







1.shced.c
1 /*2 * linux/kernel/sched.c
3 *
4 * (C) 1991 Linus Torvalds
5 */
6
7 /*
8 * 'sched.c' is the main kernel file. It contains scheduling primitives
9 * (sleep_on, wakeup, schedule etc) as well as a number of simple system
10 * call functions (type getpid(), which just extracts a field from
11 * current-task
12 */
13 #include <linux/sched.h>
14 #include <linux/kernel.h>
15 #include <linux/sys.h>
16 #include <linux/fdreg.h>
17 #include <asm/system.h>
18 #include <asm/io.h>
19 #include <asm/segment.h>
21 #include <signal.h>
23 #define _S(nr) (1<<((nr)-1))
24 #define _BLOCKABLE (~(_S(SIGKILL) | _S(SIGSTOP)))
24 #define _BLOCKABLE (~(_S(SIGKILL) | _S(SIGSTOP)))
include/signal.h:21:#define SIGKILL 9
include/signal.h:31:#define SIGSTOP 19
不同位代表的信号意义。
不同位代表的信号意义。
继续
26 void show_task(int nr,struct task_struct * p)
27 {
28 int i,j = 4096-sizeof(struct task_struct);
29
30 printk("%d: pid=%d, state=%d, ",nr,p->pid,p->state);
31 i=0;
32 while (i<j && !((char *)(p+1))[i])
33 i++;
34 printk("%d (of %d) chars free in kernel stack\n\r",i,j);
35 }
从这里我们可以看出一个任务的内核栈是在其task_struct结构体位置上面的,二者加起来占用了一个页面4k。
27 {
28 int i,j = 4096-sizeof(struct task_struct);
29
30 printk("%d: pid=%d, state=%d, ",nr,p->pid,p->state);
31 i=0;
32 while (i<j && !((char *)(p+1))[i])
33 i++;
34 printk("%d (of %d) chars free in kernel stack\n\r",i,j);
35 }
从这里我们可以看出一个任务的内核栈是在其task_struct结构体位置上面的,二者加起来占用了一个页面4k。
这里就是打印了任务的pid,state以及栈的空闲数量。
37 void show_stat(void)
38 {
39 int i;
40
41 for (i=0;i<NR_TASKS;i++)
42 if (task[i])
43 show_task(i,task[i]);
44 }
遍历并打印任务
38 {
39 int i;
40
41 for (i=0;i<NR_TASKS;i++)
42 if (task[i])
43 show_task(i,task[i]);
44 }
遍历并打印任务
46 #define LATCH (1193180/HZ) //定时芯片的输入时钟频率
47
48 extern void mem_use(void);
49
50 extern int timer_interrupt(void); //traps.c
51 extern int system_call(void); //
53 union task_union {
54 struct task_struct task;
55 char stack[PAGE_SIZE];
56 };
这里任务数据结构与其内核栈在同一个页面
58 static union task_union init_task = {INIT_TASK,}; //定义了初始任务(任务0)
47
48 extern void mem_use(void);
49
50 extern int timer_interrupt(void); //traps.c
51 extern int system_call(void); //
53 union task_union {
54 struct task_struct task;
55 char stack[PAGE_SIZE];
56 };
这里任务数据结构与其内核栈在同一个页面
58 static union task_union init_task = {INIT_TASK,}; //定义了初始任务(任务0)
这里的INIT_TASK是一个宏定义,实际上就是初始化了task_struct的字段,为什么要手动设置呢?我们知道进程创建是通过fork调用实现的,子进程通过拷贝父进程的结构体并作其他一些操作(详细见《fork源码分析》),那么这就带来一个问题,第一个进程是怎么实现的,它没有父进程可以复制,这就是需要手动设置任务0的原因。进一步,我们知道内核可以通过调度算法来决定下一个该运行的进程,同样第一个进程是怎么被调度的呢?答案同样是手动调度的,通过指向TSS段描述符的跳转指令(ljmp)实现的。其实,schedule中调用的switch_to也是采用同样的方法实现进程切换的。
67 long user_stack [ PAGE_SIZE>>2 ] ; //
include/linux/mm.h:4:#define PAGE_SIZE 4096
69 struct {
70 long * a;
71 short b;
72 } stack_start = { & user_stack [PAGE_SIZE>>2] , 0x10 };
定义用户栈,共1k项。在内核初始化时用作内核栈。初始化完成后用作任务0和任务1的用户态栈。这个结构中的b对应SS段选择符,a对应user_stack最后一项后面的位置。
include/linux/mm.h:4:#define PAGE_SIZE 4096
69 struct {
70 long * a;
71 short b;
72 } stack_start = { & user_stack [PAGE_SIZE>>2] , 0x10 };
定义用户栈,共1k项。在内核初始化时用作内核栈。初始化完成后用作任务0和任务1的用户态栈。这个结构中的b对应SS段选择符,a对应user_stack最后一项后面的位置。
94 /*
95 * 'schedule()' is the scheduler function. This is GOOD CODE! There
96 * probably won't be any reason to change this, as it should work well
97 * in all circumstances (ie gives IO-bound processes good response etc).
98 * The one thing you might take a look at is the signal-handler code here.
99 *
100 * NOTE!! Task 0 is the 'idle' task, which gets called when no other
101 * tasks can run. It can not be killed, and it cannot sleep. The 'state'
102 * information in task[0] is never used.
103 */
104 void schedule(void)
105 {
106 int i,next,c;
107 struct task_struct ** p;
108
109 /* check alarm, wake up any interruptible tasks that have got a signal */
110
111 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
112 if (*p) {
113 if ((*p)->alarm && (*p)->alarm < jiffies) {
114 (*p)->signal |= (1<<(SIGALRM-1));
115 (*p)->alarm = 0;
116 }
95 * 'schedule()' is the scheduler function. This is GOOD CODE! There
96 * probably won't be any reason to change this, as it should work well
97 * in all circumstances (ie gives IO-bound processes good response etc).
98 * The one thing you might take a look at is the signal-handler code here.
99 *
100 * NOTE!! Task 0 is the 'idle' task, which gets called when no other
101 * tasks can run. It can not be killed, and it cannot sleep. The 'state'
102 * information in task[0] is never used.
103 */
104 void schedule(void)
105 {
106 int i,next,c;
107 struct task_struct ** p;
108
109 /* check alarm, wake up any interruptible tasks that have got a signal */
110
111 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
112 if (*p) {
113 if ((*p)->alarm && (*p)->alarm < jiffies) {
114 (*p)->signal |= (1<<(SIGALRM-1));
115 (*p)->alarm = 0;
116 }
其中include/signal.h:26:#define SIGALRM 14
这里的逻辑就是如果任务设置了alarm并且已经到时了,那么就设置它的信号位,并清除这个alarm。
这里的逻辑就是如果任务设置了alarm并且已经到时了,那么就设置它的信号位,并清除这个alarm。
117 if (((*p)->signal & ~(_BLOCKABLE & (*p)->blocked)) &&
118 (*p)->state==TASK_INTERRUPTIBLE)
119 (*p)->state=TASK_RUNNING;
120 }
逻辑是如果有信号置位并且这些置位的信号不是被阻塞掉(SIGKILL和SIGSTOP一定会考虑)同时它的状态是TASK_INTERRUPTIBLE,那么就让它处于TASK_RUNNING状态。
可以看到整个for循环就是遍历task,如果它的alarm到期就为其设置信号,如果它有信号(当然是没有被阻塞的,不过SIGKILL和SIGSTOP即使被阻塞也会考虑)而且它现在的状态是TASK_INTERRUPTIBLE,就把它设为TASK_RUNNING状态。
继续:
122 /* this is the scheduler proper: */
123
124 while (1) {
125 c = -1;
126 next = 0;
127 i = NR_TASKS;
128 p = &task[NR_TASKS];
129 while (--i) {
130 if (!*--p)
131 continue;
132 if ((*p)->state == TASK_RUNNING && (*p)->counter > c) //
133 c = (*p)->counter, next = i;
123
124 while (1) {
125 c = -1;
126 next = 0;
127 i = NR_TASKS;
128 p = &task[NR_TASKS];
129 while (--i) {
130 if (!*--p)
131 continue;
132 if ((*p)->state == TASK_RUNNING && (*p)->counter > c) //
133 c = (*p)->counter, next = i;
可以看到这里是选择剩余运行时间最多的任务
134 }
135 if (c) break;
136 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
137 if (*p)
138 (*p)->counter = ((*p)->counter >> 1) +
139 (*p)->priority;
140 }
如果有这样一种情况,所有的任务剩余运行时间都为0,那么遍历task,更新其counter为原来的一半+优先级。这样的话就会根据优先级来决定。
134 }
135 if (c) break;
136 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
137 if (*p)
138 (*p)->counter = ((*p)->counter >> 1) +
139 (*p)->priority;
140 }
如果有这样一种情况,所有的任务剩余运行时间都为0,那么遍历task,更新其counter为原来的一半+优先级。这样的话就会根据优先级来决定。
141 switch_to(next);
142 }
看一下141 switch_to(next);
142 }
看一下141 switch_to(next);
include/linux/sched.h:171:#define switch_to(n) {\
165 /*
166 * switch_to(n) should switch tasks to task nr n, first
167 * checking that n isn't the current task, in which case it does nothing.
