









本人学习记录,侵删,转载请署名
基础优化
w = w + Δ w w\,\,=\,\,w\,\,+\,\,\varDelta \,\,w w=w+Δw
花书第8章Optimization for Training Deep Models中对机器学习中的优化器有如下定义:
finding the parameters θ \theta θ of a neural network that significantly reduce a cost function J ( θ ) J(\theta) J(θ) ,
which typically includes a performance measure evaluated on the entire training set as well as additional regularization terms
1. GD — 梯度下降
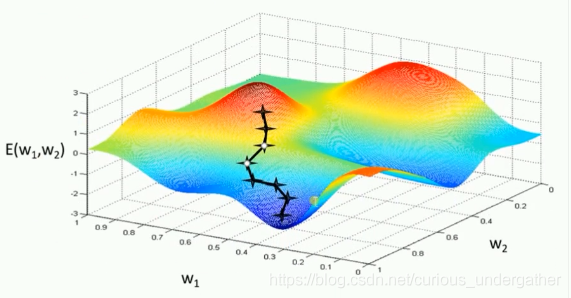
1.1 BGD — 批量梯度下降
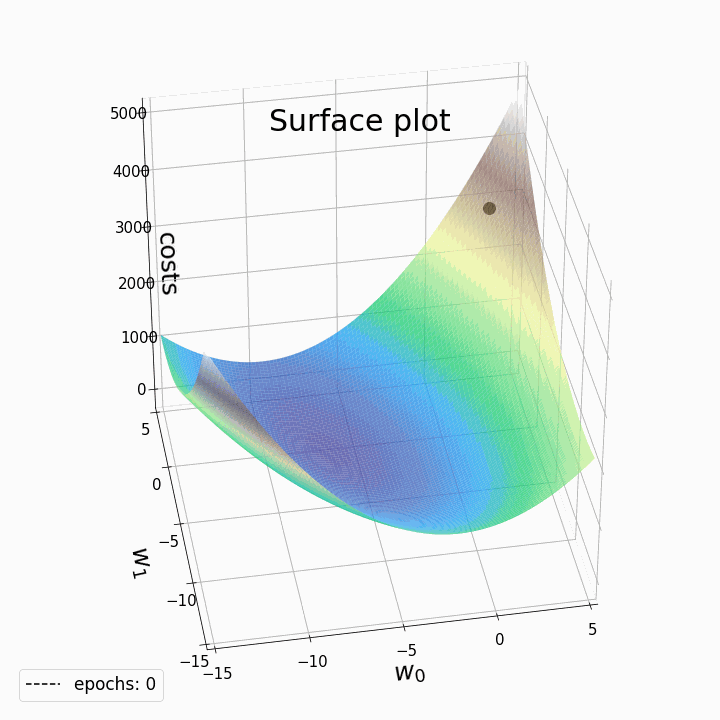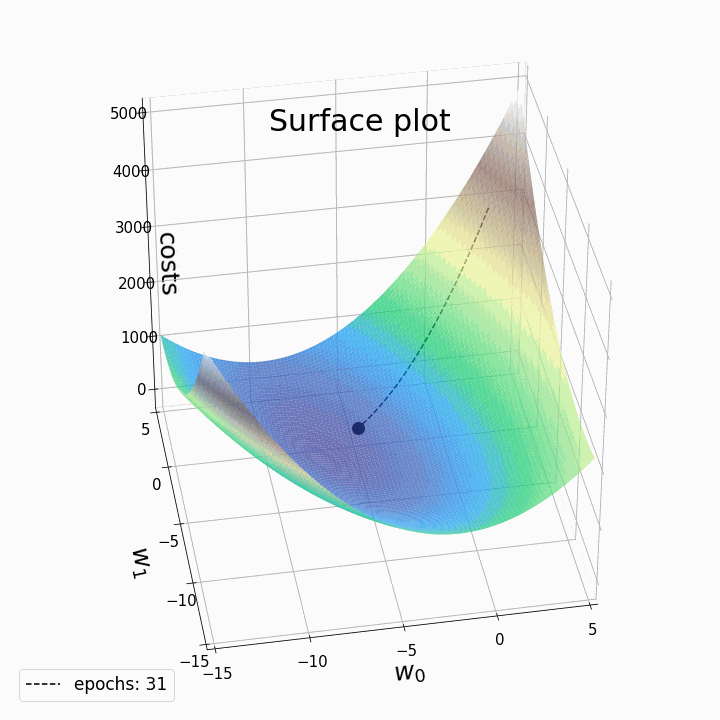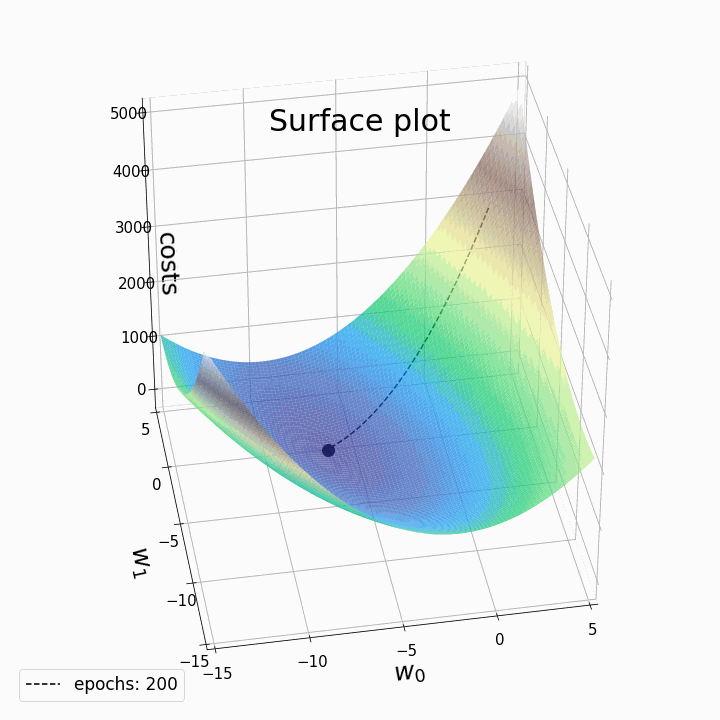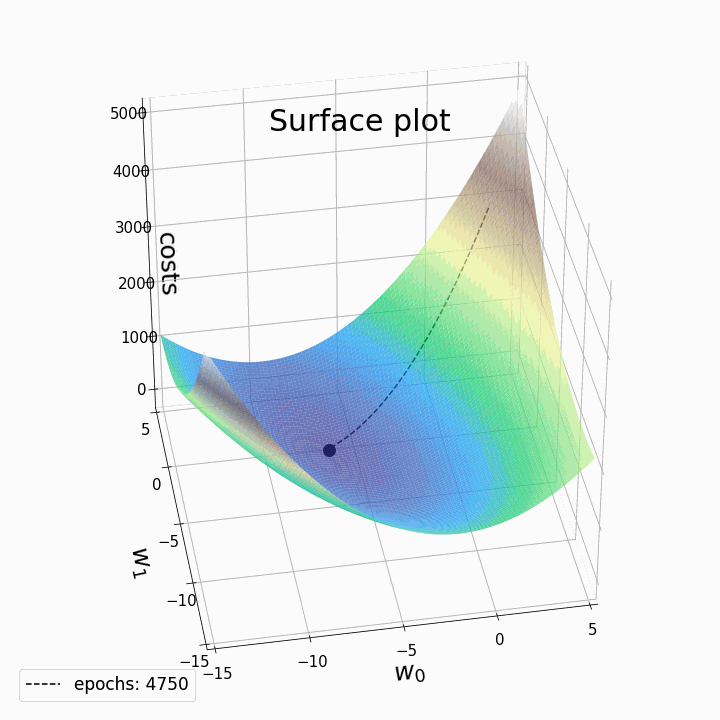
BGD(Batch Gradient Descent) 在求解梯度时一次性的将整个数据集进行迭代,从而计算出平均的梯度用于参数的更新
w i + 1 = w − η 1 m ∑ j = 0 m ∂ C ∂ w j w_{i+1}=w-\eta \frac{1}{m}\sum_{j=0}^m{\frac{\partial C}{\partial w}_j} wi+1=w−ηm1j=0∑m∂w∂Cj
m m m 为数据量数, C C C 为损失函数
优势 — 每次迭代均会往最优化的方向跑,且由于考虑到整个数据集,下降时不会出现震荡
劣势 — 每次优化需遍历整个数据集,时间空间消耗巨大, 血亏
代码
1.2 SGD — 随机梯度下降
SGD(Stochastic Gradient Descent)— 在每次求解梯度时仅从数据集中随机的选取一个数据点进行梯度计算,从而更新参数
Δ
w
=
−
η
J
′
(
w
)
或
w
i
+
1
=
w
−
η
∂
C
∂
w
\Delta w=-\eta J^{\prime}(w) 或 w_{i+1}=w-\eta \frac{\partial C}{\partial w}
Δw=−ηJ′(w)或wi+1=w−η∂w∂C
η
\eta
η 指学习率,
J
′
J^{\prime}
J′ 指损失关于参数的梯度 (
∇
w
J
(
w
)
\nabla_{w} J(w)
∇wJ(w) 也有这种形式)
C
C
C 为损失函数
其中每次用于更新的数据量为1
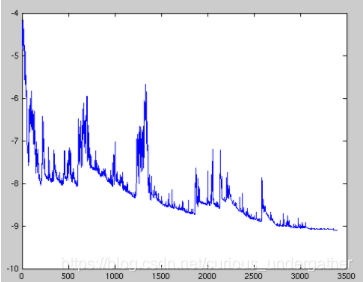
优势 — 优化的速度很快
劣势 — 数据中会存在噪音,使得优化朝着并不是最优的方向而迭代. 且还可能使得训练的准确率降低. 但总体还是朝着优化的方向前进的
代码
1.3 MBGD — 小批量梯度下降
w = w − η ⋅ ∇ w J ( w ; x ( i : i + n ) ; y ( i : i + n ) ) w=w-\eta \cdot \nabla _wJ\left( w;x^{(i:i+n)};y^{(i:i+n)} \right) w=w−η⋅∇wJ(w;x(i:i+n);y(i:i+n))
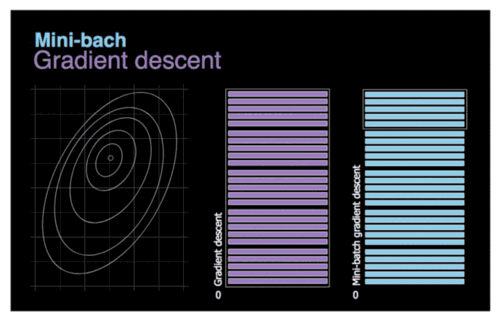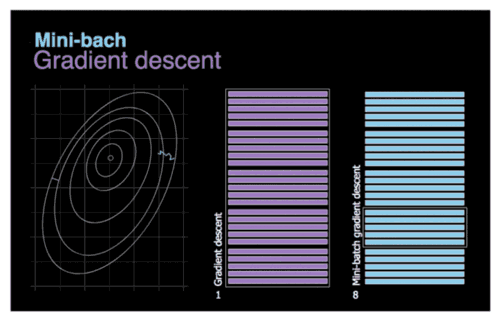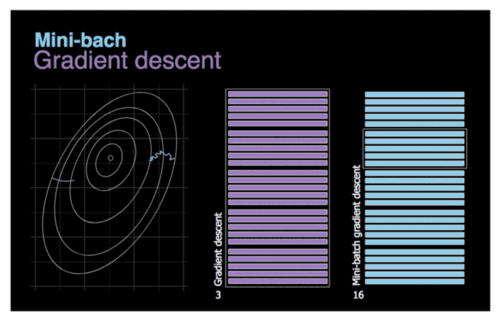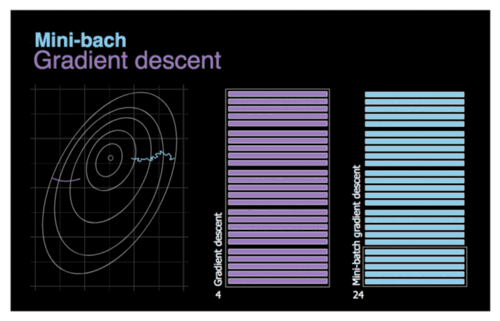
