







写这个玩意,我也是深深地感觉到自己数据结构的薄弱,可笑的是我一直以为学的还可以,结果一个堆结构就干了我半个月,才懂个大概= =,我也是醉了
BinaryTree.h二叉树的实现
/**
* 书本:《算法分析与设计》
* 功能:这个头文件是为了实现二叉树
* 文件:BinaryTree.h
* 时间:2014年12月15日18:35:51
* 作者:cutter_point
*/
// _ooOoo_
// o8888888o
// 88" . "88
// (| -_- |)
// O\ = /O
// ____/`---'\____
// . ' \\| |// `.
// / \\||| : |||// \
// / _||||| -:- |||||- \
// | | \\\ - /// | |
// | \_| ''\---/'' | |
// \ .-\__ `-` ___/-. /
// ___`. .' /--.--\ `. . __
// ."" '< `.___\_<|>_/___.' >'"".
// | | : `- \`.;`\ _ /`;.`/ - ` : | |
// \ \ `-. \_ __\ /__ _/ .-` / /
// ======`-.____`-.___\_____/___.-`____.-'======
// `=---='
//
// .............................................
// 佛祖镇楼 BUG辟易
// 佛曰:
// 写字楼里写字间,写字间里程序员;
// 程序人员写程序,又拿程序换酒钱。
// 酒醒只在网上坐,酒醉还来网下眠;
// 酒醉酒醒日复日,网上网下年复年。
// 但愿老死电脑间,不愿鞠躬老板前;
// 奔驰宝马贵者趣,公交自行程序员。
// 别人笑我忒疯癫,我笑自己命太贱;
// 不见满街漂亮妹,哪个归得程序员?
#include <iostream>
using namespace std;
template<class T>
struct BTNode
{
T data; //这个是二叉树的根节点的值
BTNode<T> *lChild, *rChild; //分别是左右孩子
BTNode() //构造函数
{
lChild = rChild = nullptr; //初始化为空
}
//构造函数二号
BTNode(const T &val, BTNode<T> *Childl = nullptr, BTNode<T> *Childr = nullptr)
{
//这个也是对当前这个二叉树进行初始化
data = val;
lChild = Childl;
rChild = Childr;
}
//把对应的一颗二叉树拷贝出去,这个拷贝不是说的那种只有做孩子和右孩子一个数的树,而是拷贝一堆过来
//这个是吧这个二叉树创建一个新的内存空间,存一样的东西,并返回这个新的树,内容一样
BTNode<T>* CopyTree()
{
BTNode<T> *nl, *nr, *nn; //对这个进行拷贝
if (&data == NULL)
return NULL; //当前对应的树为空
nl = lChild->CopyTree(); //把左边拷贝过来
nr = rChild->CopyTree(); //把右边拷贝过来
nn = new BTNode<T>(data, nl, nr); //创建这个二叉树
return nn;
}
};
//二叉树的对象类
template<class T>
class BinaryTree
{
void Destroy(BTNode<T> *&r); //这个是为了摧毁二叉树
void PreOrder(BTNode<T> *r);
void InOrder(BTNode<T> *r);
void PostOrder(BTNode<T> *r);
int Height(const BTNode<T> *r) const;
int NodeCount(const BTNode<T> *r) const;
public:
BTNode<T> *root; //根节点
BinaryTree(); //构造函数
~BinaryTree(); //析构函数
void Pre_Order();
void In_Order();
void Post_Order();
int TreeHeight() const;
int TreeNodeCount() const;
void DestroyTree();
void MakeTree(T pData, BinaryTree<T> leftTree, BinaryTree<T> rightTree);
void Change(BTNode<T> *r);
};
//对应的类的实现
template<class T>
BinaryTree<T>::BinaryTree()
{
root = NULL;
}
template<class T>
BinaryTree<T>::~BinaryTree()
{}
template<class T>
void BinaryTree<T>::Pre_Order()
{
PreOrder(root);
}
template<class T>
void BinaryTree<T>::In_Order()
{
InOrder(root);
}
template<class T>
void BinaryTree<T>::Post_Order()
{
PostOrder(root);
}
template<class T>
int BinaryTree<T>::TreeHeight() const
{
return Height(root);
}
template<class T>
int BinaryTree<T>::TreeNodeCount()const
{
return NodeCount(root);
}
template<class T>
void BinaryTree<T>::DestroyTree()
{
Destroy(root);