168 * This also clears the TS-flag if the task we switched to has used
169 * tha math co-processor latest.
170 */
171 #define switch_to(n) {\
172 struct {long a,b;} __tmp; \
173 __asm__("cmpl %%ecx,_current\n\t" \
174 "je 1f\n\t" \ //如果与当前任务是同一个,跳到1:什么也不做。
175 "movw %%dx,%1\n\t" \ //获取其TSS,移到__tmp.a中
176 "xchgl %%ecx,_current\n\t" \ //_current替换为task[n]
177 "ljmp %0\n\t" \ //ljmp到__tmp.a这样就实现了任务切换
178 "cmpl %%ecx,_last_task_used_math\n\t" \
179 "jne 1f\n\t" \
180 "clts\n" \
181 "1:" \
182 ::"m" (*&__tmp.a),"m" (*&__tmp.b), \
183 "d" (_TSS(n)),"c" ((long) task[n])); \
184 }
注意真正的任务跳转是通过ljmp以目标TSS作为操作数来实现的!上面我们发现%0所引用的_tmp.a并没有进行赋值操作,_tmp.b的低16bit赋值为TSS的段选择符,然后通过ljmp %0就完成了任务切换,对此需要进行一些说明:ljmp使用内存地址作为操作数时,高16bit存放的是段选择符,低32bit存放的是offset。那么为什么这里低32bit没有赋值呢?我认为是因为offset在这里是无用的,因为TSS段描述符中指定了基地址,从该地址中我们能读到任务切换所需要的全部数据。
165 /*
166 * switch_to(n) should switch tasks to task nr n, first
167 * checking that n isn't the current task, in which case it does nothing.
168 * This also clears the TS-flag if the task we switched to has used
169 * tha math co-processor latest.
170 */
171 #define switch_to(n) {\
172 struct {long a,b;} __tmp; \
173 __asm__("cmpl %%ecx,_current\n\t" \
174 "je 1f\n\t" \ //如果与当前任务是同一个,跳到1:什么也不做。
175 "movw %%dx,%1\n\t" \ //获取其TSS,移到__tmp.a中
176 "xchgl %%ecx,_current\n\t" \ //_current替换为task[n]
177 "ljmp %0\n\t" \ //ljmp到__tmp.a这样就实现了任务切换
178 "cmpl %%ecx,_last_task_used_math\n\t" \
179 "jne 1f\n\t" \
180 "clts\n" \
181 "1:" \
182 ::"m" (*&__tmp.a),"m" (*&__tmp.b), \
183 "d" (_TSS(n)),"c" ((long) task[n])); \
184 }
注意真正的任务跳转是通过ljmp以目标TSS作为操作数来实现的!上面我们发现%0所引用的_tmp.a并没有进行赋值操作,_tmp.b的低16bit赋值为TSS的段选择符,然后通过ljmp %0就完成了任务切换,对此需要进行一些说明:ljmp使用内存地址作为操作数时,高16bit存放的是段选择符,低32bit存放的是offset。那么为什么这里低32bit没有赋值呢?我认为是因为offset在这里是无用的,因为TSS段描述符中指定了基地址,从该地址中我们能读到任务切换所需要的全部数据。
144 int sys_pause(void)
145 {
146 current->state = TASK_INTERRUPTIBLE;
147 schedule();
148 return 0;
149 }
145 {
146 current->state = TASK_INTERRUPTIBLE;
147 schedule();
148 return 0;
149 }
仅仅是重新调度。
151 void sleep_on(struct task_struct **p)
152 {
153 struct task_struct *tmp;
154
155 if (!p)
156 return;
如果p为空,直接返回;
157 if (current == &(init_task.task))
158 panic("task[0] trying to sleep");
如果是init进程,打印出错信息。init进程是一个死循环,不可以睡眠。
===×××××××××××××××××××××××××××××××××××××××===
159 tmp = *p;
160 *p = current;
159 tmp = *p;
160 *p = current;
精华就在这短短的两行代码上!!!
==============================================
161 current->state = TASK_UNINTERRUPTIBLE;
161 current->state = TASK_UNINTERRUPTIBLE;
当前任务状态设置为中断状态。
162 schedule();
进行调度。。。
163 if (tmp)
164 tmp->state=0;
163 if (tmp)
164 tmp->state=0;
设置它的状态为可运行状态。
165 }
165 }
我们顺便看一下wake_up函数
188 void wake_up(struct task_struct **p)
189 {
190 if (p && *p) {
191 (**p).state=0;
192 *p=NULL;
193 }
194 }
189 {
190 if (p && *p) {
191 (**p).state=0;
192 *p=NULL;
193 }
194 }
sleep_on一般是在一个资源上睡眠等待的。我们假设这里的p为inode的i_wait.
这两个函数的设计非常巧妙。首先sleep_on,它内部有一个tmp,对于第一个task1的tmp它指向的是i_wait,对于第二个task,它的tmp指向的则是task1,对于第三个task,它的tmp指向task2,这样就连接成了一条链,最后一个task由i_wait指向。在唤醒的时候,唤醒的是最后一个task,最后一个task然后会唤醒它的上一个task。。。最后所有的等待该资源的task都被唤醒。示意图如下:
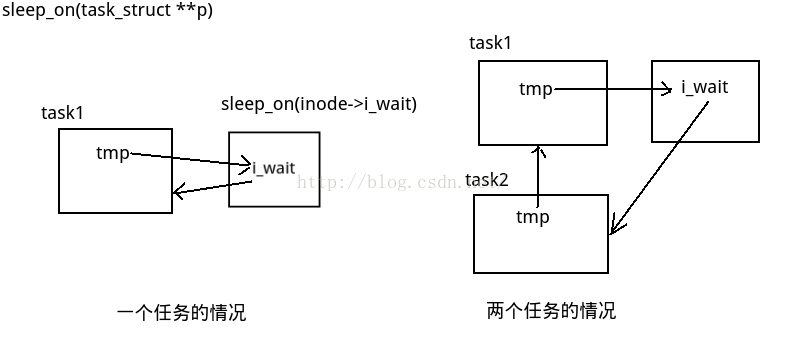
这两个函数的设计非常巧妙。首先sleep_on,它内部有一个tmp,对于第一个task1的tmp它指向的是i_wait,对于第二个task,它的tmp指向的则是task1,对于第三个task,它的tmp指向task2,这样就连接成了一条链,最后一个task由i_wait指向。在唤醒的时候,唤醒的是最后一个task,最后一个task然后会唤醒它的上一个task。。。最后所有的等待该资源的task都被唤醒。示意图如下:
继续
167 void interruptible_sleep_on(struct task_struct **p)
168 {
169 struct task_struct *tmp;
170
171 if (!p)
172 return;
173 if (current == &(init_task.task))
174 panic("task[0] trying to sleep");
168 {
169 struct task_struct *tmp;
170
171 if (!p)
172 return;
173 if (current == &(init_task.task))
174 panic("task[0] trying to sleep");
175 tmp=*p;
176 *p=current;
177 repeat: current->state = TASK_INTERRUPTIBLE;
178 schedule();
179 if (*p && *p != current) {
180 (**p).state=0;
181 goto repeat;
182 }
TASK_INTERRUPTIBLE and TASK_UNINTERRUPTIBLE。它们的惟一不同是处于TASK_UNINTERRUPTIBLE状态的进程会忽略信号,而处于 TASK_INTERRUPTIBLE状态的进程如果收到信号会被唤醒并处理信号(然后再次进入等待睡眠状态)。两种状态的进程位于同一个等待队列上,等待某些事件,不能够运行。
179行判断如果当前task前面还有任务在等待同一个资源,那么它会唤醒最后一个调用该函数(可以认为上面图示中的task2)的一个,然后自己的状态仍然设为TASK_INTERRUPTIBLE,随后执行重新调度。
关于这里的处理我目前不是很清楚,这里能执行到179行说明该task被调度了,它之所以能被调度是因为收到了信号。但是为什么180行要把p(可以考虑为上面图示中的task2)设为可运行状态呢?
183 *p=NULL;
184 if (tmp)
185 tmp->state=0;
186 }
关于这里的处理我目前不是很清楚,这里能执行到179行说明该task被调度了,它之所以能被调度是因为收到了信号。但是为什么180行要把p(可以考虑为上面图示中的task2)设为可运行状态呢?