MBGD(Mini-Batch Gradient Descent)将BGD和SGD求一个折中的办法,每次从数据集中选取一小部分的数据进行计算梯度
优势 — 加快梯度下降的迭代速度, 降低数据集中单一噪音数据点对优化的影响
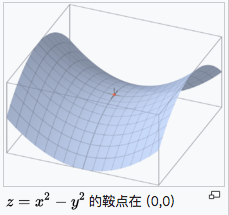
劣势 — 对于鞍点, SGD会在鞍点附近停止更新, 而MSGD会在鞍点周围来回震荡
代码
2. Momentum
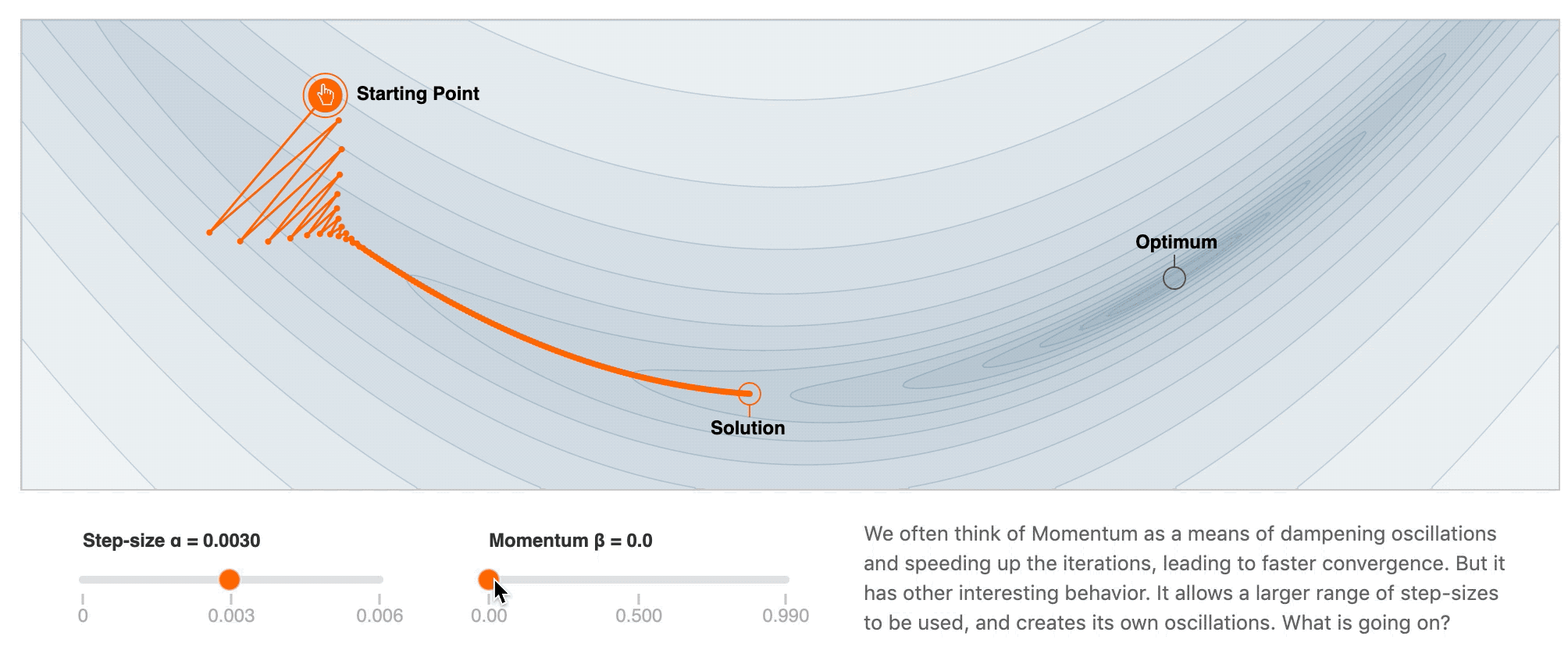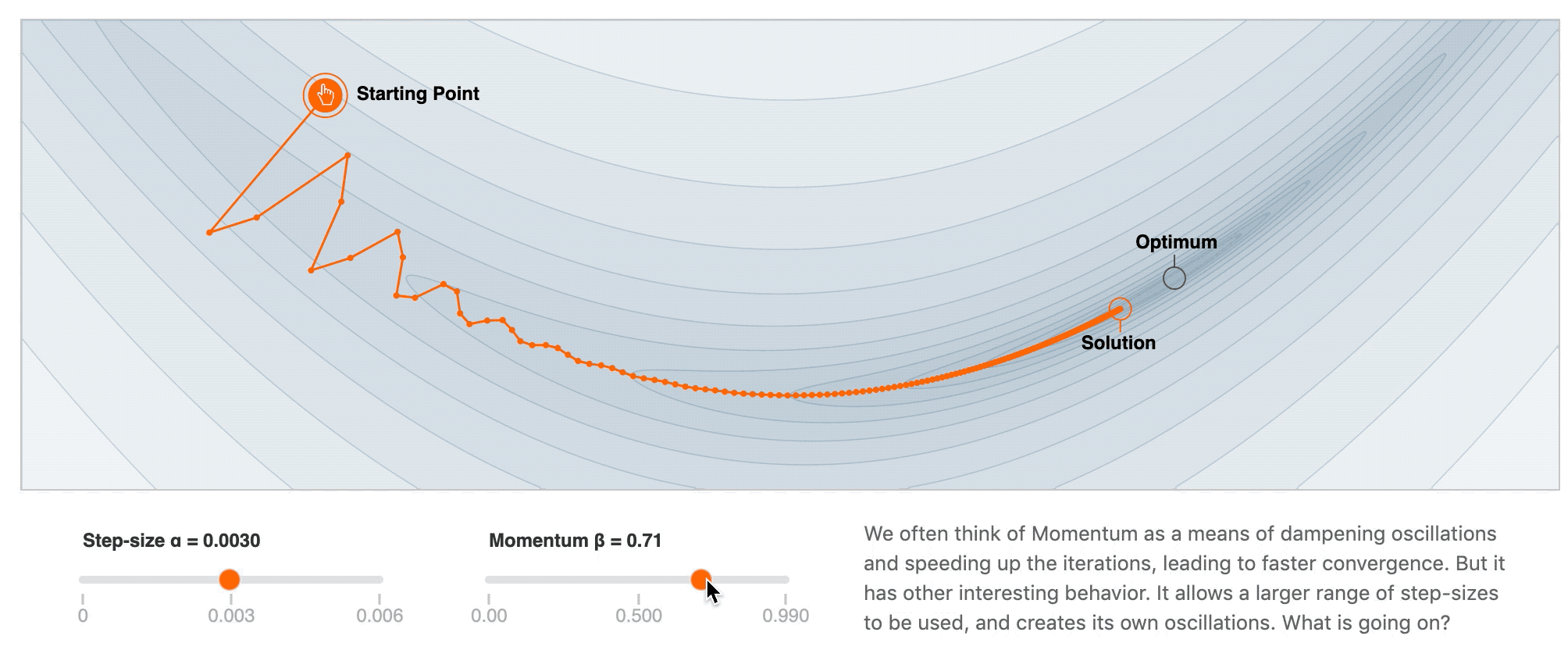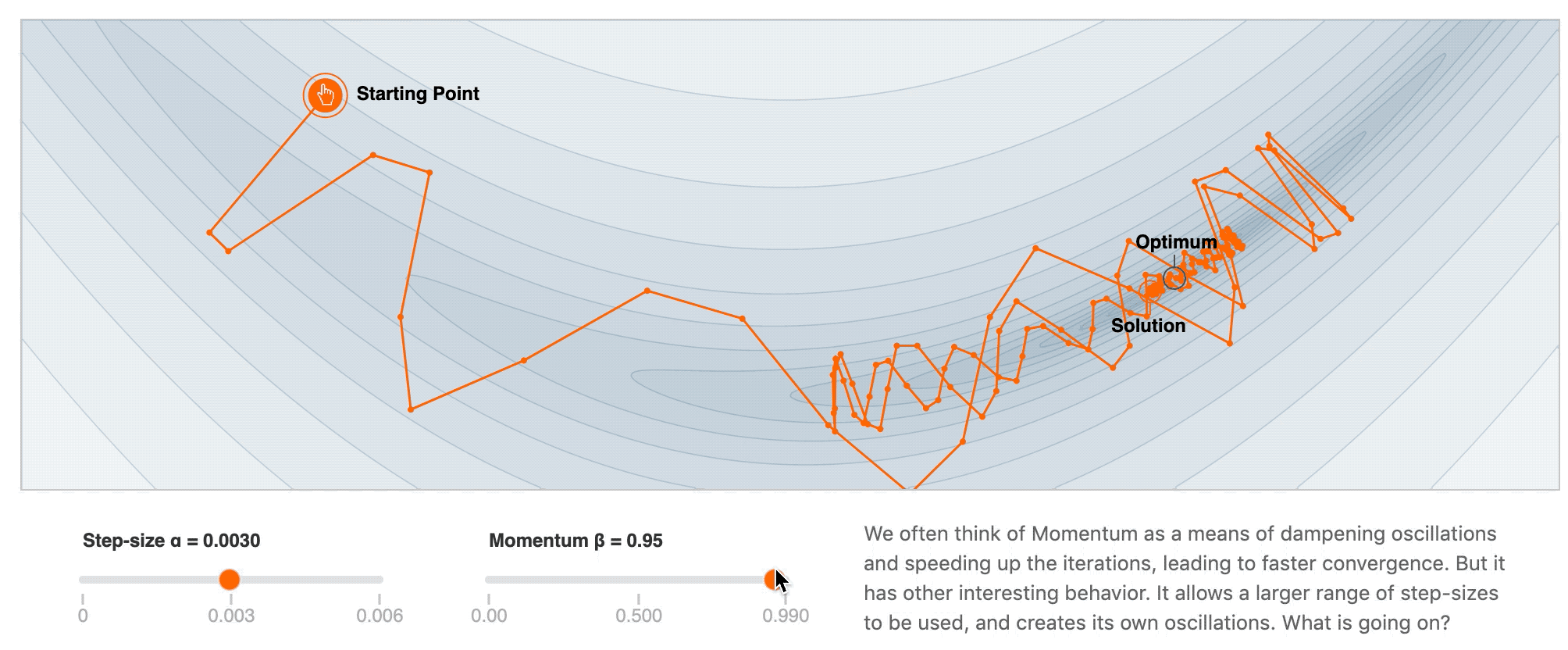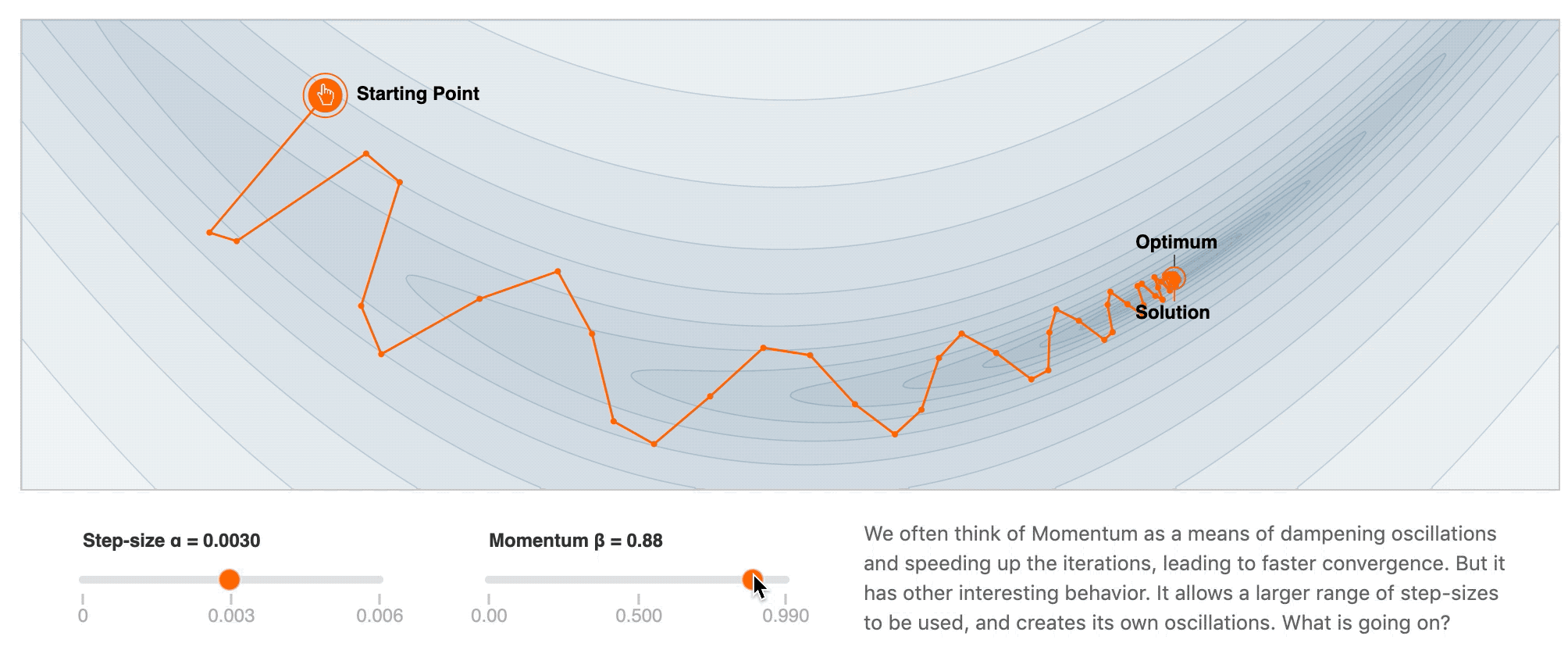
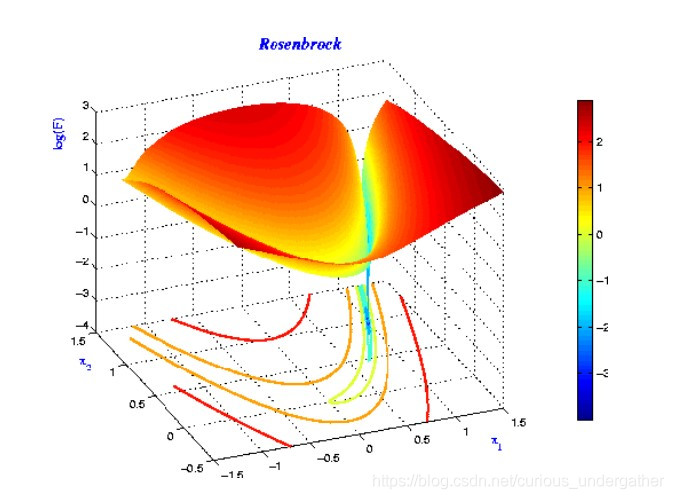
- 加速训练过程
- 解决 SGD 在 ravines 的情况下容易被困住, 就像一个深谷, SGD可能会在两侧左右横跳而达不到低谷

2.1 Simple momentum update
回顾一下普通的SGD
θ
=
θ
−
η
∇
θ
J
(
θ
)
\theta=\theta-\eta \nabla_{\theta} J(\theta)
θ=θ−η∇θJ(θ)
加了动量后的SGD PLUS!!!
v
i
=
γ
v
i
−
1
+
η
∇
w
J
(
w
)
w
=
w
−
v
i
\begin{array}{l} v_{i}=\gamma v_{i-1}+\eta \nabla_{w} J(w) \\ w=w-v_{i} \end{array}
vi=γvi−1+η∇wJ(w)w=w−vi
这里
v
v
v 初始为0,
γ
\gamma
γ 为其中一个超参, 一般设定为
0.9
0.9
0.9 (参照上动态图)
优势 — 减少震荡, 跳出 ravines
劣势 — 一定程度上还是比较随机, 只是沿着梯度改变的方向前进
2.2 Nesterov momentum update (Nesterov Accelerated Gradient) (NAG)
v i = γ v i − 1 + η ∇ w J ( w − γ v i − 1 ) w = w − v i \begin{array}{l} v_{i}=\gamma v_{i-1}+\eta \nabla_{w} J(w - \gamma v_{i-1}) \\ w=w-v_{i} \end{array} vi=γvi−1+η∇wJ(w−γvi−1)w=w−vi
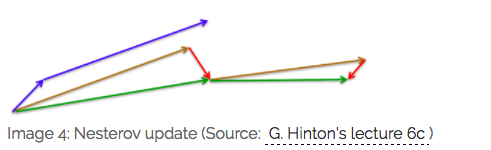
蓝线 是 Momentum 的更新过程,在更新后的累计梯度后有一个明显的大跳跃
棕色线 是 NAG 的更新过程, 先是一段大跳跃(预测向量),而后的 红线 是一段修正向量
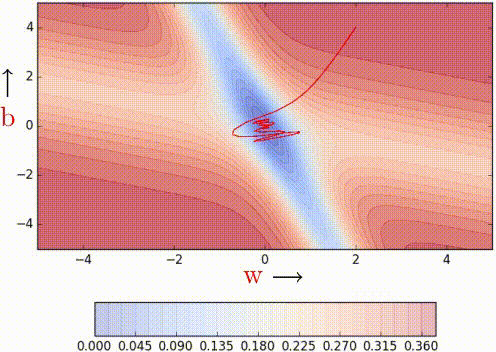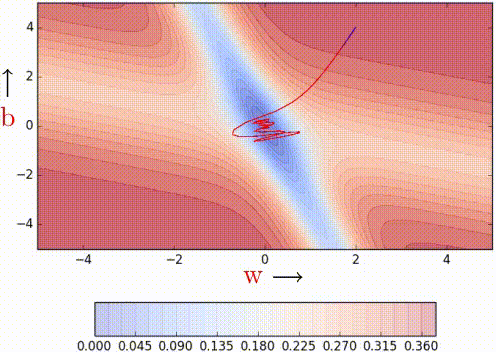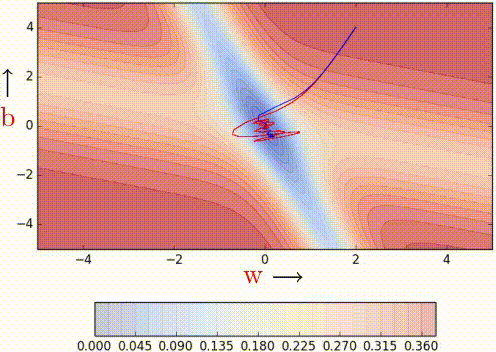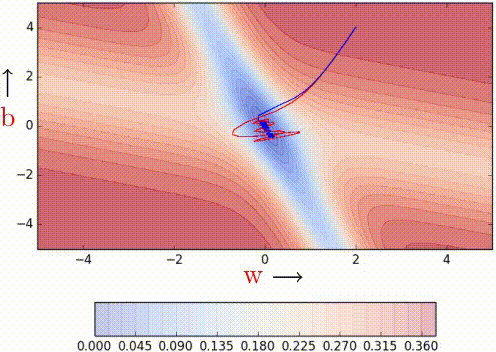
红线是momentum , 蓝线是NAG
个人觉得这可以在更新梯度时遇到"上坡"前放缓脚步,别直接冲出去了XD
优势 — 更新速度可顺应梯度的变化而改变
劣势 — "学习率"还是一个固定值,
3. Adaptive learning rate optimization algorithm
从训练集中采包含 m m m 个样本 { x ( 1 ) , … , x ( m ) } \left\{x^{(1)}, \ldots, x^{(m)}\right\} {x(1),…,x(m)} 的小批量,对应目标为 y ( i ) y^{(i)} y(i)
计算梯度
g
←
1
m
∇
θ
∑
i
L
(
f
(
x
(
i
)
;
θ
)
,
y
(
i