}
template<class T>
void BinaryTree<T>::PreOrder(BTNode<T> *r) //遍历输出这个树的全部数据,先根左右的顺序
{ //根左右
if (r != NULL)
{
cout << r->data << ' ';
PreOrder(r->lChild); //递归调用
PreOrder(r->rChild);
}
}
template<class T>
void BinaryTree<T>::InOrder(BTNode<T> *r) //这个是遍历顺序是先左边然后根然后右边
{ //左中右
if (r != NULL)
{
InOrder(r->lChild);
cout << r->data << ' ';
InOrder(r->rChild);
}
}
template<class T>
void BinaryTree<T>::PostOrder(BTNode<T> *r) //这个是先左然后右边最后才是根
{ //左右中
if (r != NULL)
{
PostOrder(r->lChild);
PostOrder(r->rChild);
cout << r->data << ' ';
}
}
//这个是统计有多少个节点
template<class T>
int BinaryTree<T>::NodeCount(const BTNode<T> *r) const
{
if (r == NULL)
return 0; //这个没有节点
else
return 1 + NodeCount(r->lChild) + NodeCount(r->rChild); //当前的这个节点+左边的节点+右边的节点
}
//这个是将二叉树的所有节点进行交换,注意这里是所有,不是单一的几个
template<class T> //还是老套路,先把根交换了,然后到他们的子节点里面在进行左右交换
void BinaryTree<T>::Change(BTNode<T> *r)
{
BTNode<T> *p; //这个是用来交换的中间变量
if (r)
{
p = r->lChild;
r->lChild = r->rChild; //右边的节点放到左边来
r->rChild = p; //左边的放到右边的位置
Change(r->lChild); //在交换左边子树上的所有节点
Change(r->rChild); //交换右边子树上的所有节点
}
}
//这个释放子树空间要一个一个地释放
template<class T>
void BinaryTree<T>::Destroy(BTNode<T> *&r) //这里是用了一个引用指针,有点不懂
{
if (r != NULL)
{
Destroy(r->lChild); //先把左边的节点给释放空间
Destroy(r->rChild); //然后释放右边的所有节点
delete r; //把根节点也释放掉
r = nullptr; //设置为空
}
}
//把二叉树最长的那个边有多少个节点
template<class T>
int BinaryTree<T>::Height(const BTNode<T> *r) const
{
if (r != nullptr)
return 0; //没有子树
else
{
int lh, rh; //左右两边的长度
lh = Height(r->lChild);
rh = Height(r->rChild);
//左右两边选长的那个
return 1 + (lh > rh ? lh : rh); //最长的那个节点加上来
}
}
//创建一个新的二叉树,这个二叉树包含了leftTree和rightTree
template<class T>
void BinaryTree<T>::MakeTree(T pData, BinaryTree<T> leftTree, BinaryTree<T> rightTree) //这里左右两个子树不是指针了
{
root = new BTNode<T>();
root->data = pData;
root->lChild = leftTree.root;
root->rChild = rightTree.root;
//注意这个参数不是指针的话,那么新的子树构建出来的和那两个参数是完全没关系的,大不了就是数值一样
}
最小堆实现MinHeap.h
/**
* 书本:《算法分析与设计》
* 功能:这个头文件是为了实现二叉树
* 文件:BinaryTree.h
* 时间:2014年12月15日18:35:51
* 作者:cutter_point
*/
// _ooOoo_
// o8888888o
// 88" . "88
// (| -_- |)
// O\ = /O
// ____/`---'\____
// . ' \\| |// `.
// / \\||| : |||// \
// / _||||| -:- |||||- \
// | | \\\ - /// | |
// | \_| ''\---/'' | |
// \ .-\__ `-` ___/-. /
// ___`. .' /--.--\ `. . __
// ."" '< `.___\_<|>_/___.' >'"".
// | | : `- \`.;`\ _ /`;.`/ - ` : | |
// \ \ `-. \_ __\ /__ _/ .-` / /
// ======`-.____`-.___\_____/___.-`____.-'======
// `=---='
//
// .............................................
// 佛祖镇楼 BUG辟易
// 佛曰:
// 写字楼里写字间,写字间里程序员;
// 程序人员写程序,又拿程序换酒钱。
// 酒醒只在网上坐,酒醉还来网下眠;
// 酒醉酒醒日复日,网上网下年复年。
// 但愿老死电脑间,不愿鞠躬老板前;
// 奔驰宝马贵者趣,公交自行程序员。
// 别人笑我忒疯癫,我笑自己命太贱;
// 不见满街漂亮妹,哪个归得程序员?