183 *p=NULL;
184 if (tmp)
185 tmp->state=0;
186 }
继续
264 #define TIME_REQUESTS 64
265
266 static struct timer_list {
267 long jiffies;
268 void (*fn)();
269 struct timer_list * next;
270 } timer_list[TIME_REQUESTS], * next_timer = NULL;
265
266 static struct timer_list {
267 long jiffies;
268 void (*fn)();
269 struct timer_list * next;
270 } timer_list[TIME_REQUESTS], * next_timer = NULL;
比较简单,包括定时,处理函数,以及指向下一个的指针。
272 void add_timer(long jiffies, void (*fn)(void))
273 {
274 struct timer_list * p;
275
276 if (!fn)
277 return;
278 cli(); //关中断
279 if (jiffies <= 0) //如果已经到时,立刻处理
280 (fn)();
281 else {
282 for (p = timer_list ; p < timer_list + TIME_REQUESTS ; p++)
283 if (!p->fn)
284 break;
273 {
274 struct timer_list * p;
275
276 if (!fn)
277 return;
278 cli(); //关中断
279 if (jiffies <= 0) //如果已经到时,立刻处理
280 (fn)();
281 else {
282 for (p = timer_list ; p < timer_list + TIME_REQUESTS ; p++)
283 if (!p->fn)
284 break;
寻找一个没有处理函数的timer_list
285 if (p >= timer_list + TIME_REQUESTS)
286 panic("No more time requests free");
287 p->fn = fn;
288 p->jiffies = jiffies;
289 p->next = next_timer;
290 next_timer = p;
291 while (p->next && p->next->jiffies < p->jiffies) {
292 p->jiffies -= p->next->jiffies;
293 fn = p->fn;
294 p->fn = p->next->fn;
295 p->next->fn = fn;
296 jiffies = p->jiffies;
297 p->jiffies = p->next->jiffies;
298 p->next->jiffies = jiffies;
299 p = p->next;
300 }
为其在链表中寻找一个合适的位置
301 }
302 sti();
303 }
这里其实是用指针把数组中的各个timer_list链接成链。这里为什么采用这种数据结构呢?如果单纯的采用数组,每次删除一个元素,都要移动剩余元素;每次插入一个元素也要移动其他元素,挪出位置。而采用链表加数组的方式,虽然插入元素时仍然需要遍历,但是删除时可以在常量时间内完成。示意图如下:

305 void do_timer(long cpl)
306 {
307 extern int beepcount;
308 extern void sysbeepstop(void);
方法内部还可以使用extern 声明变量和方法
310 if (beepcount)
311 if (!--beepcount)
312 sysbeepstop();
313
314 if (cpl)
315 current->utime++; //utime是执行用户code的jiffies
316 else
317 current->stime++; //stime是执行系统code的jiffies
318
319 if (next_timer) {
320 next_timer->jiffies--;
321 while (next_timer && next_timer->jiffies <= 0) {
322 void (*fn)(void);
323
324 fn = next_timer->fn;
325 next_timer->fn = NULL;
326 next_timer = next_timer->next;
327 (fn)();
328 }
306 {
307 extern int beepcount;
308 extern void sysbeepstop(void);
方法内部还可以使用extern 声明变量和方法
310 if (beepcount)
311 if (!--beepcount)
312 sysbeepstop();
313
314 if (cpl)
315 current->utime++; //utime是执行用户code的jiffies
316 else
317 current->stime++; //stime是执行系统code的jiffies
318
319 if (next_timer) {
320 next_timer->jiffies--;
321 while (next_timer && next_timer->jiffies <= 0) {
322 void (*fn)(void);
323
324 fn = next_timer->fn;
325 next_timer->fn = NULL;
326 next_timer = next_timer->next;
327 (fn)();
328 }
这里就是从队列上摘除已经到时的定时器,并执行其处理函数。可见这里的定时是很不精确的。
329 }
330 if (current_DOR & 0xf0)
331 do_floppy_timer();
332 if ((--current->counter)>0) return; //如果当前进程还有剩余运行时间,直接返回
333 current->counter=0;
334 if (!cpl) return; //如果发生时钟中断时,正在内核中执行代码,则返回;
335 schedule(); //否则,重新调度
336 }
338 int sys_alarm(long seconds)
339 {
340 int old = current->alarm;
341
342 if (old)
343 old = (old - jiffies) / HZ;
344 current->alarm = (seconds>0)?(jiffies+HZ*seconds):0;
345 return (old);
346 }
改变alarm的值。
339 {
340 int old = current->alarm;
341
342 if (old)
343 old = (old - jiffies) / HZ;
344 current->alarm = (seconds>0)?(jiffies+HZ*seconds):0;
345 return (old);
346 }
改变alarm的值。
348 int sys_getpid(void)
349 {
350 return current->pid;
351 }
353 int sys_getppid(void)
354 {
355 return current->father;
356 }
358 int sys_getuid(void)
359 {
360 return current->uid;
361 }
363 int sys_geteuid(void)
364 {
365 return current->euid;
366 }
368 int sys_getgid(void)
369 {
370 return current->gid;
371 }
359 {
360 return current->uid;
361 }
363 int sys_geteuid(void)
364 {
365 return current->euid;
366 }
368 int sys_getgid(void)
369 {
370 return current->gid;
371 }
373 int sys_getegid(void)
374 {
375 return current->egid;
376 }
基本上都是直接返回task_struct的属性值。
374 {
375 return current->egid;
376 }
基本上都是直接返回task_struct的属性值。
378 int sys_nice(long increment)
379 {
380 if (current->priority-increment>0)
381 current->priority -= increment;
382 return 0;
383 }
改变task的优先级。
385 void sched_init(void)
386 {
387 int i;
388 struct desc_struct * p;
389
390 if (sizeof(struct sigaction) != 16)
391 panic("Struct sigaction MUST be 16 bytes");
392 set_tss_desc(gdt+FIRST_TSS_ENTRY,&(init_task.task.tss));
393 set_ldt_desc(gdt+FIRST_LDT_ENTRY,&(init_task.task.ldt));
394 p = gdt+2+FIRST_TSS_ENTRY;
395 for(i=1;i<NR_TASKS;i++) {
396 task[i] = NULL;
397 p->a=p->b=0;
398 p++;
399 p->a=p->b=0;
400 p++;
401 }
402 /* Clear NT, so that we won't have troubles with that later on */
403 __asm__("pushfl ; andl $0xffffbfff,(%esp) ; popfl");
404 ltr(0);
405 lldt(0);
406 outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */
407 outb_p(LATCH & 0xff , 0x40); /* LSB */
408 outb(LATCH >> 8 , 0x40); /* MSB */
409 set_intr_gate(0x20,&timer_interrupt);
410 outb(inb_p(0x21)&~0x01,0x21);
411 set_system_gate(0x80,&system_call);
412 }
之前在介绍init/main.c的源码时已经分析过了,这里不再赘述。
386 {
387 int i;
388 struct desc_struct * p;
389
390 if (sizeof(struct sigaction) != 16)
391 panic("Struct sigaction MUST be 16 bytes");
392 set_tss_desc(gdt+FIRST_TSS_ENTRY,&(init_task.task.tss));
393 set_ldt_desc(gdt+FIRST_LDT_ENTRY,&(init_task.task.ldt));
394 p = gdt+2+FIRST_TSS_ENTRY;
395 for(i=1;i<NR_TASKS;i++) {
396 task[i] = NULL;
397 p->a=p->b=0;
398 p++;
399 p->a=p->b=0;
400 p++;
401 }
402 /* Clear NT, so that we won't have troubles with that later on */
403 __asm__("pushfl ; andl $0xffffbfff,(%esp) ; popfl");
404 ltr(0);
405 lldt(0);
406 outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */
407 outb_p(LATCH & 0xff , 0x40); /* LSB */
408 outb(LATCH >> 8 , 0x40); /* MSB */
409 set_intr_gate(0x20,&timer_interrupt);
410 outb(inb_p(0x21)&~0x01,0x21);
411 set_system_gate(0x80,&system_call);
412 }
之前在介绍init/main.c的源码时已经分析过了,这里不再赘述。
2.signal.c
1 /*
2 * linux/kernel/signal.c
3 *
4 * (C) 1991 Linus Torvalds
5 */
6
7 #include <linux/sched.h>
8 #include <linux/kernel.h>
9 #include <asm/segment.h>
10
11 #include <signal.h>
2 * linux/kernel/signal.c
3 *
4 * (C) 1991 Linus Torvalds
5 */
6
7 #include <linux/sched.h>
8 #include <linux/kernel.h>
9 #include <asm/segment.h>
10
11 #include <signal.h>
13 volatile void do_exit(int error_code);
关于这里的volatile可以参考
关于这里的volatile可以参考
15 int sys_sgetmask()
16 {
17 return current->blocked;
18 }
20 int sys_ssetmask(int newmask)
21 {
22 int old=current->blocked;
23
24 current->blocked = newmask & ~(1<<(SIGKILL-1));
25 return old;
26 }
很简单,获取和设置mask。
48 struct sigaction {
49 void (*sa_handler)(int); //信号处理句柄
50 sigset_t sa_mask; //信号屏蔽码
51 int sa_flags; //信号标志
52 void (*sa_restorer)(void); //信号恢复函数指针
53 };
我们再来看一下下面要涉及到的一个函数
put_fs_byte
include/asm/segment.h
25 extern inline void put_fs_byte(char val,char *addr)
26 {
27 __asm__ ("movb %0,%%fs:%1"::"r" (val),"m" (*addr));
28 }
26 {
27 __asm__ ("movb %0,%%fs:%1"::"r" (val),"m" (*addr));
28 }
很简单可以看到就是把val写入到fs段的偏移addr的内存里面,该函数可以实现从内核空间写入到用户空间。
kernel/fork.c:24:void verify_area(void * addr, int size)
24 void verify_area(void * addr, int size)
25 {
26 unsigned long start;
27
28 start = (unsigned long) addr;
29 size += start & 0xfff;
25 {
26 unsigned long start;
27
28 start = (unsigned long) addr;
29 size += start & 0xfff;
30 start &= 0xfffff000;
31 start += get_base(current->ldt[2]);
32 while (size>0) {
33 size -= 4096;
34 write_verify(start);
35 start += 4096;
36 }
37 }
关于31行的ldt
103 /* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
104 struct desc_struct ldt[3];
因此31行的get_base得到了数据段的起始地址,加上start之后就得到了addr的线性地址
104 struct desc_struct ldt[3];
因此31行的get_base得到了数据段的起始地址,加上start之后就得到了addr的线性地址
接下来,看一下write_verify的实现:
mm/memory.c:261:void write_verify(unsigned long address)
261 void write_verify(unsigned long address)
262 {
263 unsigned long page;
264 /*判断指定地址所对应的页面目录项的页表是否存在*/
265 if (!( (page = *( (unsigned long *) ((address>>20) & 0xffc)) ) &1))
266 return;
262 {
263 unsigned long page;
264 /*判断指定地址所对应的页面目录项的页表是否存在*/
265 if (!( (page = *( (unsigned long *) ((address>>20) & 0xffc)) ) &1))
266 return;
这里需要注意的是linux0.11把页目录放在了内存的0位置开始。所以这里如果页目录项不存在,直接返回。
页目录项不存在的话直接返回,那么如果继续向这个页面写内容会发生什么情况?
