






系列文章目录
文章目录
前言
一、什么是自定义类型
一组不同类型成员(元素)的集合
1.结构体
定义:
struct 结构体名
{
成员变量1;
成员变量...;
成员变量n;
}(变量);
struct StuInfo
{
char name[100];
char ID[100];
int age;
}(变量);注意:>
(变量)可以没有,如果有,那么这变量就是自定义类型的全局变量
初始化:
struct StuInfo stu[100]={{学生1信息一一对应},{学生...信息一一对应},{学生1信息一一对应}};结构体成员访问:
根据结构体变量的类型,结构体的访问分为
(1)结构体变量.成员名
(2)结构体指针变量->成员名
注意:>
如果对结构体指针变量进行解引用,那么他对成员的访问也遵循方法一,*(结构体指针变量)->成员名
内存对齐
在计算结构体大小时,会存在着内存对齐的现象,而这一现象牺牲了内存,但是换来了更快的速度
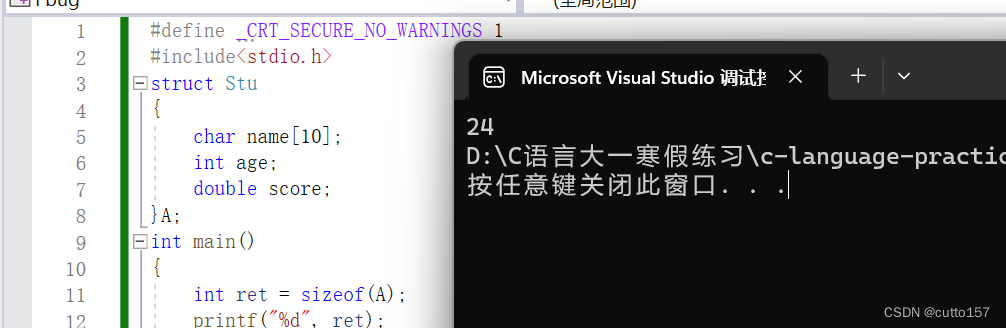
按道理来说,char数组占十个字,int占四个字,double占八个字节,加起来一共22字节,为什么变成了24个字节,内存对齐又是怎么对齐的呢?
1.将首成员放在结构体变量储存位置的0偏移位,
2.第二个成员开始成员存放位置是字节大小与对齐数较小者倍数的偏移量的最小值
3.结构体总大小是结构体所有成员的对齐数最大的那个对齐数的倍数
注意:>
对齐数在VS,gcc平台默认是八个字节,linux平台没有默认对齐数
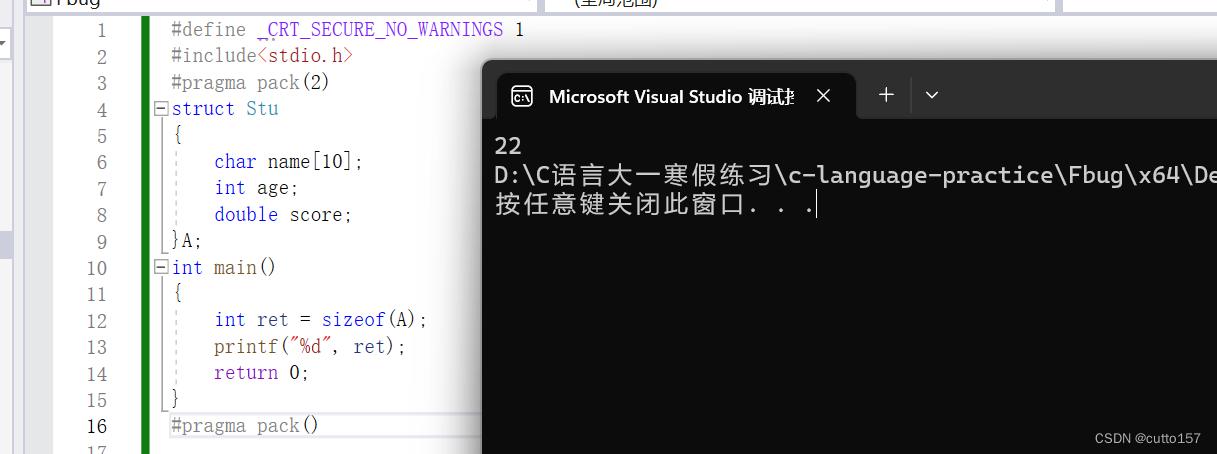
修改默认对齐数
修改默认对齐数需要使用预处理指令
#pragma pack(size) //更改
.