#include <iostream>
using namespace std;
/*
如果只是找最小值,最起码是O(n),因为至少每个元素要遍历一遍,这点最小堆不占优势
最小堆的优点在于它的动态可维护性。如果是数组,当数组某个元素发生变化时(增加、删除或修改),
你是没法知道最小值会怎么变化(其它还好,如果把已知的最小值删去,如果还想找到最小值,还需要重新扫描数组。当然你会想到数组如果有序呢?
不过你要随时维护数组保证数组有序,这在插入数据时还需要O(N)复杂度。)相比之下,最小堆只需要O(logN)的复杂度,是不是很牛逼(最先设计出这个数据结构的人,
真的很牛逼啊)。此外,最小堆(好像是最大堆,算了,反正两个是一回事)还可以当做一个优先队列(就是按重要程度排个队,每次都考虑队首元素,
有人插队也没事,O(logN)就行了),这应该是它最常见的应用了
*/
//这个就是用来存放所有的数据的堆
template<class T>
class MinHeap //最小堆就是节点比子节点小的二叉树,最大堆就是节点比子节点大的二叉树
{
T *heap; //元素数组,0号位置也储存元素
int CurrentSize; //目前元素个数
int MaxSize; //可容纳的最多元素个数
void FilterDown(const int start, const int end); //自上往下调整,使关键字小的节点在上
void FilterUp(int start); //自下往上调整
public:
MinHeap(int n = 1000); //构造函数
~MinHeap();
bool Insert(const T &x); //插入数据
T RemoveMin(); //删除最小的元素
T GetMin(); //取得最小的元素
bool IsEmpty() const; //判断是否为空
bool IsFull() const; //是否满了
void Clear(); //清空
void look(); //查看所有元素
};
template<class T>
void MinHeap<T>::look()
{
for (int i = 0; i < MaxSize; ++i)
cout << heap[i] << endl;
}
//void FilterDown(const int start, const int end); //自上往下调整,使关键字小的节点在上
template<class T>
void MinHeap<T>::FilterDown(const int start, const int end)
{
int i = start, j = 2 * i + 1; //i表示数据的开始
T temp = heap[i]; //temp表示i当前指向
while (j <= end) //只要j没有到达尾部
{
if ((j < end) && (heap[j] > heap[j + 1])) //只要j还在最后一个的前面,并且第j个数大于后面那个数
{
++j; //那就直接把j进入下一个
}//if
if (temp <= heap[j])
break; //如果这个i指向的值比j指向的值还要小,那就不管
else
{//如果temp比j指向的要大,就是前面的比较大,并且这个j比后面的小,就是中间的j是最小的,在这个三个数中
heap[i] = heap[j];
i = j;
j = 2 * j + 1;
}// esle
}//while
heap[i] = temp; //把i的值刷新,这个是根元素
}//void MinHeap<T>::FilterDown(const int start, const int end)
//void FilterUp(int start); //自下往上调整
template<class T>
void MinHeap<T>::FilterUp(int start)
{
int j = start, i = (j - 1) / 2; //i指向j的父节点
T temp = heap[j];
while (j > 0)
{
if (heap[i] <= temp)
break;
else
{
heap[j] = heap[i];
j = i;
i = (i - 1) / 2;
}//else
}//while
heap[j] = temp;
}//void MinHeap<T>::FilterUp(int start)
//构造函数的实现
template<class T>
MinHeap<T>::MinHeap(int n)
{
MaxSize = n; //可容纳的最多的元素个数