267 page &= 0xfffff000;
到这里说明存在相应的页目录,那么page存储的就是页表的起始地址。
268 page += ((address>>10) & 0xffc); /*页号,page此时表示的是页表项的地址*/
269 if ((3 & *(unsigned long *) page) == 1) /* non-writeable, present */
270 un_wp_page((unsigned long *) page);//写时复制
271 return;
272 }
我们再来看一下页目录项和页表项的结构:
268 page += ((address>>10) & 0xffc); /*页号,page此时表示的是页表项的地址*/
269 if ((3 & *(unsigned long *) page) == 1) /* non-writeable, present */
270 un_wp_page((unsigned long *) page);//写时复制
271 return;
272 }
我们再来看一下页目录项和页表项的结构:

可以看到第0位是present位,表明是否在内存中。第2位是读写位。因此269行,如果&的结果是1就说明第2位是0,也就是不可写但是在内存中,这时调用270行,如果不再内存中,直接271行返回。
现在我们看一下270行,un_wp_page
mm/memory.c
221 void un_wp_page(unsigned long * table_entry)
222 {
223 unsigned long old_page,new_page;
224
225 old_page = 0xfffff000 & *table_entry;
222 {
223 unsigned long old_page,new_page;
224
225 old_page = 0xfffff000 & *table_entry;
参数是页表项的地址。
226 if (old_page >= LOW_MEM && mem_map[MAP_NR(old_page)]==1) {
227 *table_entry |= 2;
228 invalidate();
229 return;
230 }
226 if (old_page >= LOW_MEM && mem_map[MAP_NR(old_page)]==1) {
227 *table_entry |= 2;
228 invalidate();
229 return;
230 }
mm/memory.c:43:#define LOW_MEM 0x100000
226行判断如果页表是用户空间的,并且页面只被共享一次。227行直接设置页面为可写,我们来看一下invalidate():
39 #define invalidate() \
40 __asm__("movl %%eax,%%cr3"::"a" (0))
设置页目录寄存器指向内存0位置,刷新高速缓存。
40 __asm__("movl %%eax,%%cr3"::"a" (0))
设置页目录寄存器指向内存0位置,刷新高速缓存。
231 if (!(new_page=get_free_page()))
232 oom();
如果上面不成立,也就是内存页为内核空间,或者页面被多个任务共享,那么就分配一页新的内存页。如果分配不到,就oom。
233 if (old_page >= LOW_MEM)
234 mem_map[MAP_NR(old_page)]--;
233 if (old_page >= LOW_MEM)
234 mem_map[MAP_NR(old_page)]--;
分配页面后,原页面共享数减1.
235 *table_entry = new_page | 7;
235 *table_entry = new_page | 7;
设置页表项为Present,可写,用户。
236 invalidate();
236 invalidate();
刷新高速缓存。
237 copy_page(old_page,new_page);
237 copy_page(old_page,new_page);
复制一个内存页。
238 }
看一下copy_page:
238 }
看一下copy_page:
54 #define copy_page(from,to) \
55 __asm__("cld ; rep ; movsl"::"S" (from),"D" (to),"c" (1024):"cx","di","si")
55 __asm__("cld ; rep ; movsl"::"S" (from),"D" (to),"c" (1024):"cx","di","si")
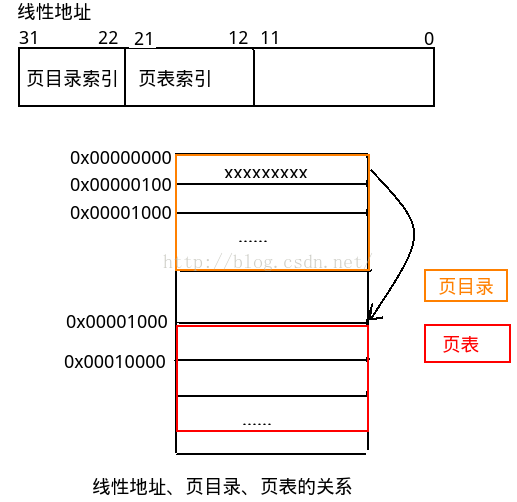
上面的过程做一个总结,当我们想要向用户空间写入数据时,并不能直接写入,因为第一页面可能不在内存中,第二,页面可能有写保护。所以这时我们就需要进行判断。首先我们需要根据提供的地址,转换为线性地址,转换方法就是获取对应的段基址(这里是从ldt数据段中获取的,而ldt是从task_struct中读取的),加上偏移形成完整的线性地址。然后根据线性地址到页目录中寻找是否存在。这里32位线性地址分为10+10+12两级页表,所以取最高10位构成页目录中的索引,又因为linux0.11,页目录起始地址为0,所以直接获取即可。如果页目录项不存在,则值为0,否则值为页表地址。获取页表地址后,再根据中间10位作为索引来查找页表项,找到页表项后,看一下它的属性,是否存在内存中,是否可写。如果不可写,那么分两种情况,如果该页面的引用计数为1,也就是只有它独自使用,那么只需设置它的属性为可写即可;如果引用计数大于1,那么就需要为它重新分配页面,并更新页表项的地址指向新的页面。
关于上面的线性地址、页目录、页表项关系图示如下(页目录项索引是4字节对齐的,页表项索引也是4字节对齐的,这是因为每个项都是4字节长):
28 static inline void save_old(char * from,char * to)
29 {
30 int i;
32 verify_area(to, sizeof(struct sigaction));
33 for (i=0 ; i< sizeof(struct sigaction) ; i++) {
34 put_fs_byte(*from,to);
35 from++;
36 to++;
37 }
38 }
把from复制到to中,从内核空间写入用户空间。
40 static inline void get_new(char * from,char * to)
41 {
42 int i;
43
44 for (i=0 ; i< sizeof(struct sigaction) ; i++)
45 *(to++) = get_fs_byte(from++);
46 }
把from复制到to中,从用户空间写入到内核空间。
48 int sys_signal(int signum, long handler, long restorer)
49 {
50 struct sigaction tmp;
51
52 if (signum<1 || signum>32 || signum==SIGKILL)
53 return -1;
54 tmp.sa_handler = (void (*)(int)) handler;
55 tmp.sa_mask = 0;
56 tmp.sa_flags = SA_ONESHOT | SA_NOMASK;
57 tmp.sa_restorer = (void (*)(void)) restorer;
58 handler = (long) current->sigaction[signum-1].sa_handler;
59 current->sigaction[signum-1] = tmp;
60 return handler;
61 }
设置新的handler,返回旧的handler。mask设置为0. flag为SA_ONESHOT | SA_NOMASK。
63 int sys_sigaction(int signum, const struct sigaction * action,
64 struct sigaction * oldaction)
65 {
66 struct sigaction tmp;
68 if (signum<1 || signum>32 || signum==SIGKILL)
69 return -1;
70 tmp = current->sigaction[signum-1];
获取当前任务对应的sigaction
71 get_new((char *) action,
72 (char *) (signum-1+current->sigaction));
把action设置到sigaction相应位置
28 static inline void save_old(char * from,char * to)
29 {
30 int i;
32 verify_area(to, sizeof(struct sigaction));
33 for (i=0 ; i< sizeof(struct sigaction) ; i++) {
34 put_fs_byte(*from,to);
35 from++;
36 to++;
37 }
38 }
把from复制到to中,从内核空间写入用户空间。
40 static inline void get_new(char * from,char * to)
41 {
42 int i;
43
44 for (i=0 ; i< sizeof(struct sigaction) ; i++)
45 *(to++) = get_fs_byte(from++);
46 }
把from复制到to中,从用户空间写入到内核空间。
48 int sys_signal(int signum, long handler, long restorer)
49 {
50 struct sigaction tmp;
51
52 if (signum<1 || signum>32 || signum==SIGKILL)
53 return -1;
54 tmp.sa_handler = (void (*)(int)) handler;
55 tmp.sa_mask = 0;
56 tmp.sa_flags = SA_ONESHOT | SA_NOMASK;
57 tmp.sa_restorer = (void (*)(void)) restorer;
58 handler = (long) current->sigaction[signum-1].sa_handler;
59 current->sigaction[signum-1] = tmp;
60 return handler;
61 }
设置新的handler,返回旧的handler。mask设置为0. flag为SA_ONESHOT | SA_NOMASK。
63 int sys_sigaction(int signum, const struct sigaction * action,
64 struct sigaction * oldaction)
65 {
66 struct sigaction tmp;