)
)
\boldsymbol{g} \leftarrow \frac{1}{m} \nabla_{\boldsymbol{\theta}} \sum_{i} L\left(f\left(\boldsymbol{x}^{(i)} ; \boldsymbol{\theta}\right), \boldsymbol{y}^{(i)}\right)
g←m1∇θi∑L(f(x(i);θ),y(i))
3.1 AdaGrad (Adaptive Subgradient)
r i = r i − 1 + g i 2 Δ w = η ϵ + r i g i w = w − Δ w \begin{aligned} r_{i} &=r_{i-1}+g_{i}^{2} \\ \Delta w &=\frac{\eta}{\epsilon+\sqrt{r_{i}}} g_{i} \\ w &=w-\Delta w \end{aligned} riΔww=ri−1+gi2=ϵ+riηgi=w−Δw
其中 ϵ \epsilon ϵ 是一个极小的正数,用来防止除以0, g i g_{i} gi 指在 i 处的梯度, g i 2 = g i ⊙ g i g_{i}^{2}=g_{i} \odot g_{i} gi2=gi⊙gi
⊙ \odot ⊙ 指矩阵的 Hadamard product (哈达玛积), 即 [ a 11 b 11 a 12 b 12 ⋯ a 1 n b 1 n a 21 b 21 a 22 b 22 ⋯ a 2 n b 2 n ⋮ ⋮ ⋮ a m 1 b m 1 a m 2 b m 2 ⋯ a m n b m n ] \left[\begin{array}{cccc} a_{11} b_{11} & a_{12} b_{12} & \cdots & a_{1 n} b_{1 n} \\ a_{21} b_{21} & a_{22} b_{22} & \cdots & a_{2 n} b_{2 n} \\ \vdots & \vdots & & \vdots \\ a_{m 1} b_{m 1} & a_{m 2} b_{m 2} & \cdots & a_{m n} b_{m n} \end{array}\right] ⎣⎢⎢⎢⎡a11b11a21b21⋮am1bm1a12b12a22b22⋮am2bm2⋯⋯⋯a1nb1na2nb2n⋮amnbmn⎦⎥⎥⎥⎤
公式推导:
r
i
r_{i}
ri 展开可得: 注意,i 从1开始
r
i
=
r
i
−
1
+
g
i
2
=
r
i
−
2
+
g
i
−
1
2
+
g
i
2
=
r
0
+
g
1
2
+
g
2
2
+
⋯
+
g
i
2
=
r
0
+
∑
j
=
1
i
g
j
2
\begin{aligned} r_{i} &=r_{i-1}+g_{i}^{2} \\ &=r_{i-2}+g_{i-1}^{2}+g_{i}^{2} \\ &=r_{0}+g_{1}^{2}+g_{2}^{2}+\cdots+g_{i}^{2} \\ &=r_{0}+\sum_{j=1}^{i} g_{j}^{2} \end{aligned}
ri=ri−1+gi2=ri−2+gi−12+gi2=r0+g12+g22+⋯+gi2=r0+j=1∑igj2
一般情况下 r 0 = 0 r_{0} = 0 r0=0 , 此时
Δ w = − η ϵ + r 1 g 1 = − η ϵ + g 1 g 1 \begin{aligned} \Delta w &=-\frac{\eta}{\epsilon+\sqrt{r_{1}}} g_{1} \\ &=-\frac{\eta}{\epsilon+g_{1}} g_{1} \end{aligned} Δw=−ϵ+r1ηg1=−ϵ+g1ηg1
但本着分母不能为0的原则( g i g_{i} gi 不确定), 令 r 0 = ϵ r_{0} = \epsilon r0=ϵ, 此时就可以把位于分母处的 ϵ \epsilon ϵ这一保险去除了, 递推公式也变成了:
