, [1, 10, 20]);
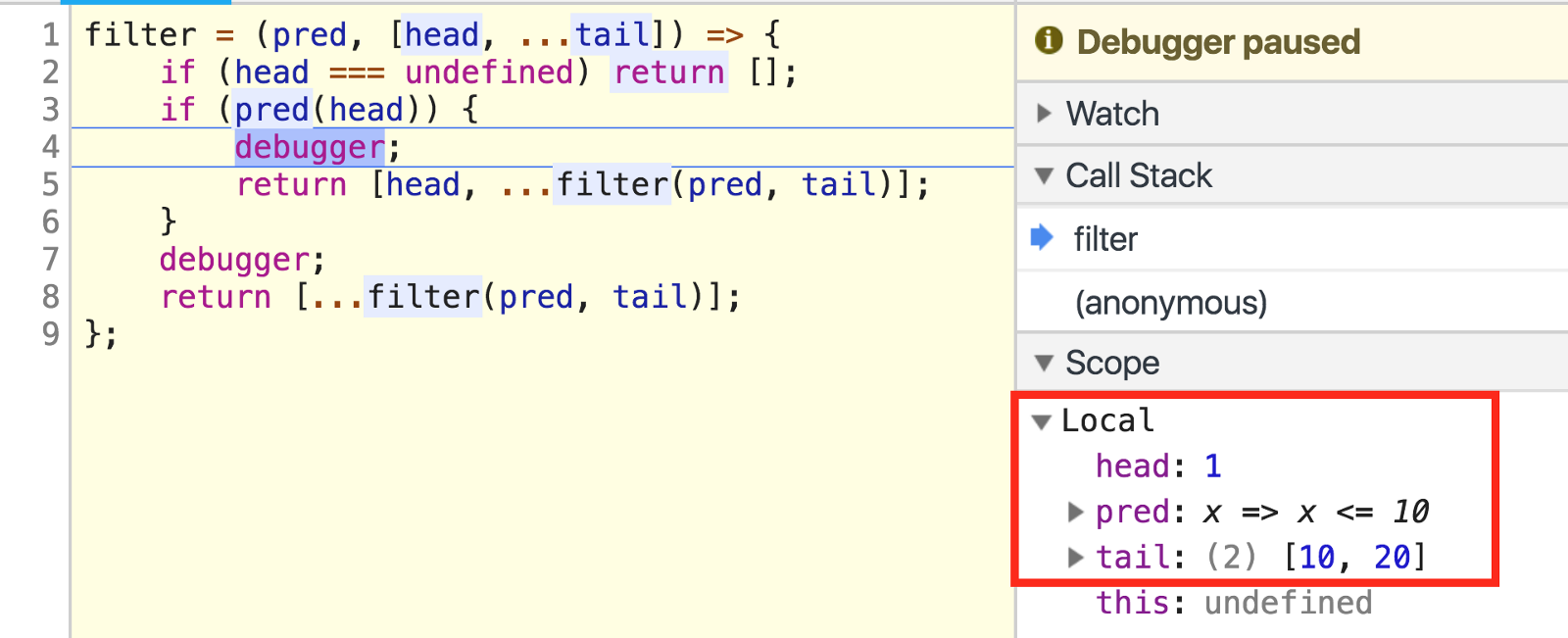
Since our array’s [1, 10, 20], head is the first element, 1, and tail is an array of the rest: [10, 20].
因为我们数组的[1, 10, 20] ,所以head是第一个元素1,而tail是其余元素的数组: [10, 20] 。
The predicate tests if x ≤ 10, so pred(1) returns true. That’s why we paused on line 4’s debugger statement.
谓词测试如果x ≤10,所以pred(1)返回true 。 这就是我们在第4行的debugger语句上暂停的原因。
Since the current head passed the test, it’s allowed entry into our filtered array. But we’re not done, so we call filter again with the same predicate, and now tail.
由于当前的head通过了测试,因此允许其进入我们的过滤数组。 但是我们还没有完成,所以我们使用相同的谓词再次调用filter ,现在使用tail 。
Move to the next debugger.
移至下一个debugger 。
We called filter with [10, 20] so head is now 10, and tail is [20]. So how does tail get smaller with each successive iteration?
我们用[10, 20]调用filter ,所以head现在是10,而tail是[20] 。 那么tail如何在每次连续迭代中变小?