68 if (signum<1 || signum>32 || signum==SIGKILL)
69 return -1;
70 tmp = current->sigaction[signum-1];
获取当前任务对应的sigaction
71 get_new((char *) action,
72 (char *) (signum-1+current->sigaction));
把action设置到sigaction相应位置
73 if (oldaction)
74 save_old((char *) &tmp,(char *) oldaction);
把之前的action复制到oldaction
75 if (current->sigaction[signum-1].sa_flags & SA_NOMASK)
76 current->sigaction[signum-1].sa_mask = 0;
77 else
78 current->sigaction[signum-1].sa_mask |= (1<<(signum-1));
设置mask
79 return 0;
80 }
82 void do_signal(long signr,long eax, long ebx, long ecx, long edx,
83 long fs, long es, long ds,
84 long eip, long cs, long eflags,
85 unsigned long * esp, long ss)
86 {
87 unsigned long sa_handler;
88 long old_eip=eip; //中断返回后应该执行的下一条指令,备份一下
89 struct sigaction * sa = current->sigaction + signr - 1;
获得当前任务的相应信号的sigaction
90 int longs;
91 unsigned long * tmp_esp;
92
93 sa_handler = (unsigned long) sa->sa_handler;
94 if (sa_handler==1) //ignore signal
95 return;
96 if (!sa_handler) { //如果handler为NULL,default signal handling
97 if (signr==SIGCHLD)
98 return;
99 else
100 do_exit(1<<(signr-1)); //退出?
101 }
include/signal.h
45 #define SIG_DFL ((void (*)(int))0) /* default signal handling */
46 #define SIG_IGN ((void (*)(int))1) /* ignore signal */
102 if (sa->sa_flags & SA_ONESHOT)
103 sa->sa_handler = NULL;
如果是SA_ONESHOT,那么现在处理过了,所以设为NULL(也就是默认处理方式)。这里说明,如果已经处理过信号,就会被重置为默认处理方式。这在编程中需要注意。
104 *(&eip) = sa_handler;
注意在此之前已经保存了eip到oldeip中。eip指向的是中断(信号)处理完成之后返回到用户空间时的下一条执行指令的地址,现在这里把它修改为信号的处理函数,也就是中断返回后会处理我们的信号处理函数。
105 longs = (sa->sa_flags & SA_NOMASK)?7:8;
106 *(&esp) -= longs;
esp指向的是用户空间的堆栈顶端,现在扩展堆栈(7 or 8)x4个字节。
107 verify_area(esp,longs*4);
确认相应的页面可写,否则进行写时复制。
108 tmp_esp=esp;
保存esp。
109 put_fs_long((long) sa->sa_restorer,tmp_esp++);
110 put_fs_long(signr,tmp_esp++);
111 if (!(sa->sa_flags & SA_NOMASK))
112 put_fs_long(current->blocked,tmp_esp++);
为什么上面longs需要区别是8还是7就是因为这里。
113 put_fs_long(eax,tmp_esp++);
114 put_fs_long(ecx,tmp_esp++);
115 put_fs_long(edx,tmp_esp++);
116 put_fs_long(eflags,tmp_esp++);
117 put_fs_long(old_eip,tmp_esp++);
上面就是把相应的值写入到用户栈中作为函数的参数
118 current->blocked |= sa->sa_mask;
119 }
这样,当中断返回后,用户空间就会执行信号处理函数,相应的参数也已经压入用户空间。
其中do_signal是在system_call.s中调用的,如下
101 ret_from_sys_call:
.............................
118 pushl %ecx
119 call _do_signal
总结
.............................
118 pushl %ecx
119 call _do_signal
总结
简单的总结下,首先必须要知道的是结构体sigaction,它指明了信号的处理函数,信号屏蔽码以及信号标志(取值比如SA_ONESHOT,SA_NOMASK)。task_struct结构体中有一个sigaction数组,用来保存信号处理动作;还有一个block属性用于设置哪些信号被屏蔽,自然还有一个signal字段用于存储信号置位的情况。每次系统调用返回时,内核会检查该进程(current)是否有待处理的信号,方法就是根据signal中相应的位是否被置位,并且该信号没有被屏蔽。如果有信号待处理就取得它的编号以及其他一些参数来调用do_signal方法。该方法的处理方式比较独特,它并没有在内核中执行信号处理过程,而是采用了修改用户空间栈的方式。它首先修改了原eip的值使其指向信号处理句柄,使得系统调用返回后可以执行信号处理函数;接着扩展了原来的用户栈用来为信号处理函数传参和保存之前的eip。这样当信号处理函数执行完成后会跳转到之前的地方继续执行。这就好像是用户进程调用了信号处理函数一样。
整个操作过程跟内存溢出攻击很相似。关于本文中其他一些函数则主要是针对task_struct中与信号相关的一些字段,以及sigaction结构体字段的设置或获取,不再多言。
3.exit.c源码分析
1 /*
2 * linux/kernel/exit.c
3 *
4 * (C) 1991 Linus Torvalds
5 */
6
7 #include <errno.h>
8 #include <signal.h>
9 #include <sys/wait.h>
10
11 #include <linux/sched.h>
12 #include <linux/kernel.h>
13 #include <linux/tty.h>
14 #include <asm/segment.h>
2 * linux/kernel/exit.c
3 *
4 * (C) 1991 Linus Torvalds
5 */
6
7 #include <errno.h>
8 #include <signal.h>
9 #include <sys/wait.h>
10
11 #include <linux/sched.h>
12 #include <linux/kernel.h>
13 #include <linux/tty.h>
14 #include <asm/segment.h>
19 void release(struct task_struct *p)
20 {
21 int i;
23 if (!p)
24 return;
25 for (i=1 ; i<NR_TASKS ; i++)
26 if (task[i]==p) {
27 task[i]=NULL;
28 free_page((long)p);
29 schedule();
30 return;
31 }
32 panic("trying to release non-existent task");
33 }
逻辑比较简单,我们看一下free_page操作:
20 {
21 int i;
23 if (!p)
24 return;
25 for (i=1 ; i<NR_TASKS ; i++)
26 if (task[i]==p) {
27 task[i]=NULL;
28 free_page((long)p);
29 schedule();
30 return;
31 }
32 panic("trying to release non-existent task");
33 }
逻辑比较简单,我们看一下free_page操作:
mm/memory.c:89:void free_page(unsigned long addr)
85 /*
86 * Free a page of memory at physical address 'addr'. Used by
87 * 'free_page_tables()'
88 */
89 void free_page(unsigned long addr)
90 {
91 if (addr < LOW_MEM) return;
92 if (addr >= HIGH_MEMORY)
93 panic("trying to free nonexistent page");
94 addr -= LOW_MEM;
95 addr >>= 12;
96 if (mem_map[addr]--) return;
97 mem_map[addr]=0;
98 panic("trying to free free page");
99 }
内核空间不释放,不能高于最大内存。94行和95行,计算出对应的页面索引,递减引用计数。
85 /*
86 * Free a page of memory at physical address 'addr'. Used by
87 * 'free_page_tables()'
88 */
89 void free_page(unsigned long addr)
90 {
91 if (addr < LOW_MEM) return;
92 if (addr >= HIGH_MEMORY)
93 panic("trying to free nonexistent page");
94 addr -= LOW_MEM;
95 addr >>= 12;
96 if (mem_map[addr]--) return;
97 mem_map[addr]=0;
98 panic("trying to free free page");
99 }
内核空间不释放,不能高于最大内存。94行和95行,计算出对应的页面索引,递减引用计数。
这里只需要注意一点,为什么上面函数传递的是task_struct的地址,这里却根据它来释放一个页面。这是因为task_struct是存放于页面起始位置,并与任务内核栈共占一个页面的,因此这里其实也释放了对应的内核栈。
这里仅仅是释放掉了task_struct和内核栈,那么其他的进程资源在哪释放呢?