r i = r 0 + ∑ j = 1 i g j 2 = ϵ + ∑ j = 1 i g j 2 > 0 \begin{aligned} r_{i} &=r_{0}+\sum_{j=1}^{i} g_{j}^{2} \\ &=\epsilon+\sum_{j=1}^{i} g_{j}^{2}>0 \end{aligned} ri=r0+j=1∑igj2=ϵ+j=1∑igj2>0
可知 r i r_{i} ri 恒大于0,因此不必在计算 Δ w \Delta w Δw 中额外加入 ϵ \epsilon ϵ
优势 —
-
具有损失最大偏导的参数相应地有一个快速下降的学习率,而具有小偏导的参数在学习率上 有相对较小的下降.净效果是在参数空间中更为平缓的倾斜方向会取得更大的进步. 摘自<花书>
- 减少了学习率的手动调节
劣势 — 分母会不断积累,这样学习率就会收缩并最终会变得非常小
以下,RMSprop 和 Adadelta 都是为了解决 Adagrad 学习率急剧下降问题所提出的,大致上算同时期的算法
3.2.1 RMSProp – AdaGrad 的 Plus

r i = ρ r i − 1 + ( 1 − ρ ) g i 2 Δ w = − η ϵ + r i g i w = w + Δ w \begin{aligned} r_i&=\rho r_{i-1}+(1-\rho )g_{i}^{2}\\ \Delta w&=-\frac{\eta}{\epsilon +\sqrt{r_i}}g_i\\ w&=w+\Delta w\\ \end{aligned} riΔww=ρri−1+(1−ρ)gi2=−ϵ+riηgi=w+Δw
当然也有这个版本的, 一个意思
E [ g 2 ] t = γ E [ g 2 ] t − 1 + ( 1 − γ ) g t 2 θ t + 1 = θ t − η E [ g 2 ] t + ϵ g t \begin{array}{l} E\left[ g^2 \right] _t=\gamma E\left[ g^2 \right] _{t-1}+\left( 1-\gamma \right) g_{t}^{2}\\ \\ \theta _{t+1}=\theta _t-\frac{\eta}{\sqrt{E\left[ g^2 \right] _t+\epsilon}}g_t\\ \end{array} E[g2]t=γE[g2]t−1+(1−γ)gt2θt+1=θt−E[g2]t+ϵηgt
ρ \rho ρ 和 γ \gamma γ 都是这个算法新引入的超参在不同参考资料中的写法,上面那种是在花书的,下面可能是论文的
一般 ρ \rho ρ 或 γ \gamma γ 为 0.9, η 为 0.001
通过引入此超参,使得RMSProp只会累积近期的梯度信息,对于“遥远的历史”会以指数衰减的形式放弃,即指数加权平均法
AdaGrad旨在应用于凸问题时快速收敛.当应 用于非凸函数训练神经网络时,学习轨迹可能穿过了很多不同的结构,最终到达一 个局部是凸碗的区域.AdaGrad 根据平方梯度的整个历史收缩学习率,可能使得学 习率在达到这样的凸结构前就变得太小了.RMSProp 使用指数衰减平均以丢弃遥远 过去的历史,使其能够在找到凸碗状结构后快速收敛,它就像一个初始化于该碗状 结构的 AdaGrad 算法实例
个人理解:
AdaGrad 在碗里面表现很好,在海浪里表现一般,因记住太久远的东西导致学习率到最后太拉跨.
RMSProp则通过指数加权平均, 仅记住最近的东西,使得能将海浪直接转化成碗, 从而发挥最大功效
3.2.2 Adadelta – AdaGrad 的 Plus
RMSProp更简单好用点,这个计算相对复杂,原理都是相似的