We’re on line 4’s debugger once again because because 10 ≤ 10. Move to the next breakpoint.
我们再次进入第4行的debugger ,因为10≤10。移至下一个断点。
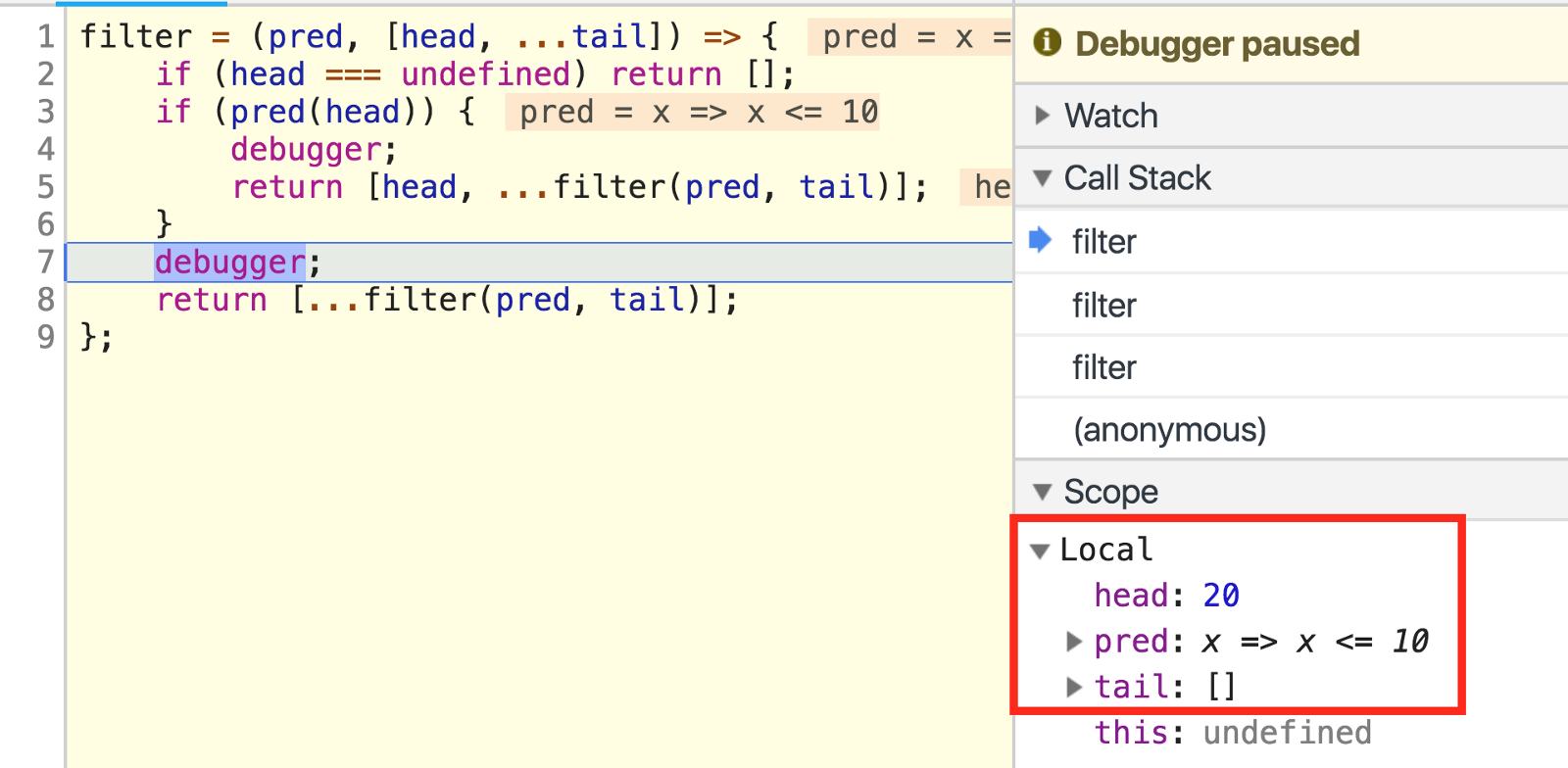
head's now 20 and tail's empty.
head现在是20, tail是空的。
Since 20 > 10, pred(head) returns false and our filtered array won’t include it. We’ll call filter one more time without head.