答案是在exit函数中,下面会分析。
35 static inline int send_sig(long sig,struct task_struct * p,int priv)
36 {
37 if (!p || sig<1 || sig>32)
38 return -EINVAL;
39 if (priv || (current->euid==p->euid) || suser())
40 p->signal |= (1<<(sig-1));
41 else
42 return -EPERM;
43 return 0;
44 }
设置p的信号。
36 {
37 if (!p || sig<1 || sig>32)
38 return -EINVAL;
39 if (priv || (current->euid==p->euid) || suser())
40 p->signal |= (1<<(sig-1));
41 else
42 return -EPERM;
43 return 0;
44 }
设置p的信号。
46 static void kill_session(void)
47 {
48 struct task_struct **p = NR_TASKS + task;
49
50 while (--p > &FIRST_TASK) {
51 if (*p && (*p)->session == current->session)
52 (*p)->signal |= 1<<(SIGHUP-1);
53 }
54 }
这里48行的task是task、数组的起始地址,50-53行,遍历所有task,把同一session的task设置SIGHUP信号
47 {
48 struct task_struct **p = NR_TASKS + task;
49
50 while (--p > &FIRST_TASK) {
51 if (*p && (*p)->session == current->session)
52 (*p)->signal |= 1<<(SIGHUP-1);
53 }
54 }
这里48行的task是task、数组的起始地址,50-53行,遍历所有task,把同一session的task设置SIGHUP信号
56 /*
57 * XXX need to check permissions needed to send signals to process
58 * groups, etc. etc. kill() permissions semantics are tricky!
59 */
60 int sys_kill(int pid,int sig)
61 {
62 struct task_struct **p = NR_TASKS + task;
63 int err, retval = 0;
64
65 if (!pid) while (--p > &FIRST_TASK) {
66 if (*p && (*p)->pgrp == current->pid)
67 if (err=send_sig(sig,*p,1))
68 retval = err;
69 } else if (pid>0) while (--p > &FIRST_TASK) {
70 if (*p && (*p)->pid == pid) //这里会检查权限
71 if (err=send_sig(sig,*p,0))
72 retval = err;
73 } else if (pid == -1) while (--p > &FIRST_TASK)
74 if (err = send_sig(sig,*p,0))
75 retval = err;
76 else while (--p > &FIRST_TASK)
77 if (*p && (*p)->pgrp == -pid)
78 if (err = send_sig(sig,*p,0))
79 retval = err;
80 return retval;
81 }
可以看到这里会有pid为负数和0的情况,首先看pid=0的情况,这时通过66行我们知道,它要kill的是以当前任务作为组长的所有任务;pid大于0,kill的就是特定pid的任务;pid==-1,74可以看到是kill任何任务;pid<0,77行可以看到,这时kill的是属于-pid组的任务。
57 * XXX need to check permissions needed to send signals to process
58 * groups, etc. etc. kill() permissions semantics are tricky!
59 */
60 int sys_kill(int pid,int sig)
61 {
62 struct task_struct **p = NR_TASKS + task;
63 int err, retval = 0;
64
65 if (!pid) while (--p > &FIRST_TASK) {
66 if (*p && (*p)->pgrp == current->pid)
67 if (err=send_sig(sig,*p,1))
68 retval = err;
69 } else if (pid>0) while (--p > &FIRST_TASK) {
70 if (*p && (*p)->pid == pid) //这里会检查权限
71 if (err=send_sig(sig,*p,0))
72 retval = err;
73 } else if (pid == -1) while (--p > &FIRST_TASK)
74 if (err = send_sig(sig,*p,0))
75 retval = err;
76 else while (--p > &FIRST_TASK)
77 if (*p && (*p)->pgrp == -pid)
78 if (err = send_sig(sig,*p,0))
79 retval = err;
80 return retval;
81 }
可以看到这里会有pid为负数和0的情况,首先看pid=0的情况,这时通过66行我们知道,它要kill的是以当前任务作为组长的所有任务;pid大于0,kill的就是特定pid的任务;pid==-1,74可以看到是kill任何任务;pid<0,77行可以看到,这时kill的是属于-pid组的任务。
83 static void tell_father(int pid)
84 {
85 int i;
86
87 if (pid)
88 for (i=0;i<NR_TASKS;i++) {
89 if (!task[i])
90 continue;
91 if (task[i]->pid != pid)
92 continue;
93 task[i]->signal |= (1<<(SIGCHLD-1));
94 return;
95 }
84 {
85 int i;
86
87 if (pid)
88 for (i=0;i<NR_TASKS;i++) {
89 if (!task[i])
90 continue;
91 if (task[i]->pid != pid)
92 continue;
93 task[i]->signal |= (1<<(SIGCHLD-1));
94 return;
95 }
很简单就是告诉(置位其SIGCHLD)指定pid的father。
96 /* if we don't find any fathers, we just release ourselves */
97 /* This is not really OK. Must change it to make father 1 */
98 printk("BAD BAD - no father found\n\r");
99 release(current);
100 }
96 /* if we don't find any fathers, we just release ourselves */
97 /* This is not really OK. Must change it to make father 1 */
98 printk("BAD BAD - no father found\n\r");
99 release(current);
100 }
137 int sys_exit(int error_code)
138 {
139 return do_exit((error_code&0xff)<<8);
140 }
138 {
139 return do_exit((error_code&0xff)<<8);
140 }
102 int do_exit(long code)
103 {
104 int i;
105
106 free_page_tables(get_base(current->ldt[1]),get_limit(0x0f));
107 free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
103 {
104 int i;
105
106 free_page_tables(get_base(current->ldt[1]),get_limit(0x0f));
107 free_page_tables(get_base(current->ldt[2]),get_limit(0x17));
进程退出时,肯定是要释放页表的。在分析释放页表操作之前我们先来看一下get_limit操作:
include/linux/sched.h:228:#define get_limit(segment) ({ \
228 #define get_limit(segment) ({ \
229 unsigned long __limit; \
230 __asm__("lsll %1,%0\n\tincl %0":"=r" (__limit):"r" (segment)); \
231 __limit;})
lsll 是加载段界限的指令,即把 segment 段描述符中的段界限字段装入某个寄存器(这个寄存器与__limit 结合),函数返回__limit 加 1,即段长。
228 #define get_limit(segment) ({ \
229 unsigned long __limit; \
230 __asm__("lsll %1,%0\n\tincl %0":"=r" (__limit):"r" (segment)); \
231 __limit;})
lsll 是加载段界限的指令,即把 segment 段描述符中的段界限字段装入某个寄存器(这个寄存器与__limit 结合),函数返回__limit 加 1,即段长。
因此这里0x0f获取的就是代码段的段长,get_base得到的则是代码段的基地址。
0x17获取的就是局部描述符表中数据段的段长。
1.get_limit返回的段长是最大长度,实际使用的要比它小,这会不会影响其他后面的程序?
先思考一下这个问题,后面的给出了回答。
我们看这里具体是怎么操作的:
mm/memory.c
101 /*
102 * This function frees a continuos block of page tables, as needed
103 * by 'exit()'. As does copy_page_tables(), this handles only 4Mb blocks.
104 */
105 int free_page_tables(unsigned long from,unsigned long size)
106 {
107 unsigned long *pg_table;
108 unsigned long * dir, nr;
110 if (from & 0x3fffff)
111 panic("free_page_tables called with wrong alignment");
102 * This function frees a continuos block of page tables, as needed
103 * by 'exit()'. As does copy_page_tables(), this handles only 4Mb blocks.
