







每天一爬
概要
本文章主要对电影的评论信息进行爬取,包括:用户,评分,评论时间,评论内容等。
一、使用模块
import requests
from pyquery import PyQuery as pq
from pymysql import Connection, MySQLError
二、反爬技术
1.请求头反爬
- user-agent:豆瓣通过用户代理,判断是否是机器人,机器人返回418
- cookie:短时间内,高强度访问豆瓣网,ip将被封锁,需要登陆才能访问
三、分析过程
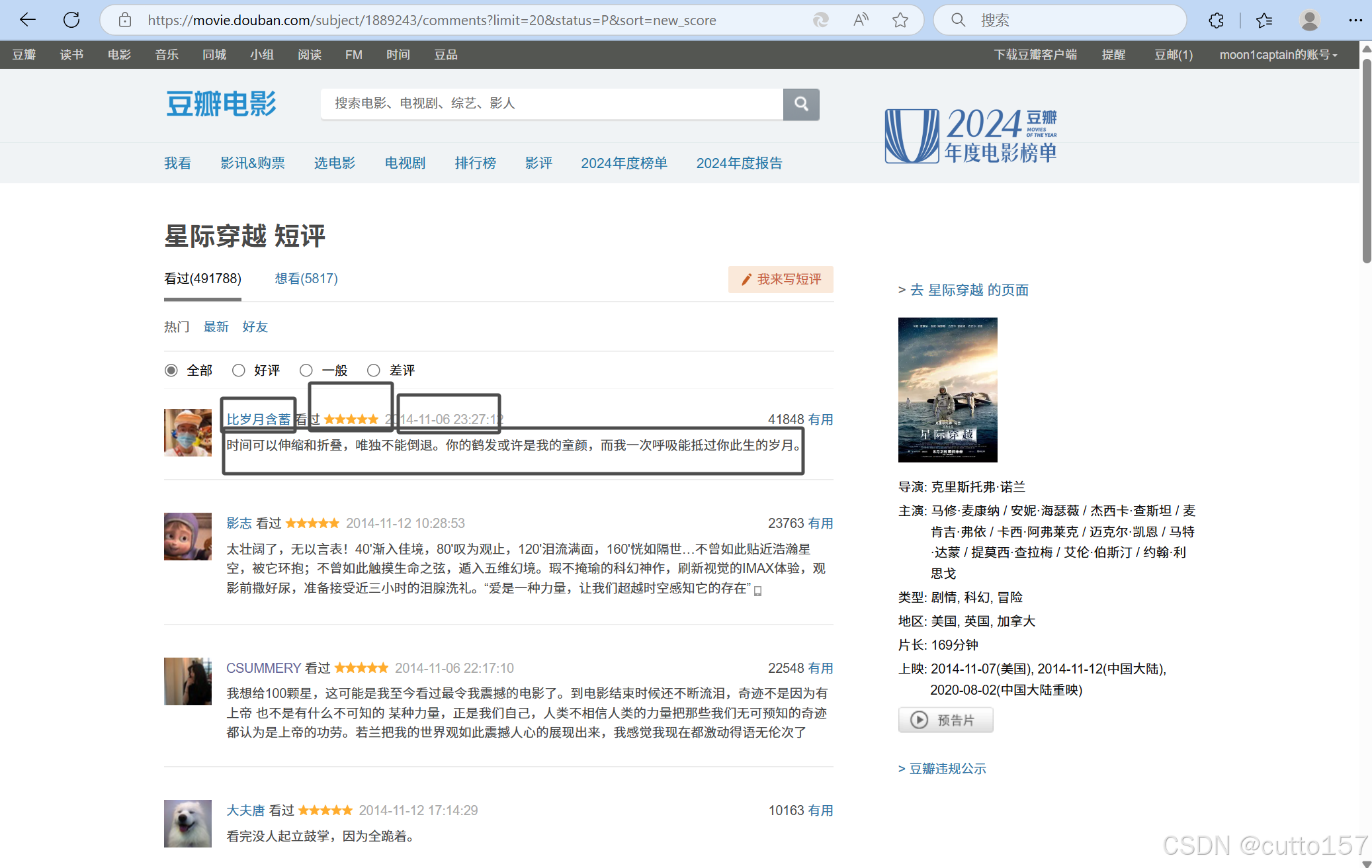
1.观察评论的地址

可以猜到1889243应该是这部电影的ID。
2.数据放在哪里
空白处右键,打开检查面板,选择网络选项卡,复制评论作为搜索关键词,发现评论嵌在html中
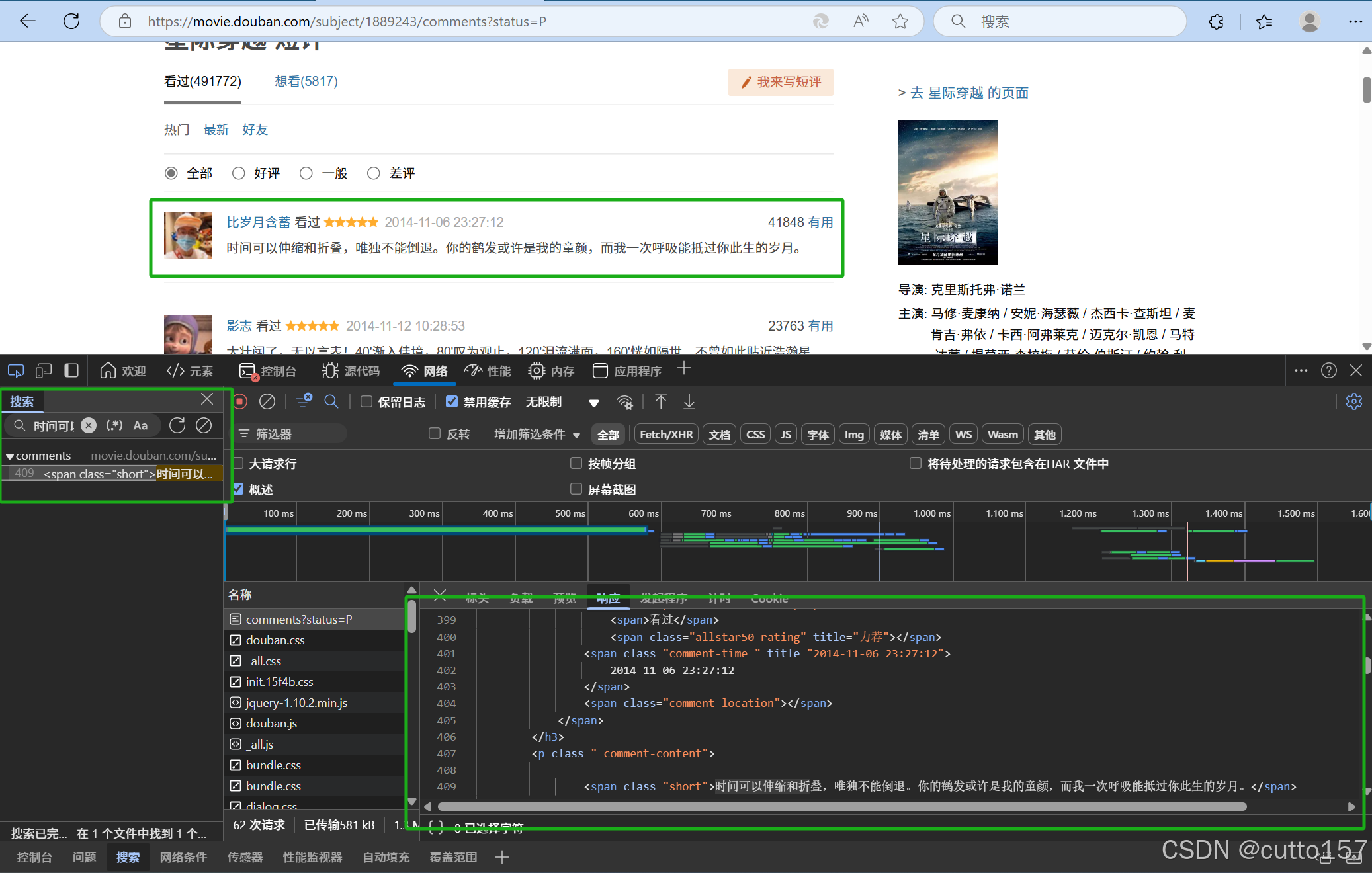
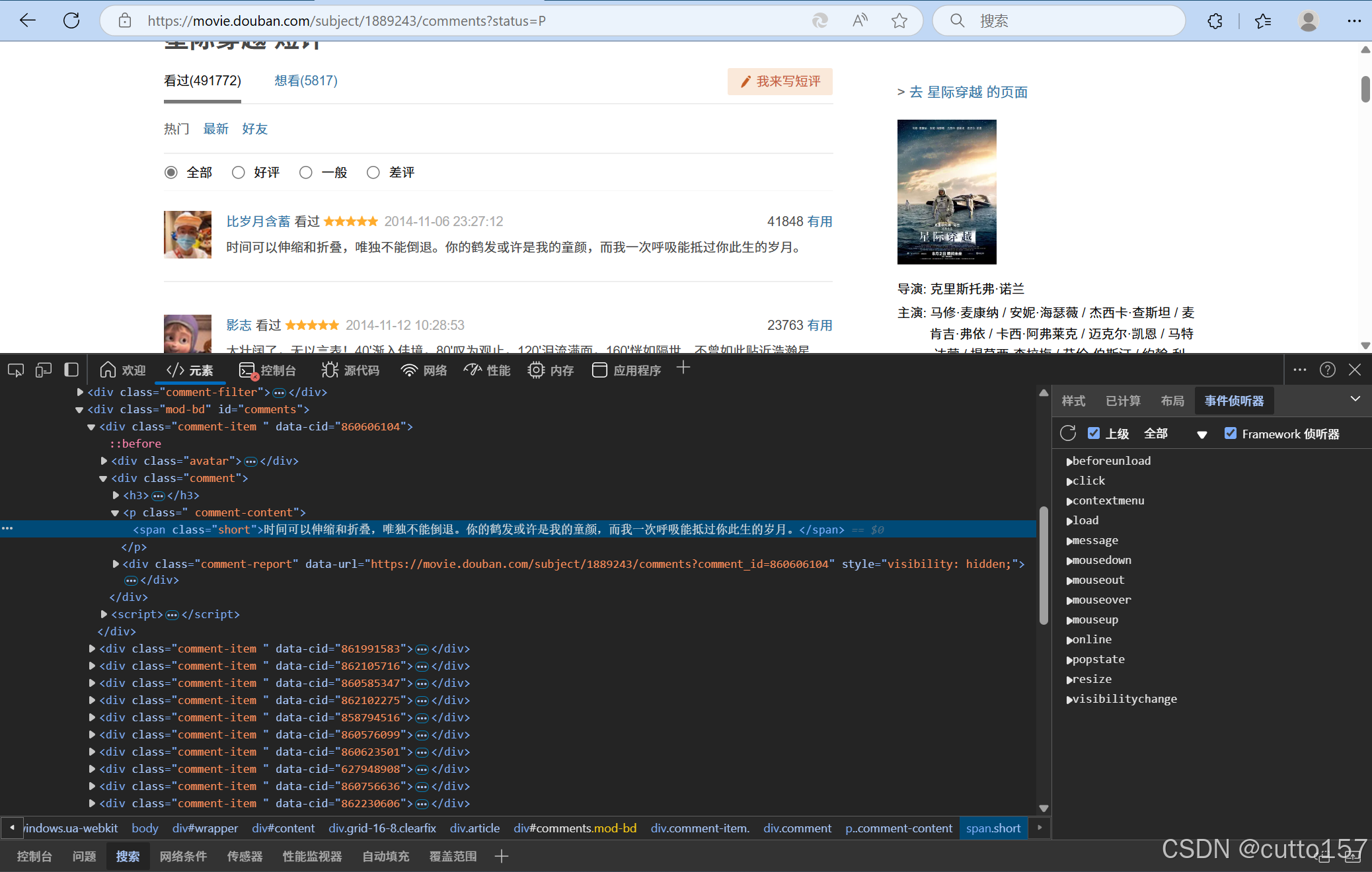
选择元素选项卡,随便定位一条评论,观察数据在html文档中的位置结构
3.其他数据在哪里
点击下一页,发现位置结构发生改变

不难看出来,start=20&limit=20是查询条件,status=P是过滤条件,sort是排序方式。只有不断更新start的值就可以爬取所有数据。
4.怎么判断到尾
方法1:不断手动更新start的值跳转到最后一页,观察与前面页面的不同。发现最后一页的后页的超链接没有href这个属性,可将这个作为爬虫停止条件