heap = new T[MaxSize]; //创建类型T的节点有MaxSize个
CurrentSize = 0; //暂时还没有一个元素
}
//析构函数
template<class T>
MinHeap<T>::~MinHeap()
{
//回收所有的控件
delete []heap;
}
//插入数据
template<class T>
bool MinHeap<T>::Insert(const T &x)
{
if (CurrentSize == MaxSize) //如果元素已经全部填满了
return false; //返回无法插入
heap[CurrentSize] = x; //把x赋值给当前的位置,则有0到CurrentSize个元素即CurrentSize+1个元素
FilterUp(CurrentSize); //把元素进行插入排序
CurrentSize++;
return true; //插入成功
}
//T RemoveMin(); 删除最小的元素
template<class T>
T MinHeap<T>::RemoveMin()
{
T x = heap[0];
heap[0] = heap[CurrentSize - 1]; //把最后一个元素赋值给第一个元素
CurrentSize--; //删除掉一个元素后,个数减一
FilterDown(0, CurrentSize - 1); //调整新的根节点
return x; //把移除的元素返回
}
//T GetMin(); //取得最小的元素
template<class T>
T MinHeap<T>::GetMin()
{
return heap[0];
}
//bool IsEmpty() const; //判断是否为空
template<class T>
bool MinHeap<T>::IsEmpty() const
{
return CurrentSize == 0; //返回为真那么就是没有元素是空
}
//bool IsFull() const; //是否满了
template<class T>
bool MinHeap<T>::IsFull() const
{
return CurrentSize == MaxSize;
}
//void Clear(); //清空
template<class T>
void MinHeap<T>::Clear()
{
CurrentSize = 0; //直接重头开始覆盖数据
}
/**
* <p>我tm终于练成了!Hello World终于打印出来了! %>_<% 我先哭(激动)会~~~<p>
* @version 1.0.1
* @since JDK 1.6
* @author jacksen
*
*/
// 致终于来到这里的勇敢的人:
// 你是被上帝选中的人,英勇的、不辞劳苦的、不眠不休的来修改
// 我们这最棘手的代码的编程骑士。你,我们的救世主,人中龙凤,
// 我要对你说:永远不要放弃;永远不要对自己失望;永远不要逃走,辜负自己。
// 永远不要哭啼,永远不要说再见。永远不要说谎来伤害自己。
// 致终于来到这里的勇敢的人:
// 你是被上帝选中的人,英勇的、不辞劳苦的、不眠不休的来修改
// 我们这最棘手的代码的编程骑士。你,我们的救世主,人中龙凤,
// 我要对你说:永远不要放弃;永远不要对自己失望;永远不要逃走,辜负自己。
// 永远不要哭啼,永远不要说再见。永远不要说谎来伤害自己。
// 致终于来到这里的勇敢的人:
// 你是被上帝选中的人,英勇的、不辞劳苦的、不眠不休的来修改
// 我们这最棘手的代码的编程骑士。你,我们的救世主,人中龙凤,
// 我要对你说:永远不要放弃;永远不要对自己失望;永远不要逃走,辜负自己。
// 永远不要哭啼,永远不要说再见。永远不要说谎来伤害自己。
//頂頂頂頂頂頂頂頂頂 頂頂頂頂頂頂頂頂頂
//頂頂頂頂頂頂頂 頂頂
// 頂頂 頂頂頂頂頂頂頂頂頂頂頂
// 頂頂 頂頂頂頂頂頂頂頂頂頂頂
// 頂頂 頂頂 頂頂
// 頂頂 頂頂 頂頂頂 頂頂
// 頂頂 頂頂 頂頂頂 頂頂
// 頂頂 頂頂 頂頂頂 頂頂
// 頂頂 頂頂 頂頂頂 頂頂
// 頂頂 頂頂頂
// 頂頂 頂頂 頂頂 頂頂
// 頂頂頂頂 頂頂頂頂頂 頂頂頂頂頂
// 頂頂頂頂 頂頂頂頂 頂頂頂頂
/*code is far away from bug with the animal protecting
* ┏┓ ┏┓
*┏┛┻━━━┛┻┓
*┃ ┃
*┃ ━ ┃
*┃ ┳┛ ┗┳ ┃
*┃ ┃
*┃ ┻ ┃
*┃ ┃
*┗━┓ ┏━┛
* ┃ ┃神兽保佑
* ┃ ┃代码无BUG!