r i = ρ r i − 1 + ( 1 − ρ ) g i 2 s i = ρ s i − 1 + ( 1 − ρ ) Δ w 2 Δ w = − ϵ + s i ϵ + r i g i w = w + Δ w \begin{aligned} r_i&=\rho r_{i-1}+(1-\rho )g_{i}^{2}\\ s_i&=\rho s_{i-1}+(1-\rho )\Delta w^2\\ \Delta w&=-\frac{\sqrt{\epsilon +s_i}}{\sqrt{\epsilon +r_i}}g_i\\ w&=w+\Delta w\\ \end{aligned} risiΔww=ρri−1+(1−ρ)gi2=ρsi−1+(1−ρ)Δw2=−ϵ+riϵ+sigi=w+Δw
同理,上面的是在知乎找的,下面的可能是论文的(看完论文再更新)
初始化:
E
[
g
2
]
0
=
0
,
E
[
Δ
x
2
]
0
=
0
E\left[ g^2 \right] _0=0,E\left[ \Delta x^2 \right] _0=0 \\
E[g2]0=0,E[Δx2]0=0
具体更新:
E
[
g
2
]
t
=
ρ
E
[
g
2
]
t
−
1
+
(
1
−
ρ
)
g
t
2
Δ
w
t
=
−
η
E
[
g
2
]
t
+
ϵ
g
t
⇒
−
η
R
M
S
[
g
]
t
g
t
⇒
−
R
M
S
[
Δ
w
]
t
−
1
R
M
S
[
g
]
t
g
t
w
t
+
1
=
w
t
+
Δ
w
t
\\ E\left[ g^2 \right] _t=\rho E\left[ g^2 \right] _{t-1}+(1-\rho )g_{t}^{2}\\ \\ \Delta w_t=-\frac{\eta}{\sqrt{E\left[ g^2 \right] _t+\epsilon}}g_t\Rightarrow -\frac{\eta}{RMS[g]_t}g_t\,\,\Rightarrow -\frac{RMS[\Delta w]_{t-1}}{RMS[g]_t}g_t\\ \\ w_{t+1}=w_t+\Delta w_t\\
E[g2]t=ρE[g2]t−1+(1−ρ)gt2Δwt=−E[g2]t+ϵηgt⇒−RMS[g]tηgt⇒−RMS[g]tRMS[Δw]t−1gtwt+1=wt+Δwt
ρ \rho ρ 一般为 0.9
这里
R M S [ g ] t = E [ g 2 ] t + ϵ RMS[g]_t=E\left[ g^2 \right] _t+\epsilon RMS[g]t=E[g2]t+ϵ
R M S [ Δ w ] t − 1 = ρ E [ Δ w ] t − 1 + ( 1 − ρ ) Δ w t − 1 RMS[\Delta w]_{t-1}=\rho E\left[ \varDelta w \right] _{t-1}+(1-\rho )\varDelta w_{t-1} RMS[Δw]t−1=ρE[Δw]t−1+(1−ρ)Δwt−1
注意到, η = R M S [ Δ w ] t − 1 \eta \,\,=\,\,RMS[\Delta w]_{t-1} η=RMS[Δw]t−1, 即 梯度的均方根 root mean squared (RMS)
梯度的均方根 : 将所有值平方求和,求其均值,再开平方,就得到均方根值
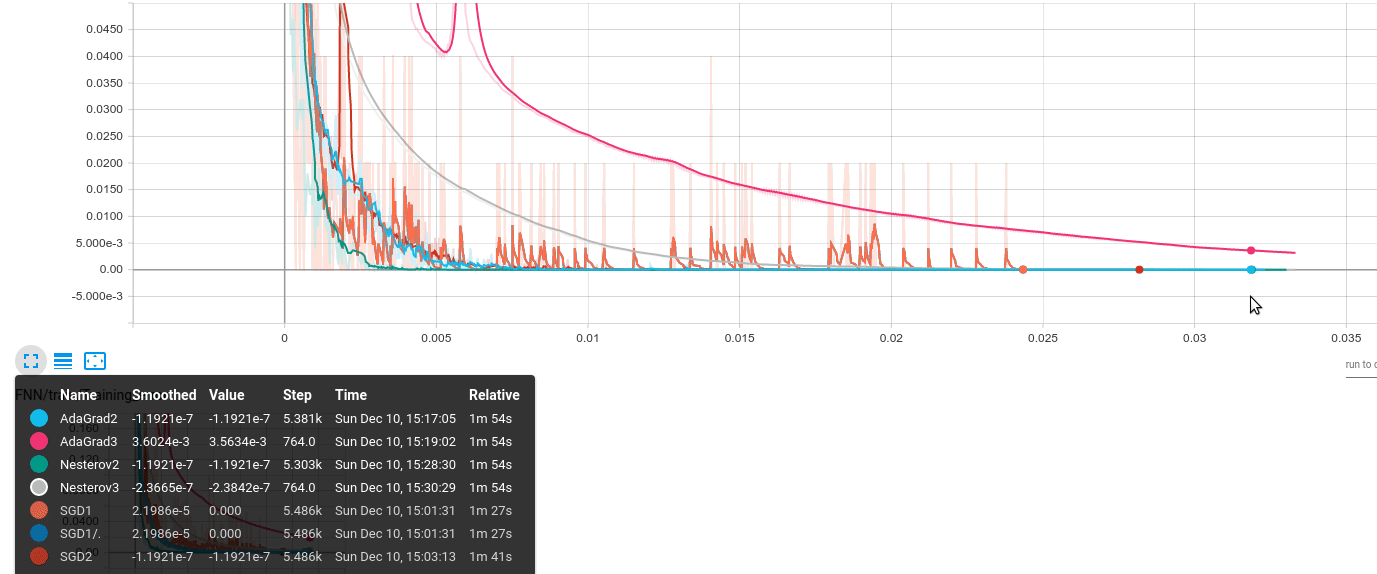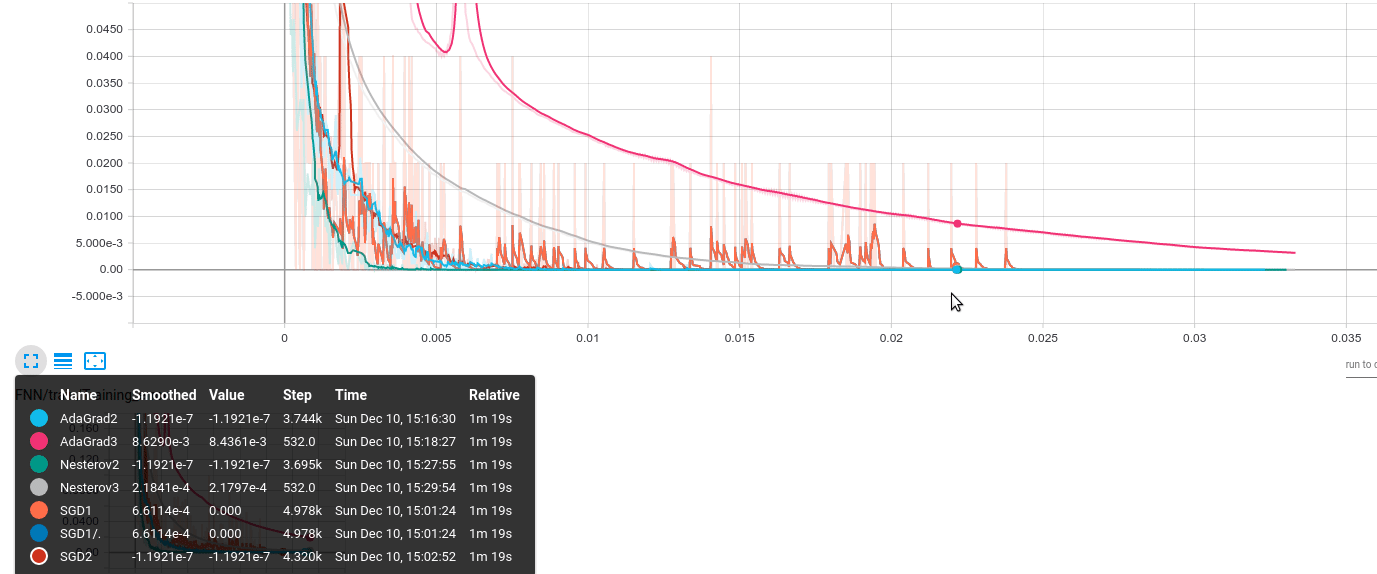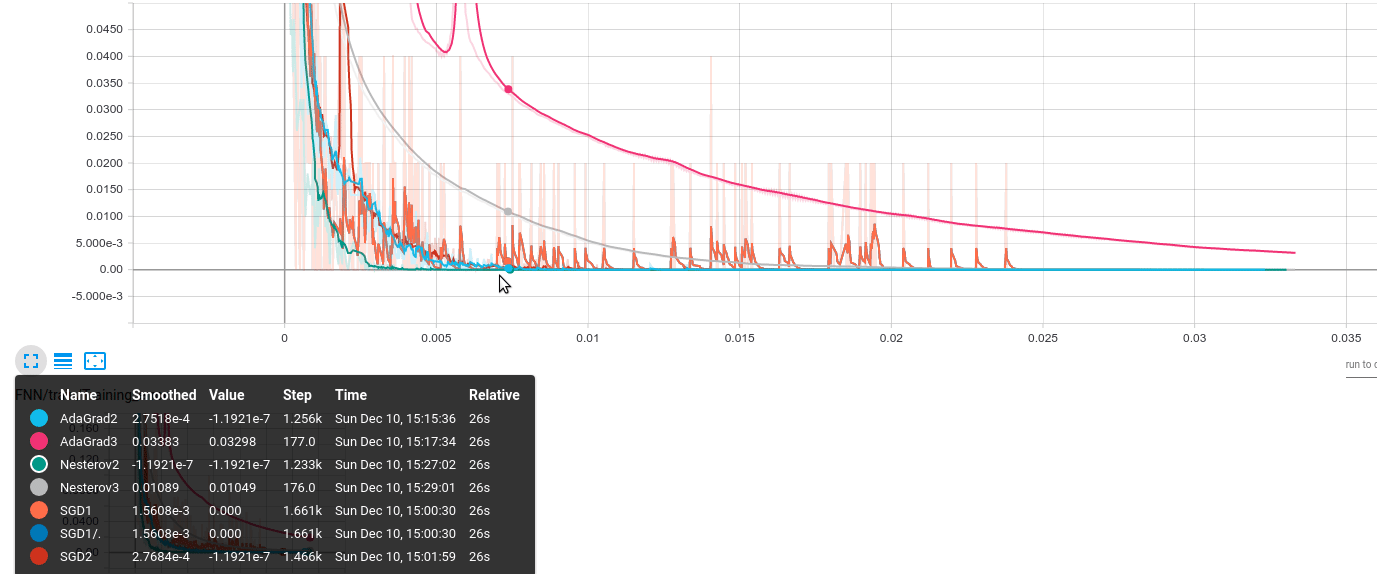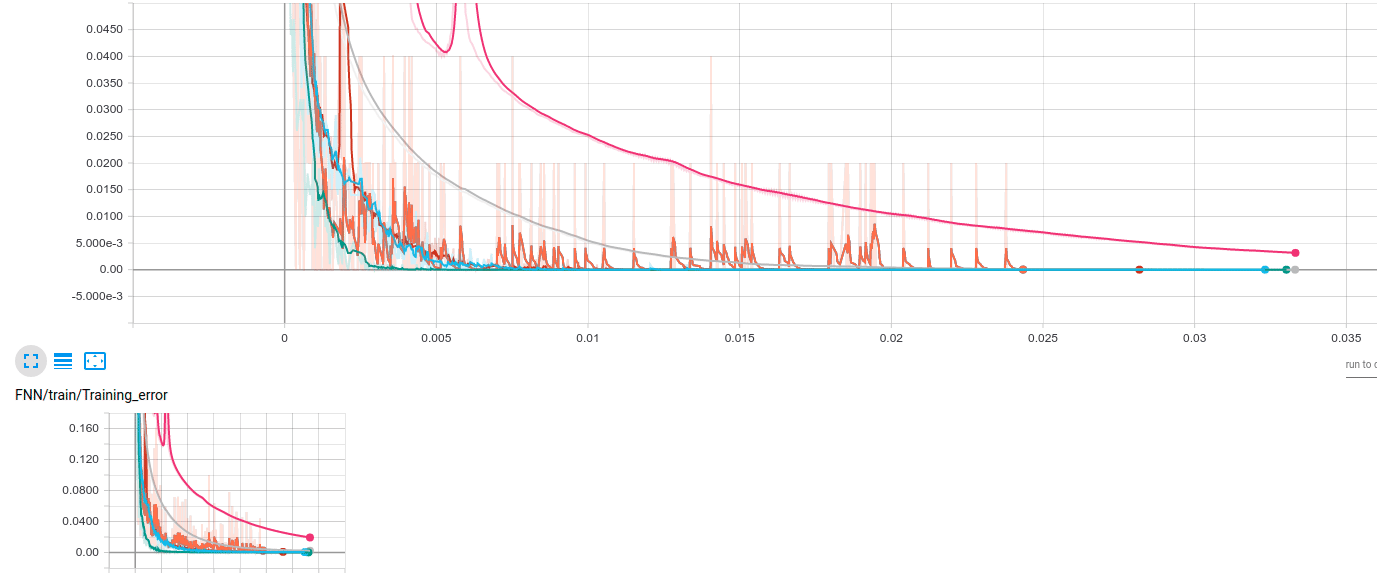
以上算法的比较:
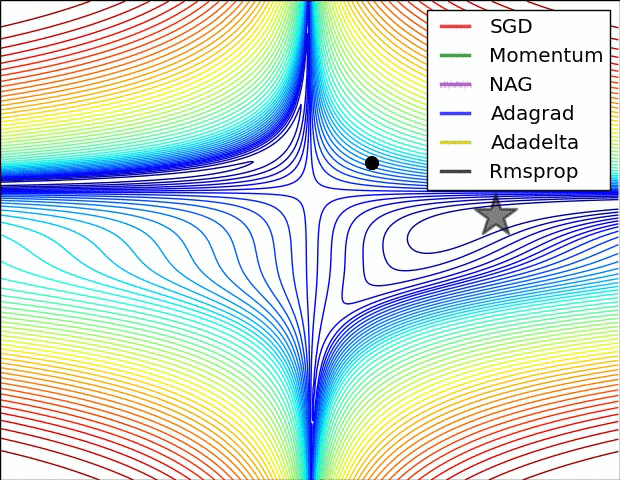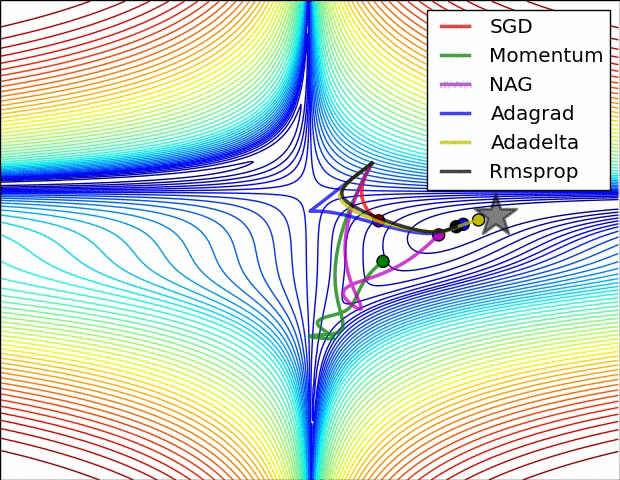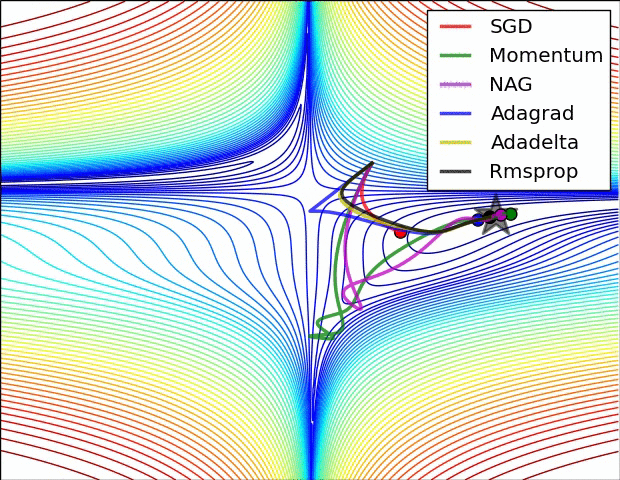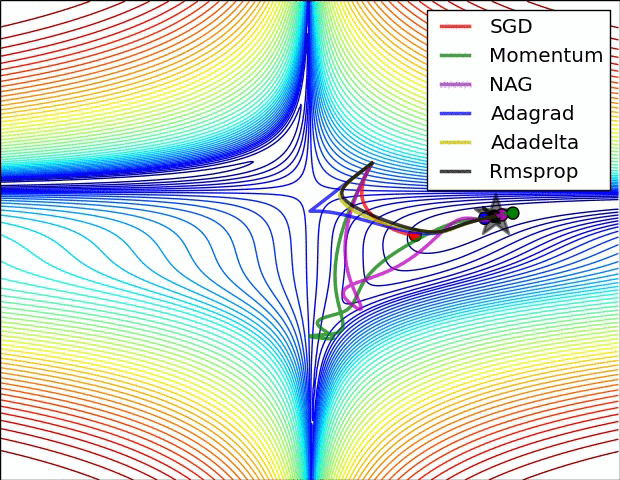