由于20> 10,因此pred(head)返回false而我们的过滤后的数组将不包含它。 我们会打电话给filter一次没有head 。
This next time, however, filter will bail on line 2. Destructuring an empty array gives you undefined variables. Continue past this breakpoint to get your return value.
这接下来的时间,然而, filter将保释第2行解构一个空数组给你undefined变量。 继续经过此断点以获取您的返回值。
That looks correct to me!
对我来说这看起来很正确!
数组减少 (Array.reduce)
Last but not least, Array.reduce is great for boiling an array down to a single value.
最后但并非最不重要的一点, Array.reduce非常适合将数组缩减为单个值。
Here’s my naive reduce implementation:
这是我朴素的reduce实现:
reduce = (fn, acc, arr) => {
for (let i = 0; i < arr.length; i++) {
acc = fn(acc, arr[i]);
}
return acc;
};And we can use it like this:
我们可以这样使用它:
add = (x, y) => x + y;
reduce(add, 0, [1, 2, 3]); // 6You’d get the same result with this recursive implementation:
通过此递归实现,您将获得相同的结果:
reduce = (fn, acc, [head, ...tail]) =>
head === undefined ? acc : reduce(fn, fn(acc, head), tail);I find this one much easier to read than recursive map and filter.
我发现它比递归map和filter更容易阅读。
Let’s step through this in the browser console. Here’s an expanded version with debugger statements:
让我们在浏览器控制台中逐步完成此操作。 这是带有debugger语句的扩展版本:
reduce = (fn, acc, [head, ...tail]) => {
if (head === undefined) {
debugger;
return acc;
}
debugger;
return reduce(fn, fn(acc, head), tail);
};Then we’ll call this in the console:
然后,在控制台中将其称为:
add = (x, y) => x + y;
reduce(add, 0, [1, 2, 3]);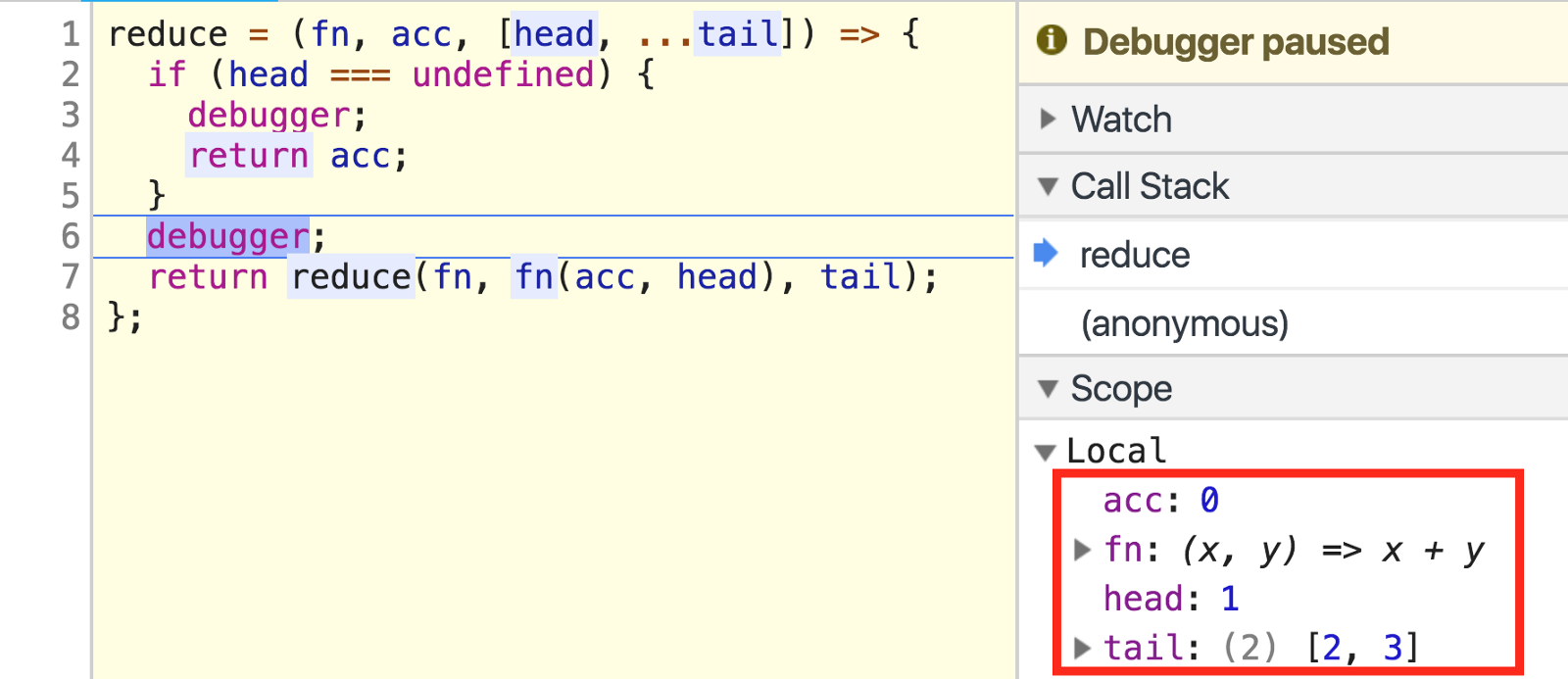
第1轮 (Round 1)
We see our local variables:
我们看到我们的局部变量:
acc: our initial value of 0
acc :我们的初始值为0
fn: our add function
fn :我们的add函数
head: the array’s first element, 1
head :数组的第一个元素, 1
tail: the array’s other elements packed into a separate array, [2, 3]
tail :数组的其他元素打包到一个单独的数组中, [2, 3]
Since head isn’t undefined we’re going to recursively call reduce, passing along its required parameters:
由于head不是undefined我们将递归调用reduce , 并传递其必需的参数 :
fn: Obviously the add function again ?
fn :显然又add功能吗?
