







 本文详细介绍了深度学习中的优化算法,包括Momentum、NAG、AdaGrad、RMSProp、AdaDelta和Adam。这些算法旨在解决SGD在峡谷和鞍点问题上的困难,通过引入动量和环境感知来改善梯度下降的效率。Adam作为优化器的集大成者,结合了动量和自适应学习率,通常对超参数的选择较为鲁棒,是训练深层复杂网络的首选。
本文详细介绍了深度学习中的优化算法,包括Momentum、NAG、AdaGrad、RMSProp、AdaDelta和Adam。这些算法旨在解决SGD在峡谷和鞍点问题上的困难,通过引入动量和环境感知来改善梯度下降的效率。Adam作为优化器的集大成者,结合了动量和自适应学习率,通常对超参数的选择较为鲁棒,是训练深层复杂网络的首选。
前言
前面已经讲过几中梯度下降算法了,并且给了一个收尾引出这一章节,想看的小伙伴可以去看看这一篇文章:机器学习之梯度下降算法。前面讲过对SGD来说,最要命的是SGD可能会遇到“峡谷”和“鞍点”两种困境峡谷类似⼀个带有坡度的狭长小道,左右两侧是 “峭壁”;在峡谷中,准确的梯度方向应该沿着坡的方向向下,但粗糙的梯度估计使其稍有偏离就撞向两侧的峭壁,然后在两个峭壁间来回震荡。鞍点的形状类似⼀个马鞍,⼀个方向两头翘,⼀个方向两头垂,而中间区域近似平地;⼀旦优化的过程中不慎落入鞍点,优化很可能就会停滞下来(坡度不明显,很可能走错方向,如果梯度为0的区域,SGD无法准确察觉出梯度的微小变化,结果就停下来)。为了形象,还找了个图:
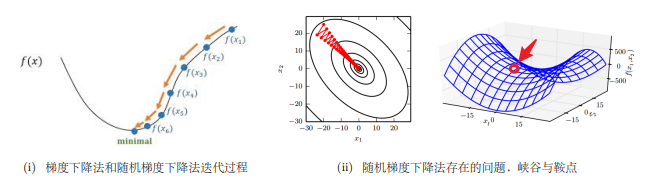
所以接下来的一些算法,就是针对于SGD的这两个要命问题进行的一系列改进了,首先先把握住改进的两个大方向: 惯性保持和环境感知
惯性保持: 加入动量, 代表:Momentum, Nesterov Accerlerated Gradient
环境感知: 根据不同参数的一些经验性判断, 自适应的确定每个参数的学习速率,这是一种自适应学习率的优化算法。代表:AdaGrad, AdaDelta, RMSProp
还有把上面两个方向结合的: Adam, AdaMax, Nadam
一、Momentum
动量顾名思义就是给这个梯度下降加了一个动力,这样子是为了更好的解决随机梯度下降中的“峡谷”和“鞍点”问题,并且能够使得在相同方向时下降速度更快。用《百面机器学习》上的一个比喻:如果把原始的 SGD 想象成⼀个纸团在重力作用向下滚动,由于质量小受到山壁弹力的干扰大,导致来回震荡。或者在鞍点处因为质量小速度很快减为 0,导致无法离开这块平地。动量方法相当于把纸团换成了铁球。不容易受到外力的干扰,轨迹更加稳定,同时因为在鞍点处因为惯性的作用,更有可能离开平地。
接下来看一下为什么会解决上述问题:动量算法积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。用大白话结合下面公式来讲就是将之前梯度下降的动量给保留下来了,并在第t次梯度下降的时候,将其和所求的的下降动量进行相加,使得之前的下降动量影响了现在的下降动量。
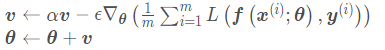
从形式上看,动量算法引入了变量v 充当速度角色,以及相关的超参数α ,决定了之前的梯度贡献衰减的有多快。在这里我们一般设超参数α=0.9.原始的SGD每次更新的步长只是梯度乘以学习率。现在,步长还取决于历史梯度序列的大小和排列。 当许多连续的梯度指向相同的方向时,步长就会不断的增大,这就解决了在鞍点处速度减少为0的情况。
所以当前迭代点的下降方向不仅仅取决于当前的梯度,还受到前面所有迭代点的影响。动量方法以一种廉价的方式模拟了二阶梯度(牛顿法)。撤了这么半天理论,拿个图来看看效果ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8078
8078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