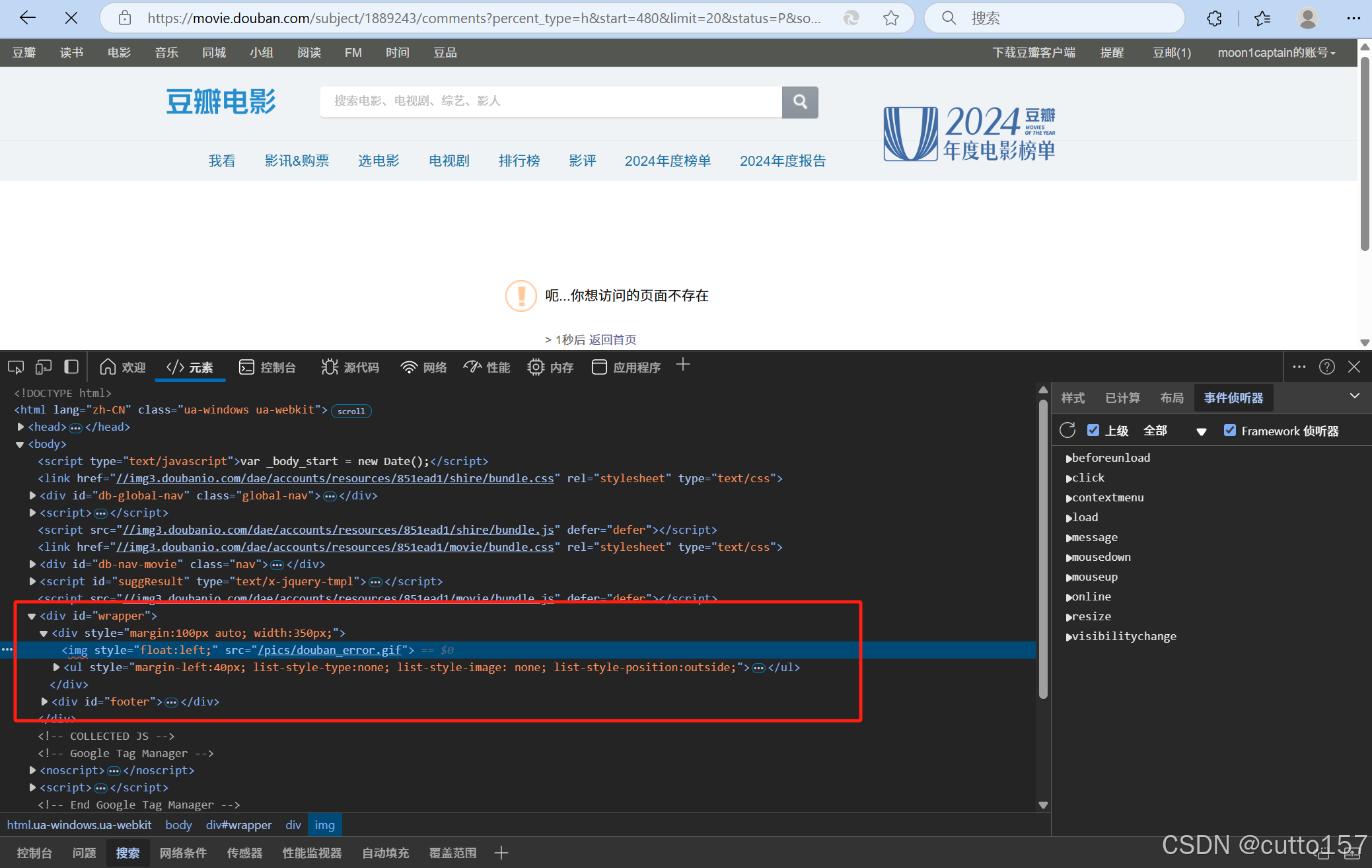
 方法2:直接赋start超出范围值,跳转到豆瓣的错误页面,没有返回数据,也可以作为停止爬虫的条件。
方法2:直接赋start超出范围值,跳转到豆瓣的错误页面,没有返回数据,也可以作为停止爬虫的条件。
四、完整代码
这里展示方法1的代码,方法2代码逻辑与之类似。
import requests
from pyquery import PyQuery as pq
from pymysql import Connection, MySQLError
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36 Edg/133.0.0.0',
'cookie': '你的cookie'
}
movie_id = 1889243
base_url = f'https://movie.douban.com/subject/{movie_id}/comments'
rating_table = {'很差': 1, '较差': 2, '还行': 3, '推荐': 4, '力荐': 5, None: 0}
def insert_comment(cursor, movie_id, comment_id, username, comment, rating, comment_time):
try:
cursor.execute(