.
.
#pragma pack() //恢复
例如:>
结构体传参
根据传递参数的类型不同分为
(1)结构体值传参
Add(实际参数)
int Add(struct 结构体名 形参名)(2)结构体地址传参
Add(&实际参数)
int Add(struct 结构体名* 形参名)注意:>
结构体地址传参优于结构体值传参
位段
位段的声明和结构体类似,但有以下不同
(1)成员必须是整形,如int,u吗signed int或char类型
(2)成员后面有冒号和数字
例如:>
struct A
{
int _a:2;
int _b:5;
}注意:>
位段冒号后面的数字表示占几个比特(bit)大小的空间
位段的内存分配
(1)只适用于整形字节
(2)按四个字节或一个字节开辟空间,并且连续存放,直到最后一个占用的比特币位超过32个比特,才开辟新空间,所以一个成员大小不能超过32个比特位,因为不能直接开辟一个超过32个比特位的空间
注意:>
位段弥补了结构体浪费空间的缺点,但是不能像结构体一样跨平台是位段的缺点
2.枚举
定义:
//默认
enum sex //enum 枚举名
{
man, //成员1,
woman, //成员2,
alien, //成员...,
};
//man代替0,woman代替1,alien代替2
//初始化
enum sex
{
man=1,
woman,
alien=5,
};
//代表man代替1,woman代替2,alien代替5注意:>
成员名1如果没有赋值,默认值为零,并且从上往下依次增加
优点:
枚举常量优于静define
(1)可读性和可维护性高
(2)有类型检查更严谨
(3)防止命名污染
(4便于调试
(5)更方便 ^-^
3.联合体
定义:
union 联合名
{
成员;
};特点:
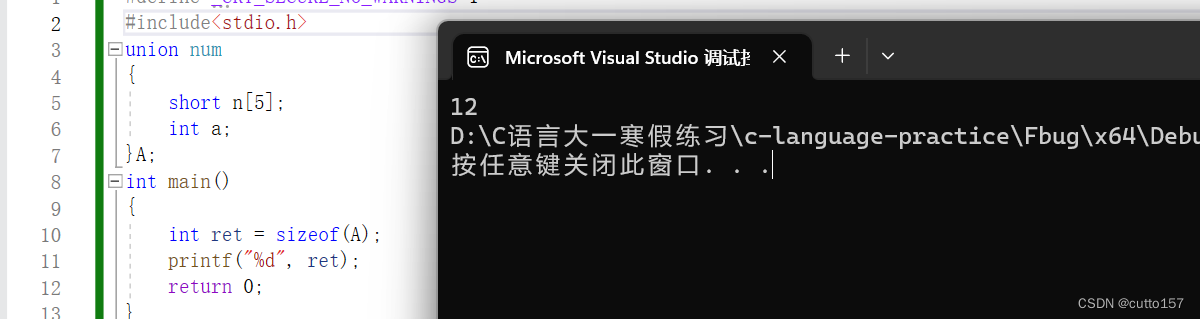
联合体成员共用一个内存空间
大小计算:
(1)联合体的大小至少是最大成员的大小
(2)当最大成员大小不是最大最对齐数的倍数时,自动补齐成倍数
例如:
总结
以上就是对自定义类型的简单介绍















 2855
2855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