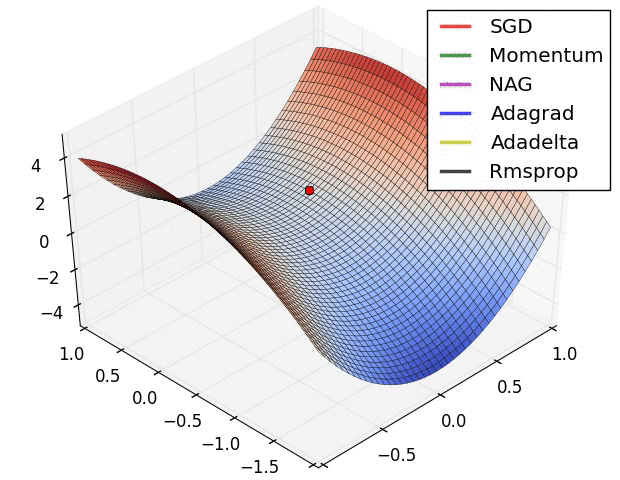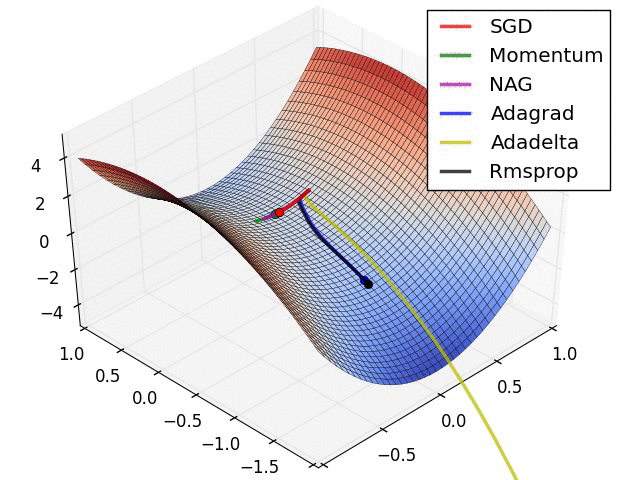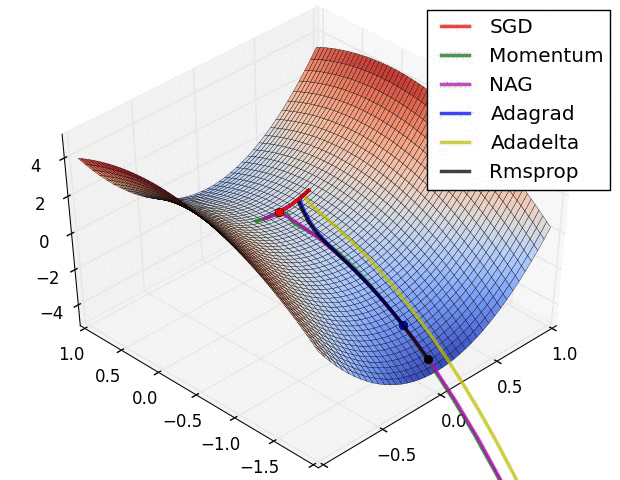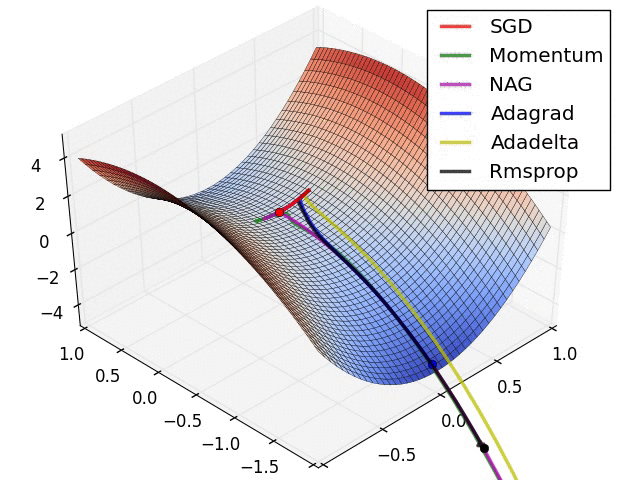
3.3 Adam:Adaptive Moment Estimation => RMSprop + Momentum
指数加权移动平均——吴恩达老师的DeepLearning.ai

- t : t: t: 更新的步长 (steps)
- α : \alpha: α: 学习率,用于控制步幅 (stepsize)
- θ \theta θ : 目标参数
- f ( θ ) : f(\theta): f(θ): 带有参数 θ \theta θ 的随机目标函数, 一般指损失函数
- g t : g_{t}: gt: 目标函数 f ( θ ) f(\theta) f(θ) 对 θ \theta θ 求导所得梯度
- β 1 : \beta_{1}: β1: 一阶矩衰减系数
- β 2 : \beta_{2}: β2: 二阶矩衰减系数
- m t : m_{t}: mt: 梯度 g t g_{t} gt 的一阶矩,即梯度 g t g_{t} gt 的期望
- v t : v_{t}: vt: 梯度 g t g_{t} gt 的二阶矩,即梯度 g t 2 g_{t}^{2} gt2的期望
- m ^ t : m t \hat{m}_{t}: m_{t} m^t:mt 的偏置矫正,考虑到 m t m_{t} mt 在零初始值情况下向0偏置
- v ^ t : v t \hat{v}_{t}: v_{t} v^t:vt 的偏置矫正,考虑到 v t v_{t} vt 在零初始值情况下向0偏置
t ← t + 1 g t ← ∇ θ f t ( θ t − 1 ) m t ← β 1 ⋅ m t − 1 + ( 1 − β 1 ) ⋅ g t v t ← β 2 ⋅ v t − 1 + ( 1 − β 2 ) ⋅ g t 2 m ^ t ← m t ( 1 − β 1 t ) v ^ t ← v t ( 1 − β 2 t ) θ t ← θ t − 1 − α m ^ t ( v ^ t + ϵ ) \begin{array}{l} t\gets t+1\\ g_t\gets \nabla _{\theta}f_t\left( \theta _{t-1} \right) \,\,\\ m_t\gets \beta _1\cdot m_{t-1}+\left( 1-\beta _1 \right) \cdot g_t\\ v_t\gets \beta _2\cdot v_{t-1}+\left( 1-\beta _2 \right) \cdot g_{t}^{2}\\ \hat{m}_t\gets \frac{m_t}{\left( 1-\beta _{1}^{t} \right) \,\,}\\ \widehat{v}_t\gets \frac{v_t}{\left( 1-\beta _{2}^{t} \right)}\\ \theta _t\gets \theta _{t-1}-\alpha \frac{\hat{m}_t}{\left( \sqrt{\hat{v}_t}+\epsilon \right)}\\ \end{array} t←t+1gt←∇θft(θt−1)mt←β1⋅mt−1+(1−β1)⋅gtvt←β2⋅vt−1+(1−β2)⋅gt2m^t←(1−β1t)mtv t←(1−β2t)vtθt←θt−1−α(v^t+ϵ)m^t
优势
(1). 惯性保持:Adam算法记录了梯度的一阶矩,即过往所有梯度与当前梯度的平均,使得每一次更新时,上一次更新的梯度与当前更新的梯度不会相差太大,即梯度平滑、稳定的过渡,可以适应不稳定的目标函数.
(2). 环境感知:Adam记录了梯度的二阶矩,即过往梯度平方与当前梯度平方的平均,这体现了环境感知能力,为不同参数产生自适应的学习速率.
(3). 超参数具有很好的解释性,且通常无需调整或仅需很少的微调.