"INSERT INTO comments (movie_id, comment_id, username, comment, rating, comment_time) VALUES (%s, %s, %s, %s, %s, %s)",
(movie_id, comment_id, username, comment, rating, comment_time)
)
except MySQLError as e:
print(f"数据库插入错误: {e}")
def fetch_comments(url):
response = requests.get(url, headers=headers)
response.raise_for_status()
return pq(response.text)
if __name__ == '__main__':
with Connection(host='localhost', user='root', password='59420njdM', database='douban') as conn:
cursor = conn.cursor()
url = base_url + '?start=0&limit=20&status=P&sort=new_score'
while True:
doc = fetch_comments(url)
for item in doc('#comments .comment-item').items():
comment_id = item.attr('data-cid')
comment = item.find('.short').text()
username = item.find('.comment-info a').text()
rating = rating_table[item.find('.rating').attr('title')]
comment_time = item.find('.comment-time').text()
print(f'评论ID: {comment_id}, 评论: {comment}, 用户: {username}, 评分: {rating}, 时间: {comment_time}')
insert_comment(cursor, movie_id, comment_id, username, comment, rating, comment_time)
conn.commit() # 提交所有插入操作
next_url = doc.find('.next').attr('href')
if not next_url:
break
url = base_url + next_url
print(f'下一页: {url}')
cursor.close()
小结
这里只对一部电影的评论进行爬取,其余的电影可以结合前面的爬虫,实现爬取更多电影评论

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









