







 本文通过深度学习中的VGG模型,详细介绍如何实现中草药识别。利用深度学习解决图像分类问题,数据集包含五个类别的中草药图片,通过预处理、模型构建、训练优化和评估,最终实现模型部署。
本文通过深度学习中的VGG模型,详细介绍如何实现中草药识别。利用深度学习解决图像分类问题,数据集包含五个类别的中草药图片,通过预处理、模型构建、训练优化和评估,最终实现模型部署。
中草药识别案例是图像分类问题,相较于目标检测、实例分割、行为识别、轨迹跟踪等难度较大的计算机视觉任务,图像分类只需要让计算机『看出』图片里的物体类别,更为基础但极为重要。图像分类在许多领域都有着广泛的应用,如:安防领域的智能视频分析和人脸识别等,医学领域的中草药识别,互联网领域基于内容的图像检索和相册自动归类,农业领域的害虫识别等。
1.方案设计
本案例整体结构如下所示: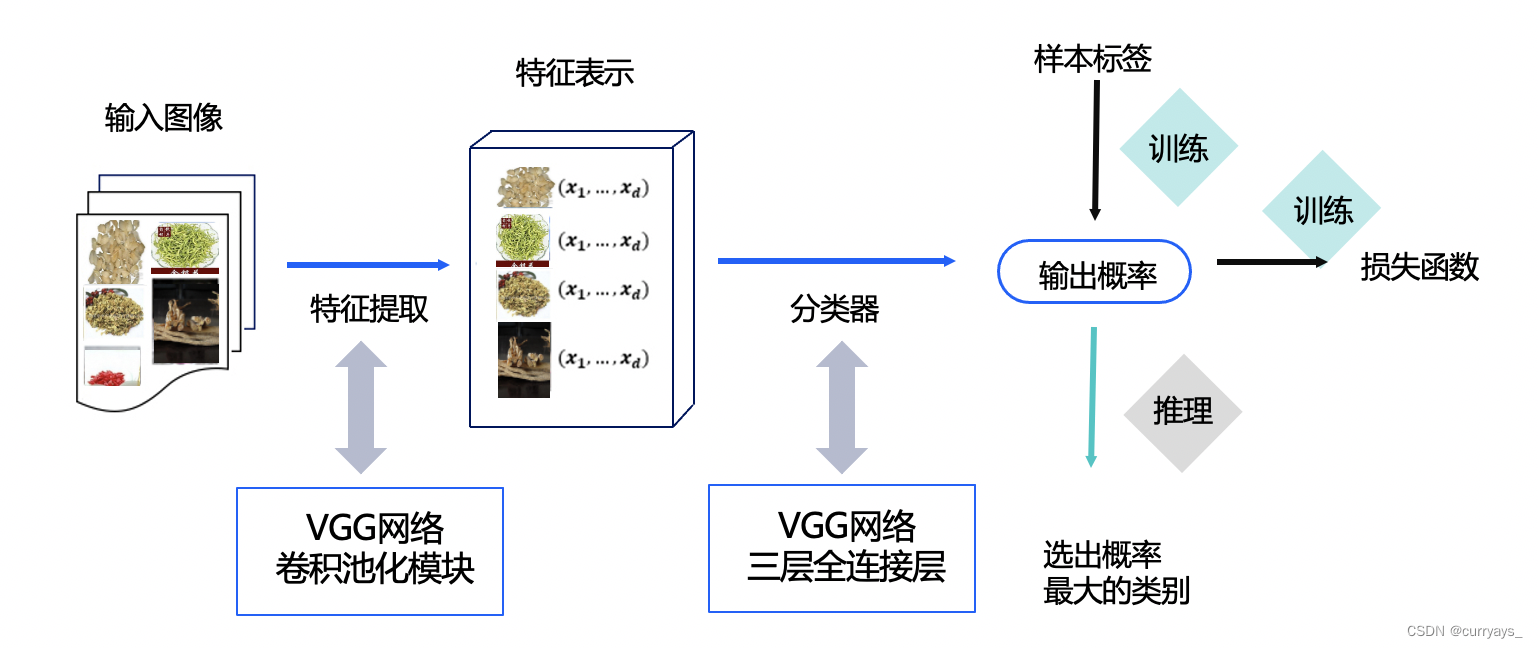
2.数据集介绍
本案例数据集data/data105575/Chinese Medicine.zip来源于互联网,分为5个类别共902张图片,其中百合180张图片,枸杞185张图片,金银花180张图片,槐花167张图片,党参190张图片
数据集图片如下所示:

2.1 数据集预处理
本案例主要分以下几个步骤进行数据预处理:
(1)解压原始数据集
(2)按照比例划分训练集与验证集
(3)乱序,生成数据列表
(4)定义数据读取器,转换图片
首先我们引入本案例需要的所有模块
# 引入需要的模块
import os
import zipfile
import random
import json
import paddle
import sys
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from paddle.io import Dataset
random.seed(200)接下来我们正式开始数据集的预处理,第一步我们使用zipfile模块来解压原始数据集,将src_path路径下的zip包解压至target_path目录下
def unzip_data(src_path,target_path):
if(not os.path.isdir(target_path + "Chinese Medicine")):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()第二步我们按照7:1的比例划分训练集与验证集,之后打乱数据集的顺序并生成数据列表
def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
#存放所有类别的信息
class_detail = []
#获取所有类别保存的文件夹名称
data_list_path=target_path+"Chinese Medicine/"
class_dirs = os.listdir(data_list_path)
#总的图像数量
all_class_images = 0
#存放类别标签
class_label=0
#存放类别数目
class_dim = 0
#存储要写进eval.txt和train.txt中的内容
trainer_list=[]
eval_list=[]
#读取每个类别,['baihe', 'gouqi','jinyinhua','huaihua','dangshen']
for class_dir in class_dirs:
if class_dir != ".DS_Store":
class_dim += 1
#每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
#统计每个类别有多少张图片
class_sum = 0
#获取类别路径
path = data_list_path + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths: # 遍历文件夹下的每个图片
name_path = path + '/' + img_path # 每张图片的路径
if class_sum % 8 == 0: # 每8张图片取一个做验证数据
eval_sum += 1 # test_sum为测试数据的数目
eval_list.append(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目
class_sum += 1 #每类图片的数目
all_class_images += 1 #所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir #类别名称
class_detail_list['class_label'] = class_label #类别标签
class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
class_detail.append(class_detail_list)
#初始化标签列表
train_parameters['label_dict'][str(class_label)] = class_dir
class_label += 1
#初始化分类数
train_parameters['class_dim'] = class_dim
#乱序
random.shuffle(eval_list)
with open(eval_list_path, 'a') as f:
for eval_image in eval_list:
f.write(eval_image)
random.shuffle(trainer_list)
with open(train_list_path, 'a') as f2:
for train_image in trainer_list:
f2.write(train_image)
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2203
2203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