104 */
105 int free_page_tables(unsigned long from,unsigned long size)
106 {
107 unsigned long *pg_table;
108 unsigned long * dir, nr;
110 if (from & 0x3fffff)
111 panic("free_page_tables called with wrong alignment");
112 if (!from)
113 panic("Trying to free up swapper memory space");
114 size = (size + 0x3fffff) >> 22;
除以4M,也就是看一下需要释放的空间大小有几个4M大小
115 dir = (unsigned long *) ((from>>20) & 0xffc); /* _pg_dir = 0 */
取得页目录项,注意一个页目录项映射4M地址空间
116 for ( ; size-->0 ; dir++) {
117 if (!(1 & *dir)) //没有页目录项
118 continue;
119 pg_table = (unsigned long *) (0xfffff000 & *dir);
取得页表地址
120 for (nr=0 ; nr<1024 ; nr++) {
121 if (1 & *pg_table) //如果页表中页表项为空,则不释放
122 free_page(0xfffff000 & *pg_table);
释放页表项对应的内存页(这里参数是线性地址)
123 *pg_table = 0;
124 pg_table++;
125 }
126 free_page(0xfffff000 & *dir); //释放完页表后,释放页目录项
127 *dir = 0;
128 }
129 invalidate(); //刷新缓存
130 return 0;
131 }
这个函数完成了释放页目录,页表,页面的操作
现在我们可以回答上面的问题了,肯定不会影响其它进程。要注意一个进程的代码占用的空间是页面的整数倍,每个页面都会在页表中进行登记,其他的进程的内存页是不会出现在该进程中的页表中的,未使用的内存也不会出现在页表中,所以不会影响其他进程。
继续分析exit函数,上面已经释放了它的页表,以及物理内存页。
108 for (i=0 ; i<NR_TASKS ; i++)
109 if (task[i] && task[i]->father == current->pid) {
110 task[i]->father = 1;
111 if (task[i]->state == TASK_ZOMBIE)
112 /* assumption task[1] is always init */
113 (void) send_sig(SIGCHLD, task[1], 1);
114 }
这里如果该进程退出后,它还有子进程,就把子进程托付给init进程(“托孤”),如果子进程的状态为僵死状态,就向init进程发送SIGCHLD信号。
108 for (i=0 ; i<NR_TASKS ; i++)
109 if (task[i] && task[i]->father == current->pid) {
110 task[i]->father = 1;
111 if (task[i]->state == TASK_ZOMBIE)
112 /* assumption task[1] is always init */
113 (void) send_sig(SIGCHLD, task[1], 1);
114 }
这里如果该进程退出后,它还有子进程,就把子进程托付给init进程(“托孤”),如果子进程的状态为僵死状态,就向init进程发送SIGCHLD信号。
115 for (i=0 ; i<NR_OPEN ; i++)
116 if (current->filp[i])
117 sys_close(i);
关闭打开文件。
116 if (current->filp[i])
117 sys_close(i);
关闭打开文件。
118 iput(current->pwd);
119 current->pwd=NULL;
120 iput(current->root);
121 current->root=NULL;
122 iput(current->executable);
123 current->executable=NULL;
119 current->pwd=NULL;
120 iput(current->root);
121 current->root=NULL;
122 iput(current->executable);
123 current->executable=NULL;
释放inode节点
124 if (current->leader && current->tty >= 0)
125 tty_table[current->tty].pgrp = 0;
126 if (last_task_used_math == current)
127 last_task_used_math = NULL;
128 if (current->leader)
129 kill_session();
如果当前进程是leader进程,则kill同一会话中所有进程。
130 current->state = TASK_ZOMBIE;
状态也设置为僵死状态
131 current->exit_code = code;
保存退出码
132 tell_father(current->father);
132 tell_father(current->father);
向父进程发送SIGCHLD信号
133 schedule();
133 schedule();
重新调度
134 return (-1); /* just to suppress warnings */
135 }
134 return (-1); /* just to suppress warnings */
135 }
142 int sys_waitpid(pid_t pid,unsigned long * stat_addr, int options)
143 {
144 int flag, code;
145 struct task_struct ** p;
146
147 verify_area(stat_addr,4);
143 {
144 int flag, code;
145 struct task_struct ** p;
146
147 verify_area(stat_addr,4);
确认相应的用户空间页面可写
148 repeat:
149 flag=0;
150 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) {
151 if (!*p || *p == current)
152 continue;
153 if ((*p)->father != current->pid)
154 continue;
155 if (pid>0) {
156 if ((*p)->pid != pid)
157 continue;
158 } else if (!pid) {
159 if ((*p)->pgrp != current->pgrp)
160 continue;
161 } else if (pid != -1) {
162 if ((*p)->pgrp != -pid)
163 continue;
164 }
如果pid>0,就等待相应的pid;如果pid=0,等待跟当前进程pid同一组的所有进程;如果为负值,就等待组id为-pid的所有进程
165 switch ((*p)->state) {
166 case TASK_STOPPED:
167 if (!(options & WUNTRACED)) //如果设置了WUNTRACED,就返回;否则遍历其他的
168 continue;
169 put_fs_long(0x7f,stat_addr);
170 return (*p)->pid;
171 case TASK_ZOMBIE:
172 current->cutime += (*p)->utime;
173 current->cstime += (*p)->stime;
更新运行时间
174 flag = (*p)->pid;
175 code = (*p)->exit_code;
176 release(*p);
保存pid,exit_code并释放该task
177 put_fs_long(code,stat_addr);
向用户空间写入退出码
178 return flag;
返回task的pid
179 default:
180 flag=1;
181 continue;
182 }
183 }
184 if (flag) { //处于睡眠或者可运行状态
185 if (options & WNOHANG) //如果设置了WNOHANG,直接退出(也就是不等待它)
186 return 0;
187 current->state=TASK_INTERRUPTIBLE;
188 schedule();
189 if (!(current->signal &= ~(1<<(SIGCHLD-1)))) //如果没有收到除SIGCHLD以外的信号,就重新等待
190 goto repeat;
191 else
192 return -EINTR; //如果收到了其他信号就返回-EINTR
193 }
如果没有找到符合要求的子进程,则返回 -ECHILD。
194 return -ECHILD;
195 }
148 repeat:
149 flag=0;
150 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) {
151 if (!*p || *p == current)
152 continue;
153 if ((*p)->father != current->pid)
154 continue;
155 if (pid>0) {
156 if ((*p)->pid != pid)
157 continue;
158 } else if (!pid) {
159 if ((*p)->pgrp != current->pgrp)
160 continue;
161 } else if (pid != -1) {
162 if ((*p)->pgrp != -pid)
163 continue;
164 }
如果pid>0,就等待相应的pid;如果pid=0,等待跟当前进程pid同一组的所有进程;如果为负值,就等待组id为-pid的所有进程
165 switch ((*p)->state) {
166 case TASK_STOPPED:
167 if (!(options & WUNTRACED)) //如果设置了WUNTRACED,就返回;否则遍历其他的
168 continue;
169 put_fs_long(0x7f,stat_addr);
170 return (*p)->pid;
171 case TASK_ZOMBIE:
172 current->cutime += (*p)->utime;
173 current->cstime += (*p)->stime;
更新运行时间
174 flag = (*p)->pid;
175 code = (*p)->exit_code;
176 release(*p);
保存pid,exit_code并释放该task
177 put_fs_long(code,stat_addr);
向用户空间写入退出码
178 return flag;
返回task的pid
179 default:
180 flag=1;
181 continue;
182 }
183 }
184 if (flag) { //处于睡眠或者可运行状态
185 if (options & WNOHANG) //如果设置了WNOHANG,直接退出(也就是不等待它)
186 return 0;
187 current->state=TASK_INTERRUPTIBLE;
188 schedule();
189 if (!(current->signal &= ~(1<<(SIGCHLD-1)))) //如果没有收到除SIGCHLD以外的信号,就重新等待
190 goto repeat;
191 else
192 return -EINTR; //如果收到了其他信号就返回-EINTR
193 }
如果没有找到符合要求的子进程,则返回 -ECHILD。
194 return -ECHILD;
195 }
总结
主要是与进程退出相关的一些操作。进程退出了,其task_struct便不再需要,根据前面的文章,我们已经知道,task_struct在一页内存的起始位置处,该页内存剩余内容则作为内核栈,现在进程退出了,这个内存页也可以释放了,释放操作就是递减mem_map中对应的引用计数。我们还知道一个进程相关的资源有很多,比如页表,打开文件等,现在这些资源也都可以释放了,页表的释放过程前面的文章也已经分析过;进一步还需要看一下该进程是否有子进程,如果有就需要将它们托付给init进程,而且如果子进程处于僵死状态就向init进程发送SIGCHLD信号;对打开文件进行关闭操作,设置根目录,工作目录为NULL等并向父进程发送SIGCHLD信号,最后调度其他进程运行。对于sys_waitpid操作,根据pid的正负还是0,pid代表不同的意义,比如pid==0时,表示等待与当前进程同一组的进程退出,pid<0时则表示等待组id为-pid的进程退出,找到满足条件的进程后根据其不同的状态向用户空间写入不同的状态码并返回。
4.sys.c源码分析
1 /*
2 * linux/kernel/sys.c
3 *
4 * (C) 1991 Linus Torvalds
5 */
7 #include <errno.h>
9 #include <linux/sched.h>
10 #include <linux/tty.h>
11 #include <linux/kernel.h>
12 #include <asm/segment.h>
13 #include <sys/times.h>
14 #include <sys/utsname.h>
2 * linux/kernel/sys.c
3 *
4 * (C) 1991 Linus Torvalds
5 */
7 #include <errno.h>
9 #include <linux/sched.h>
10 #include <linux/tty.h>
11 #include <linux/kernel.h>
12 #include <asm/segment.h>
13 #include <sys/times.h>
14 #include <sys/utsname.h>
16 int sys_ftime()
17 {
18 return -ENOSYS;
19 }
21 int sys_break()
22 {
23 return -ENOSYS;
24 }
25
26 int sys_ptrace()
27 {
28 return -ENOSYS;
29 }
30
31 int sys_stty()
32 {
33 return -ENOSYS;
34 }
35
36 int sys_gtty()
37 {
38 return -ENOSYS;
39 }
41 int sys_rename()
42 {
43 return -ENOSYS;
44 }
45
46 int sys_prof()
47 {
48 return -ENOSYS;
49 }
上面返回-ENOSYS的函数是还没有实现的。
51 int sys_setregid(int rgid, int egid)
52 {
53 if (rgid>0) {
54 if ((current->gid == rgid) ||
55 suser())
56 current->gid = rgid;
57 else
58 return(-EPERM);
59 }
52 {
53 if (rgid>0) {
54 if ((current->gid == rgid) ||
55 suser())
56 current->gid = rgid;
57 else
58 return(-EPERM);
59 }
56行执行的条件是current的组id与即将要设置的组id一致。如果不一致需要超级用户权限。否则退出。
60 if (egid>0) {
61 if ((current->gid == egid) ||
62 (current->egid == egid) ||
63 (current->sgid == egid) ||
64 suser())
65 current->egid = egid;
66 else
67 return(-EPERM);
68 }
61 if ((current->gid == egid) ||
62 (current->egid == egid) ||
63 (current->sgid == egid) ||
64 suser())
65 current->egid = egid;
66 else
67 return(-EPERM);
68 }
只要被设置的有效组id与目前task的组id或者有效组id或者sgid相等或者虽然不相等但是超级用户,就可以设置egid。否则退出。
69 return 0;
70 }
70 }
72 int sys_setgid(int gid)
73 {
74 return(sys_setregid(gid, gid));
75 }
73 {
74 return(sys_setregid(gid, gid));
75 }
有效组id与组id一致。
77 int sys_acct()
78 {
79 return -ENOSYS;
80 }
82 int sys_phys()
83 {
84 return -ENOSYS;
85 }
86
87 int sys_lock()
88 {
89 return -ENOSYS;
90 }
91
92 int sys_mpx()
93 {
94 return -ENOSYS;
95 }
97 int sys_ulimit()
98 {
99 return -ENOSYS;
100 }
102 int sys_time(long * tloc)
103 {
104 int i;
105
106 i = CURRENT_TIME;
107 if (tloc) {
108 verify_area(tloc,4);
109 put_fs_long(i,(unsigned long *)tloc);
110 }
111 return i;
112 }
把当前时间写入用户空间。
114 /*
115 * Unprivileged users may change the real user id to the effective uid
116 * or vice versa.