acc: The result of calling fn(acc, head). Since acc is 0, and head is 1, add(0, 1) returns 1.
acc :调用fn(acc, head) 。 由于acc为0且head为1 ,因此add(0, 1)返回1 。
tail: The array’s leftover elements. By always using tail, we keep cutting the array down until nothing’s left!
tail :数组的剩余元素。 通过始终使用tail,我们会不断减少数组,直到什么都没剩下!
Move to the next debugger.
移至下一个debugger 。
第二回合 (Round 2)
Local variables:
局部变量:
acc: Now it’s 1, because we called reduce with fn(acc, head), which was add(0, 1) at the time.
acc :现在是1 ,因为我们用fn(acc, head)调用了reduce ,当时它是add(0, 1) 。
fn: Still add!
fn :还是add !
head: Remember how we passed the previous tail to reduce? Now that’s been destructured, with head representing its first element, 2.
head :还记得我们如何通过reduce前tail ? 现在,该文件已进行了重组,其中head表示其第一个元素2 。
tail: There’s only one element left, so 3’s been packed into an array all by itself.
tail :仅剩一个元素,因此3本身就被打包成一个数组。
We know the next reduce call will take a function, accumulator, and array. We can evaluate the next set of parameters using the console.
我们知道下一个reduce调用将采用一个函数,累加器和数组。 我们可以使用控制台评估下一组参数。

Expect these values on the next breakpoint.
在下一个断点处期望这些值。
第三回合 (Round 3)

Our local variables are as expected. head's first and only element is 3.
我们的局部变量符合预期。 head的第一个也是唯一的元素是3 。
And our array only has one element left, tail's empty! That means the next breakpoint will be our last.
而且我们的数组只剩下一个元素, tail空! 这意味着下一个断点将是我们的最后一个断点。
Let’s quickly evaluate our future local variables:
让我们快速评估我们将来的局部变量:

Move to the final breakpoint.
移至最终断点。
第四回合 (Round 4)

Check it out, we paused on line 3 instead of line 6 this time! head is undefined so we’re returning the final, 6! It’ll pop out if you move to the next breakpoint.
检查一下,这次我们暂停在第3行而不是第6行! head undefined因此我们将返回决赛6 ! 如果您移至下一个断点,它将弹出。

Looks good to me! Thank you so much for reading this.
在我看来很好! 非常感谢您阅读本文。
翻译自: https://www.freecodecamp.org/news/implement-array-map-with-recursion-35976d0325b2/
ls 递归 过滤















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