3.4 AdaMax

Adam 作者在Adam论文的extensions部分提出的一个新的算法,他们发现在Adam中,单个权重的更新规则是将其梯度与当前
∣
g
t
∣
2
\left|g_{t}\right|^{2}
∣gt∣2和过去梯度
v
t
−
1
v_{t-1}
vt−1的
ℓ
2
\ell_{2}
ℓ2范数(标量)成反比例缩放.
将以下公式推导至 p-范数, 即
v t = β 2 v t − 1 + ( 1 − β 2 ) ∣ g t ∣ 2 ⟹ v t = β 2 p v t − 1 + ( 1 − β 2 p ) ∣ g t ∣ p = ( 1 − β 2 p ) ∑ i = 1 t β 2 p ( t − i ) ⋅ ∣ g i ∣ p v_t=\beta _2v_{t-1}+\left( 1-\beta _2 \right) \left| g_t \right|^2\,\,\\ \Longrightarrow v_t=\beta _{2}^{p}v_{t-1}+\left( 1-\beta _{2}^{p} \right) \left| g_t \right|^p\,\,=\left( 1-\beta _{2}^{p} \right) \sum_{i=1}^t{\beta _{2}^{p(t-i)}}\cdot \left| g_i \right|^p vt=β2vt−1+(1−β2)∣gt∣2⟹vt=β2pvt−1+(1−β2p)∣gt∣p=(1−β2p)i=1∑tβ2p(t−i)⋅∣gi∣p
但 p-范数 会因较大的p值而在数值上变得不稳定,可一旦
p
→
∞
p \rightarrow \infty
p→∞,一个极其稳定和简单的算法
出现了. 在使用L^p范数情况下,步长t和
v
t
(
1
/
p
)
vt^(1/p)
vt(1/p)成反比.
注意到此时衰减项等价于 β 2 p \beta_{2}^{p} β2p而不是 β 2 \beta_{2} β2. 令 p → ∞ p \rightarrow \infty p→∞, 定义 u t = lim p → ∞ ( v t ) 1 / p u_{t}=\lim _{p \rightarrow \infty}\left(v_{t}\right)^{1 / p} ut=limp→∞(vt)1/p, 有:
u
t
=
lim
p
→
∞
(
v
t
)
1
/
p
=
lim
p
→
∞
(
(
1
−
β
2
p
)
∑
i
=
1
t
β
2
p
(
t
−
i
)
⋅
∣
g
i
∣
p
)
1
/
p
=
lim
p
→
∞
(
1
−
β
2
p
)
1
/
p
(
∑
i
=
1
t
β
2
p
(
t
−
i
)
⋅
∣
g
i
∣
p
)
1
/
p
=
lim
p
→
∞
(
∑
i
=
1
t
(
β
2
(
t
−
i
)
⋅
∣
g
i
∣
)
p
)
1
/
p
=
max
(
β
2
t
−
1
∣
g
1
∣
,
β
2
t
−
2
∣
g
2
∣
,
…
,
β
2
∣
g
t
−
1
∣
,
∣
g
t
∣
)
\begin{aligned} u_{t}=\lim _{p \rightarrow \infty}\left(v_{t}\right)^{1 / p} &=\lim _{p \rightarrow \infty}\left(\left(1-\beta_{2}^{p}\right) \sum_{i=1}^{t} \beta_{2}^{p(t-i)} \cdot\left|g_{i}\right|^{p}\right)^{1 / p} \\ &=\lim _{p \rightarrow \infty}\left(1-\beta_{2}^{p}\right)^{1 / p}\left(\sum_{i=1}^{t} \beta_{2}^{p(t-i)} \cdot\left|g_{i}\right|^{p}\right)^{1 / p} \\ &=\lim _{p \rightarrow \infty}\left(\sum_{i=1}^{t}\left(\beta_{2}^{(t-i)} \cdot\left|g_{i}\right|\right)^{p}\right)^{1 / p} \\ &=\max \left(\beta_{2}^{t-1}\left|g_{1}\right|, \beta_{2}^{t-2}\left|g_{2}\right|, \ldots, \beta_{2}\left|g_{t-1}\right|,\left|g_{t}\right|\right) \end{aligned}
ut=p→∞lim(vt)1/p=p→∞lim((1−β2p)i=1∑tβ2p(t−i)⋅∣gi∣p)1/p=p→∞lim(1−β2p)1/p(i=1∑tβ2p(t−i)⋅∣gi∣p)1/p=p→∞lim(i=1∑t(β2(t−i)⋅∣gi∣)p)1/p=max(β2t−1∣g1∣,β2t−2∣g2∣,…,β2∣gt−1∣,∣gt∣)
(这步还不会… 学会了再来补充)
而后很自然地
u
t
=
max
(
β
2
⋅
u
t
−
1
,
∣
g
t
∣
)
u_{t}=\max \left(\beta_{2} \cdot u_{t-1},\left|g_{t}\right|\right)
ut=max(β2⋅ut−1,∣gt∣)
最终
t ← t + 1 g t ← ∇ w f t ( w t − 1 ) m t ← β 1 ⋅ m t − 1 + ( 1 − β 1 ) ⋅ g t u t ← max ( β 2 ⋅ u t − 1 , ∣ g t ∣ ) w t ← w t − 1 − ( α / ( 1 − β 1 t ) ) ⋅ m t / u t \begin{aligned} &t\gets t+1\\ &g_t\gets \nabla _wf_t\left( w_{t-1} \right) \,\,\\ &\begin{array}{l} m_t\gets \beta _1\cdot m_{t-1}+\left( 1-\beta _1 \right) \cdot g_t\\ u_t\gets \max \left( \beta _2\cdot u_{t-1},\left| g_t \right| \right) \,\,\\ w_t\gets w_{t-1}-\left( \alpha /\left( 1-\beta _{1}^{t} \right) \right) \cdot m_t/u_t\\ \end{array}\\ \end{aligned} t←t+1gt←∇wft(wt−1)mt←β1⋅mt−1+(1−β1)⋅gtut←max(β2⋅ut−1,∣gt∣)wt←wt−1−(α/(1−β1t))⋅mt/ut
建议值:
η
∣
α
=
0.002
,
β
1
=
0.9
,
and
β
2
=
0.999
\eta | \alpha =0.002, \beta_{1}=0.9, \text { and } \beta_{2}=0.999
η∣α=0.002,β1=0.9, and β2=0.999
PS:这个max比较的是梯度各个维度上的当前值和历史最大值
补充知识:
对于p-范数,如果
x
=
[
x
1
,
x
2
,
⋯
,
x
n
]
T
x=\left[x_{1}, x_{2}, \cdots, x_{n}\right]^{\mathrm{T}}
x=[x1,x2,⋯,xn]T
那么向量X的p-范数
ℓ
p
\ell_{p}
ℓp就是
∥
x
∥
p
=
(
∣
x
1
∣
p
+
∣
x
2
∣
p
+
⋯
+
∣
x
n
∣
p
)
1
p
\|x\|_{p}=\left(\left|x_{1}\right|^{p}+\left|x_{2}\right|^{p}+\cdots+\left|x_{n}\right|^{p}\right)^{\frac{1}{p}}
∥x∥p=(∣x1∣p+∣x2∣p+⋯+∣xn∣p)p1
ℓ
1
\ell_{1}
ℓ1范数:
∥
x
∥
1
=
∣
x
1
∣
+
∣
x
2
∣
+
∣
x
3
∣
+
⋯
+
∣
x
n
∣
\|x\|_{1}=\left|x_{1}\right|+\left|x_{2}\right|+\left|x_{3}\right|+\cdots+\left|x_{n}\right|
∥x∥1=∣x1∣+∣x2∣+∣x3∣+⋯+∣xn∣
ℓ
2
\ell_{2}
ℓ2范数:
∥
x
∥
2
=
(
∣
x
1
∣
2
+
∣
x
2
∣
2
+
∣
x
3
∣
2
+
⋯
+
∣
x
n
∣
2
)
1
/
2
\|x\|_{2}=\left(\left|x_{1}\right|^{2}+\left|x_{2}\right|^{2}+\left|x_{3}\right|^{2}+\cdots+\left|x_{n}\right|^{2}\right)^{1 / 2}
∥x∥2=(∣x1∣2+∣x2∣2+∣x3∣2+⋯+∣xn∣2)1/2
L0范数是指向量中非0的元素的个数(L0范数很难优化求解)
L1范数是指向量中各个元素绝对值之和
L2范数是指向量各元素的平方和然后求平方根
L1范数可以进行特征选择,即让特征的系数变为0
L2范数可以防止过拟合,提升模型的泛化能力,有助于处理 condition number不好下的矩阵(数据变化很小矩阵求解后结果变化很大)
(核心:L2对大数,对outlier离群点更敏感!)
下降速度:最小化权值参数L1比L2变化的快
模型空间的限制:L1会产生稀疏 L2不会.
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0.