117 */
118 int sys_setreuid(int ruid, int euid)
119 {
120 int old_ruid = current->uid;
121
122 if (ruid>0) {
123 if ((current->euid==ruid) ||
124 (old_ruid == ruid) ||
125 suser())
126 current->uid = ruid;
127 else
128 return(-EPERM);
129 }
130 if (euid>0) {
131 if ((old_ruid == euid) ||
132 (current->euid == euid) ||
133 suser())
134 current->euid = euid;
135 else {
136 current->uid = old_ruid;
137 return(-EPERM);
138 }
139 }
140 return 0;
141 }
115 * Unprivileged users may change the real user id to the effective uid
116 * or vice versa.
117 */
118 int sys_setreuid(int ruid, int euid)
119 {
120 int old_ruid = current->uid;
121
122 if (ruid>0) {
123 if ((current->euid==ruid) ||
124 (old_ruid == ruid) ||
125 suser())
126 current->uid = ruid;
127 else
128 return(-EPERM);
129 }
130 if (euid>0) {
131 if ((old_ruid == euid) ||
132 (current->euid == euid) ||
133 suser())
134 current->euid = euid;
135 else {
136 current->uid = old_ruid;
137 return(-EPERM);
138 }
139 }
140 return 0;
141 }
143 int sys_setuid(int uid)
144 {
145 return(sys_setreuid(uid, uid));
146 }
144 {
145 return(sys_setreuid(uid, uid));
146 }
设置用户id,eid与id相等。
148 int sys_stime(long * tptr)
149 {
150 if (!suser())
151 return -EPERM;
152 startup_time = get_fs_long((unsigned long *)tptr) - jiffies/HZ;
153 return 0;
154 }
设置启动时间,用户提供的时间-开机到目前的时间。
156 int sys_times(struct tms * tbuf)
157 {
158 if (tbuf) {
159 verify_area(tbuf,sizeof *tbuf);
160 put_fs_long(current->utime,(unsigned long *)&tbuf->tms_utime);
161 put_fs_long(current->stime,(unsigned long *)&tbuf->tms_stime);
162 put_fs_long(current->cutime,(unsigned long *)&tbuf->tms_cutime);
163 put_fs_long(current->cstime,(unsigned long *)&tbuf->tms_cstime);
164 }
165 return jiffies;
166 }
157 {
158 if (tbuf) {
159 verify_area(tbuf,sizeof *tbuf);
160 put_fs_long(current->utime,(unsigned long *)&tbuf->tms_utime);
161 put_fs_long(current->stime,(unsigned long *)&tbuf->tms_stime);
162 put_fs_long(current->cutime,(unsigned long *)&tbuf->tms_cutime);
163 put_fs_long(current->cstime,(unsigned long *)&tbuf->tms_cstime);
164 }
165 return jiffies;
166 }
把current的相应times写入用户空间(current是在内核空间的)
168 int sys_brk(unsigned long end_data_seg)
169 {
170 if (end_data_seg >= current->end_code &&
171 end_data_seg < current->start_stack - 16384)
172 current->brk = end_data_seg;
173 return current->brk;
174 }
设置brk。
176 /*
177 * This needs some heave checking ...
178 * I just haven't get the stomach for it. I also don't fully
179 * understand sessions/pgrp etc. Let somebody who does explain it.
180 */
181 int sys_setpgid(int pid, int pgid)
182 {
183 int i;
184
185 if (!pid)
186 pid = current->pid;
187 if (!pgid)
188 pgid = current->pid;
189 for (i=0 ; i<NR_TASKS ; i++)
190 if (task[i] && task[i]->pid==pid) {
191 if (task[i]->leader)
192 return -EPERM;
193 if (task[i]->session != current->session)
194 return -EPERM;
195 task[i]->pgrp = pgid;
196 return 0;
197 }
198 return -ESRCH;
199 }
177 * This needs some heave checking ...
178 * I just haven't get the stomach for it. I also don't fully
179 * understand sessions/pgrp etc. Let somebody who does explain it.
180 */
181 int sys_setpgid(int pid, int pgid)
182 {
183 int i;
184
185 if (!pid)
186 pid = current->pid;
187 if (!pgid)
188 pgid = current->pid;
189 for (i=0 ; i<NR_TASKS ; i++)
190 if (task[i] && task[i]->pid==pid) {
191 if (task[i]->leader)
192 return -EPERM;
193 if (task[i]->session != current->session)
194 return -EPERM;
195 task[i]->pgrp = pgid;
196 return 0;
197 }
198 return -ESRCH;
199 }
为pid设置组id。
201 int sys_getpgrp(void)
202 {
203 return current->pgrp;
204 }
205
206 int sys_setsid(void)
207 {
208 if (current->leader && !suser())
209 return -EPERM;
210 current->leader = 1;
211 current->session = current->pgrp = current->pid;
212 current->tty = -1;
213 return current->pgrp;
214 }
如果当前进程是组长但是不是超级用户,那么没有权限,返回。否则,把当前进程设为组长,组id和session统一设为进程id,返回组id。
202 {
203 return current->pgrp;
204 }
205
206 int sys_setsid(void)
207 {
208 if (current->leader && !suser())
209 return -EPERM;
210 current->leader = 1;
211 current->session = current->pgrp = current->pid;
212 current->tty = -1;
213 return current->pgrp;
214 }
如果当前进程是组长但是不是超级用户,那么没有权限,返回。否则,把当前进程设为组长,组id和session统一设为进程id,返回组id。
216 int sys_uname(struct utsname * name)
217 {
218 static struct utsname thisname = {
219 "linux .0","nodename","release ","version ","machine "
220 };
221 int i;
222
223 if (!name) return -ERROR;
224 verify_area(name,sizeof *name);
225 for(i=0;i<sizeof *name;i++)
226 put_fs_byte(((char *) &thisname)[i],i+(char *) name);
227 return 0;
228 }
把数组信息写入用户空间
217 {
218 static struct utsname thisname = {
219 "linux .0","nodename","release ","version ","machine "
220 };
221 int i;
222
223 if (!name) return -ERROR;
224 verify_area(name,sizeof *name);
225 for(i=0;i<sizeof *name;i++)
226 put_fs_byte(((char *) &thisname)[i],i+(char *) name);
227 return 0;
228 }
把数组信息写入用户空间
230 int sys_umask(int mask)
231 {
232 int old = current->umask;
234 current->umask = mask & 0777;
235 return (old);
236 }
设置新的mask,返回以前的mask
231 {
232 int old = current->umask;
234 current->umask = mask & 0777;
235 return (old);
236 }
设置新的mask,返回以前的mask
总结
内容都比较简单,留意一下uid与euid,gid与egid的区别,还有就是umask,这是权限补码,也就是当我们创建一个文件的时候默认的权限补码。最后注意一下put_fs_*函数,它实现了从内核空间到用户空间的数据传递,方法是使用fs段寄存器指向用户空间数据段。















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