* ┃ ┗━━━┓
* ┃ ┣┓
* ┃ ┏┛
* ┗┓┓┏━┳┓┏┛
* ┃┫┫ ┃┫┫
* ┗┻┛ ┗┻┛
*
*/
/**
*
*----------Dragon be here!----------/
┏┓ ┏┓
┏┛┻━━━┛┻┓
┃ ┃
┃ ━ ┃
┃ ┳┛ ┗┳ ┃
┃ ┃
┃ ┻ ┃
┃ ┃
┗━┓ ┏━┛
┃ ┃
┃ ┃
┃ ┗━━━┓
┃ ┣┓
┃ ┏┛
┗┓┓┏━┳┓┏┛
┃┫┫ ┃┫┫
┗┻┛ ┗┻┛
━━━━━━神兽出没━━━━━━ */
/**
┏┓ ┏┓
┏┛┻━━━┛┻┓
┃ ┃
┃ ━ ┃
┃ > < ┃
┃ ┃
┃... ⌒ ... ┃
┃ ┃
┗━┓ ┏━┛
┃ ┃ Code is far away from bug with the animal protecting
┃ ┃ 神兽保佑,代码无bug
┃ ┃
┃ ┃
┃ ┃
┃ ┃
┃ ┗━━━┓
┃ ┣┓
┃ ┏┛
┗┓┓┏━┳┓┏┛
┃┫┫ ┃┫┫
┗┻┛ ┗┻┛ */
/**
* ┏┓ ┏┓+ +
* ┏┛┻━━━┛┻┓ + +
* ┃ ┃
* ┃ ━ ┃ ++ + + +
* ████━████ ┃+
* ┃ ┃ +
* ┃ ┻ ┃
* ┃ ┃ + +
* ┗━┓ ┏━┛
* ┃ ┃
* ┃ ┃ + + + +
* ┃ ┃ Code is far away from bug with the animal protecting
* ┃ ┃ + 神兽保佑,代码无bug
* ┃ ┃
* ┃ ┃ +
* ┃ ┗━━━┓ + +
* ┃ ┣┓
* ┃ ┏┛
* ┗┓┓┏━┳┓┏┛ + + + +
* ┃┫┫ ┃┫┫
* ┗┻┛ ┗┻┛+ + + +
*/
//1只羊 == one sheep
//2只羊 == two sheeps
//3只羊 == three sheeps
//4只羊 == four sheeps
//5只羊 == five sheeps
//6只羊 == six sheeps
//7只羊 == seven sheeps
//8只羊 == eight sheeps
//9只羊 == nine sheeps
//10只羊 == ten sheeps
//11只羊 == eleven sheeps
//12只羊 == twelve sheeps
//13只羊 == thirteen sheeps
//14只羊 == fourteen sheeps
//15只羊 == fifteen sheeps
//16只羊 == sixteen sheeps
//17只羊 == seventeen sheeps
//18只羊 == eighteen sheeps
//19只羊 == nineteen sheeps
//20只羊 == twenty sheeps
//21只羊 == twenty one sheeps
//22只羊 == twenty two sheeps
//23只羊 == twenty three sheeps
//24只羊 == twenty four sheeps
//25只羊 == twenty five sheeps
//26只羊 == twenty six sheeps
//27只羊 == twenty seven sheeps
//28只羊 == twenty eight sheeps
//29只羊 == twenty nine sheeps
//30只羊 == thirty sheeps
//现在瞌睡了吧,好了,不要再改下面的代码了,睡觉咯~~
/**
* 出生
* ||
* ||
* \ /
* \/
* 青年
* (年龄 = rand(20,25))) 《==============
* || ||
* || ||
* || 祝福所有开发工作者 ||
* || 永远年轻 ||
* || ||
* \ / ||
* \/ ||
*( 20 <= 年龄 <= 25) ===============
* ||
* ||
* \ /
* \/
* 等死状态
*/
huffman.cpp
主函数,这里有点友元方面的问题,暂时没想到好办法
/**
* 书本:《算法分析与设计》
* 功能:实现哈弗曼编码
* 文件:huffman.cpp
* 时间:2015年1月3日17:52:30
* 作者:cutter_point
*/
#include "BinaryTree.h"
#include "MinHeap.h"
#include <iostream>
using namespace std;
template<class T>
class Huffman; //先声明Huffman类
template<class T>
BinaryTree<int> HuffmanTree(T f[], int n); //这是声明一个全局的哈弗曼树函数
template<class T>
class Huffman
{
friend BinaryTree<int> HuffmanTree(T [], int); //友元函数
public:
//操作符重载
operator T() const { return weight; }
/*private:*/ //这里搞个私有就出问题,不知道是编译器问题,还是我代码有错,我是检测半天,认为编译器抽风了= =
BinaryTree<int> tree; //哈弗曼结构是由一个二叉树和权值组成
T weight;
};
//算法HuffmanTree
template<class T> //建立要进行编码的二叉树
BinaryTree<int> HuffmanTree(T f[], int n) //这个分别是所有的数,和数的个数
{
//首先生成一个单节点树
Huffman<T> *w = new Huffman<T>[n + 1];
//生成2个空的二叉树
BinaryTree<int> z, zero;
for (int i = 1; i <= n; ++i)
{
z.MakeTree(i, zero, zero); //制作一个空额二叉树, 开始的序号就是i
w[i].weight = f[i]; //把权值赋值给相应的节点
w[i].tree = z; //把这个空的树作为初始赋值给他
}
//建立最小堆,就是优先合并最小的
MinHeap<Huffman<T> > Q(n); //构造函数,创建空间为n的最小堆
//把数据插入到堆中
for (int i = 1; i <= n; ++i) //从1开始的!!!!!
