






多台计算机共享内存
共享内存多处理器 (Shared Memory Multiprocessor)
There are three types of shared memory multiprocessor:
共有三种类型的共享内存多处理器:
UMA (Uniform Memory Access)
UMA(统一内存访问)
NUMA (Non- uniform Memory Access)
NUMA(非统一内存访问)
COMA (Cache Only Memory)
COMA(仅缓存内存)
1)UMA(统一内存访问) (1) UMA (Uniform Memory Access))
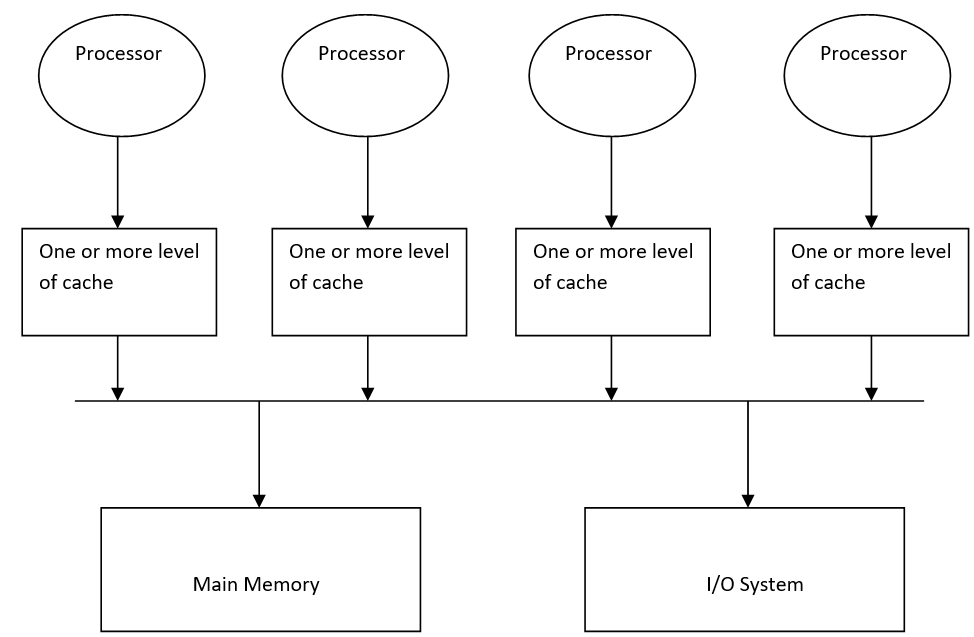
In this type of multiprocessor, all the processors share a unique centralized memory so, that each CPU has the same memory access time.
在这种类型的多处理器中,所有处理器共享唯一的集中式内存,以便每个CPU具有相同的内存访问时间。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1955
1955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