4. Nadam => RMSProp + NAG
N
A
G
g
t
=
∇
w
t
J
(
w
t
−
γ
m
t
−
1
)
m
t
=
γ
m
t
−
1
+
η
g
t
w
t
+
1
=
w
t
−
m
t
M
o
m
e
n
t
u
m
g
t
=
∇
w
t
J
(
w
t
)
m
t
=
γ
m
t
−
1
+
η
g
t
w
t
+
1
=
w
t
−
m
t
\,\, \begin{aligned} \,\, NAG\\ g_t&=\nabla _{w_t}J\left( w_t-\gamma m_{t-1} \right)\\ m_t&=\gamma m_{t-1}+\eta g_t\\ w_{t+1}&=w_t-m_t\\ \end{aligned}\,\, \begin{aligned} \,\, Momentum\\ g_t&=\nabla _{w_t}J\left( w_t \right)\\ m_t&=\gamma m_{t-1}+\eta g_t\\ w_{t+1}&=w_t-m_t\\ \end{aligned}
NAGgtmtwt+1=∇wtJ(wt−γmt−1)=γmt−1+ηgt=wt−mtMomentumgtmtwt+1=∇wtJ(wt)=γmt−1+ηgt=wt−mt
R
M
S
p
r
o
p
r
i
=
ρ
r
i
−
1
+
(
1
−
ρ
)
g
i
2
Δ
w
=
−
η
ϵ
+
r
i
g
i
w
=
w
+
Δ
w
\begin{aligned} \,\, RMSprop\\ r_i&=\rho r_{i-1}+(1-\rho )g_{i}^{2}\\ \Delta w&=-\frac{\eta}{\epsilon +\sqrt{r_i}}g_i\\ w&=w+\Delta w\\ \end{aligned}\,\,
RMSpropriΔww=ρri−1+(1−ρ)gi2=−ϵ+riηgi=w+Δw
A
d
a
m
t
←
t
+
1
g
t
←
∇
θ
f
t
(
θ
t
−
1
)
m
t
←
β
1
⋅
m
t
−
1
+
(
1
−
β
1
)
⋅
g
t
v
t
←
β
2
⋅
v
t
−
1
+
(
1
−
β
2
)
⋅
g
t
2
m
^
t
←
m
t
(
1
−
β
1
t
)
v
^
t
←
v
t
(
1
−
β
2
t
)
θ
t
←
θ
t
−
1
−
α
m
^
t
(
v
^
t
+
ϵ
)
\begin{array}{c} \,\,Adam\\ t\,\,\gets \,\,t+1\\ g_t\gets \nabla _{\theta}f_t\left( \theta _{t-1} \right) \,\,\\ m_t\gets \beta _1\cdot m_{t-1}+\left( 1-\beta _1 \right) \cdot g_t\\ v_t\gets \beta _2\cdot v_{t-1}+\left( 1-\beta _2 \right) \cdot g_{t}^{2}\\ \hat{m}_t\gets \frac{m_t}{\left( 1-\beta _{1}^{t} \right) \,\,}\\ \widehat{v}_t\gets \frac{v_t}{\left( 1-\beta _{2}^{t} \right)}\\ \theta _t\gets \theta _{t-1}-\alpha \frac{\hat{m}_t}{\left( \sqrt{\hat{v}_t}+\epsilon \right)}\\ \end{array} \\
Adamt←t+1gt←∇θft(θt−1)mt←β1⋅mt−1+(1−β1)⋅gtvt←β2⋅vt−1+(1−β2)⋅gt2m^t←(1−β1t)mtv
t←(1−β2t)vtθt←θt−1−α(v^t+ϵ)m^t
Dozat 提出一个修改NAG的方式:与其两次应用动量优化 γ m t − 1 \gamma m_{t-1} γmt−1,一次是更新 g t g_{t} gt ,第二次则是更新 w t + 1 w_{t+1} wt+1 ,不如直接将预测动量向量应用到当前参数的更新上:
g t = ∇ w t J ( w t ) m t = γ m t − 1 + η g t w t + 1 = w t − ( γ m t + η g t ) \begin{aligned} g_{t} &=\nabla_{w_{t}} J\left(w_{t}\right) \\ m_{t} &=\gamma m_{t-1}+\eta g_{t} \\ w_{t+1} &=w_{t}-\left(\gamma m_{t}+\eta g_{t}\right) \end{aligned} gtmtwt+1=∇wtJ(wt)=γmt−1+ηgt=wt−(γmt+ηgt)
其中 γ \gamma γ是动量下降项, η \eta η 是步长(理解成LR也可以),可以看到现在直接应用 m t m_{t} mt来预测
为了将Nesterov momentum整合进Adam, 可仿效上面的公式,即使用当前的动量 m t m_{t} mt来进行预测,也就是说,只要简单地替换下动量参数即可
Adam公式中的第二条式子展开 PS: v ^ t \hat{v}_t v^t 不需要改变
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m ^ t = m t 1 − β 1 t w t + 1 = w t − η v ^ t + ϵ m ^ t \begin{aligned} m_t&=\beta _1m_{t-1}+\left( 1-\beta _1 \right) g_t\\ \hat{m}_t&=\frac{m_t}{1-\beta _{1}^{t}}\\ w_{t+1}&=w_t-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}\hat{m}_t\\ \end{aligned} mtm^twt+1=β1mt−1+(1−β1)gt=1−β1tmt=wt−v^t+ϵηm^t
得
w t + 1 = w t − η v ^ t + ϵ ( β 1 m t − 1 1 − β 1 t + ( 1 − β 1 ) g t 1 − β 1 t ) w_{t+1}=w_t-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}\left( \frac{\beta _1m_{t-1}}{1-\beta _{1}^{t}}+\frac{\left( 1-\beta _1 \right) g_t}{1-\beta _{1}^{t}} \right) wt+1=wt−v^t+ϵη(1−β1tβ1mt−1+1−β1t(1−β1)gt)
而
m
t
−
1
1
−
β
1
t
≈
m
t
−
1
1
−
β
1
t
−
1
=
m
^
t
−
1
\frac{m_{t-1}}{1-\beta _{1}^{t}}\,\,\approx \,\,\frac{m_{t-1}}{1-\beta _{1}^{t-1}}\,\,=\,\,\hat{m}_{t-1}
1−β1tmt−1≈1−β1t−1mt−1=m^t−1
(不用在意,反正下一步就换掉了)
则可将公式化简为
w t + 1 = w t − η v ^ t + ϵ ( β 1 m ^ t − 1 + ( 1 − β 1 ) g t 1 − β 1 t ) w_{t+1}=w_t-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}\left( \beta _1\hat{m}_{t-1}+\frac{\left( 1-\beta _1 \right) g_t}{1-\beta _{1}^{t}} \right) wt+1=wt−v^t+ϵη(β1m^t−1+1−β1t(1−β1)gt)
然后,前面 w t + 1 = w t − ( γ m t + η g t ) w_{t+1}=w_{t}-\left(\gamma m_{t}+\eta g_{t}\right) wt+1=wt−(γmt+ηgt)(的思想) 就派上用场了,直接把 m ^ t − 1 \hat{m}_{t-1} m^t−1 换为 m ^ t \hat{m}_{t} m^t
最终公式为
w t + 1 = w t − η v ^ t + ϵ ( β 1 m ^ t + ( 1 − β 1 ) g t 1 − β 1 t ) w_{t+1}=w_t-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}\left( \beta _1\hat{m}_{t}+\frac{\left( 1-\beta _1 \right) g_t}{1-\beta _{1}^{t}} \right) wt+1=wt−v^t+ϵη(β1m^t+1−β1t(1−β1)gt)
5. NadaMax = AdaMax + NAG
还是这条公式
w t + 1 = w t − η v ^ t + ϵ ( β 1 m ^ t + ( 1 − β 1 ) g t 1 − β 1 t ) w_{t+1}=w_t-\frac{\eta}{\sqrt{\hat{v}_t}+\epsilon}\left( \beta _1\hat{m}_{t}+\frac{\left( 1-\beta _1 \right) g_t}{1-\beta _{1}^{t}} \right) wt+1=wt−v^t+ϵη(β1m^t+1−β1t(1−β1)gt)
然后便是AdaMax的精髓部分, 注意,
v
^
t
+
ϵ
\sqrt{\hat{v}_t}+\epsilon
v^t+ϵ "相对"等价于
u
t
u_{t}
ut
u
t
=
max
(
β
2
⋅
u
t
−
1
,
∣
g
t
∣
)
Δ
w
=
α
1
−
β
1
t
m
t
u
t
u_{t}=\max \left(\beta_{2} \cdot u_{t-1},\left|g_{t}\right|\right) \\ \Delta w = \frac{\alpha}{1-\beta _{1}^{t}}\frac{m_t}{u_t}
ut=max(β2⋅ut−1,∣gt∣)Δw=1−β1tαutmt
用
u
t
u_{t}
ut 替换
v
^
t
+
ϵ
\sqrt{\hat{v}_t}+\epsilon
v^t+ϵ
w
t
+
1
=
w
t
−
η
r
i
(
β
1
m
^
t
+
(
1
−
β
1
)
g
t
1
−
β
1
t
)
r
i
=
max
(
β
2
⋅
u
t
−
1
,
∣
g
t
∣
)
w_{t+1}=w_t-\frac{\eta}{r_i}\left( \beta _1\hat{m}_t+\frac{\left( 1-\beta _1 \right) g_t}{1-\beta _{1}^{t}} \right) \\ r_i\,\,=\,\,\max \left( \beta _2\cdot u_{t-1},\left| g_t \right| \right)
wt+1=wt−riη(β1m^t+1−β1t(1−β1)gt)ri=max(β2⋅ut−1,∣gt∣)
(得好好看看原文,这部分不是很懂)
6. AMSGrad = Adagrad Plus
尽管自适应学习率方法已成为训练神经网络的范式,但在在某些情况下,例如对于对象识别或机器翻译,它们无法收敛到最优解,甚至还被SGD+动量法超过.
Reddi .etc 此论文正式化(formalize)了这个问题,并指出 past squared gradients 的指数移动平均值,将其作为自适应学习率方法的泛化行为不佳的原因。回想一下,引入指数加权平均的动机很强:防止学习率随着训练的进行而变得无限小,即Adagrad算法的关键缺陷。但是,在其他情况下,梯度的这种短期记忆反而成为障碍。
在Adam收敛到次优解的环境中,已经观察到一些小批次的优化(minibatches)提供了较大且信息丰富的梯度,但是由于这些小批次优化很少出现,因此指数平均会减小其影响,从而导致收敛性较差。此文作者提供了一个简单的凸优化问题的例子,其中Adam可以观察到相同的行为。
AMSGrad, Reddi .etc 提出的解决方案,即采用 MAX 函数来取代指数加权平均
其动量定义,跟Adam的一样
v
t
=
β
2
v
t
−
1
+
(
1
−
β
2
)
g
t
2
v_{t}=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2}
vt=β2vt−1+(1−β2)gt2
v
^
t
\hat{v}_{t}
v^t的定义与Adam的不一样了
v
^
t
=
max
(
v
^
t
−
1
,
v
t
)
\hat{v}_{t}=\max \left(\hat{v}_{t-1}, v_{t}\right)
v^t=max(v^t−1,vt)
作为对比,Adam的定义
v
^
t
←
v
t
(
1
−
β
2
t
)
\widehat{v}_t\gets \frac{v_t}{\left( 1-\beta _{2}^{t} \right)}
v
t←(1−β2t)vt
这样,Adma 的步长便不会增加,也就规避了先前的问题
完整公式(作者还简化了)
m
t
=
β
1
m
t
−
1
+
(
1
−
β
1
)
g
t
v
t
=
β
2
v
t
−
1
+
(
1
−
β
2
)
g
t
2
v
^
t
=
max
(
v
^
t
−
1
,
v
t
)
w
t
+
1
=
w
t
−
η
v
^
t
+
ϵ
m
t
\begin{aligned} m_{t} &=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right) g_{t} \\ v_{t} &=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2} \\ \hat{v}_{t} &=\max \left(\hat{v}_{t-1}, v_{t}\right) \\ w_{t+1} &=w_{t}-\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon} m_{t} \end{aligned}
mtvtv^twt+1=β1mt−1+(1−β1)gt=β2vt−1+(1−β2)gt2=max(v^t−1,vt)=wt−v^t+ϵηmt
以上实验用的可视化(待测试)https://github.com/bokeh/bokeh
待学习
- https://ruder.io/deep-learning-optimization-2017/
- 近年的优化器
- 添加代码
- 论文查看
Reference
超棒的文章!
从SGD到NadaMax,十种机器学习优化算法原理及实现
各种优化器对比–BGD/SGD/MBGD/MSGD/NAG/Adagrad/Adam
深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
I. Goodfellow, Y. Bengio和A. Courville, Deep Learning. MIT Press, 2016. (花书)
感恩,这篇文章极好
An overview of gradient descent optimization algorithms















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