Q.Insert(w[i]);
//反复合并最小概率树
Huffman<T> x, y; //存放当前最小的
for (int i = 1; i < n; ++i) //每次合并最小的两个,直到只剩下一个树
{
x = Q.RemoveMin();
y = Q.RemoveMin();
//以这两个树为子节点,建立新的树
z.MakeTree(0, x.tree, y.tree); //新的节点没有序号,或者可以在后面加序号
//z.MakeTree(n + i, x.tree, y.tree); //把x和y里面的二叉树拿出来重新构建
//把合并的结果给一个节点放回到最小堆中
x.weight += y.weight; //两种权值和
x.tree = z;
Q.Insert(x);
}
//得到最终的二叉树
x = Q.RemoveMin(); //并把堆中的数据清空
//回收创建的Huffman结构数组
delete[] w;
return x.tree; //返回合并完成的二叉树
}
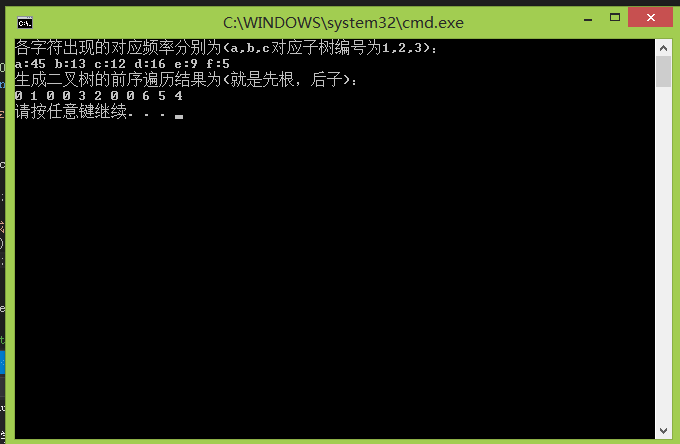
int main()
{
char c[] = { '0', 'a', 'b', 'c', 'd', 'e', 'f' };
int f[] = { 0, 45, 13, 12, 16, 9, 5 };//下标从1开始, 注意56行
BinaryTree<int> t = HuffmanTree(f, 6); //6个数,把他们编码排序,合并成二叉树
cout << "各字符出现的对应频率分别为(a,b,c对应子树编号为1,2,3):" << endl;
for (int i = 1; i <= 6; i++)
{
cout << c[i] << ":" << f[i] << " ";
}
cout << endl;
cout << "生成二叉树的前序遍历结果为(就是先根,后子):" << endl;
t.Pre_Order(); //这个是先根遍历
cout << endl;
//回收空间
t.DestroyTree();
//MinHeap<int> k(7);
//k.Insert(45);
//k.Insert(13);
//k.Insert(0);
//cout << k.GetMin() << endl;
//k.look();
/*int *p, p1, x, y;
p1 = 1;
p = &p1;
x = *p;
p1 = 3;
y = *p;
cout << x << "------" << y << endl;*/
return 0;
}截图
总结
哈哈,这个程序时间跨度长达一年哦 ,哦上面那个遍历结果有点瑕疵,就是输出的不是结果而是节点的编号,0代表后来新合并的节点,其实我觉得输出权值会好一点,也就是在这个的下面再输出权值,不过代码写的时候没想那么多,要是加上这个又得麻烦= =,说一下思路吧,就是把那个返回值不是返回tree,而是返回一个Huffman结构的整体二叉树,这样遍历的时候可以随带输出weight,而且这样做的话,那么在BinaryTree.h头文件里面就不能用那个函数来遍历了,得重新写个函数对Huffman进行遍历,所以说我就不那么搞了
,哦上面那个遍历结果有点瑕疵,就是输出的不是结果而是节点的编号,0代表后来新合并的节点,其实我觉得输出权值会好一点,也就是在这个的下面再输出权值,不过代码写的时候没想那么多,要是加上这个又得麻烦= =,说一下思路吧,就是把那个返回值不是返回tree,而是返回一个Huffman结构的整体二叉树,这样遍历的时候可以随带输出weight,而且这样做的话,那么在BinaryTree.h头文件里面就不能用那个函数来遍历了,得重新写个函数对Huffman进行遍历,所以说我就不那么搞了















 1842
1842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









